 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADPOT: Medical Anomaly Detection with CLIP Adaptation and Partial Optimal Transport
Jul 09, 2025Medical anomaly detection (AD) is challenging due to diverse imaging modalities, anatomical variations, and limited labeled data. We propose a novel approach combining visual adapters and prompt learning with Partial Optimal Transport (POT) and contrastive learning (CL) to improve CLIP's adaptability to medical images, particularly for AD. Unlike standard prompt learning, which often yields a single representation, our method employs multiple prompts aligned with local features via POT to capture subtle abnormalities. CL further enforces intra-class cohesion and inter-class separation. Our method achieves state-of-the-art results in few-shot, zero-shot, and cross-dataset scenarios without synthetic data or memory banks. The code is available at https://github.com/mahshid1998/MADPOT.
Diffusing DeBias: a Recipe for Turning a Bug into a Feature
Feb 13, 2025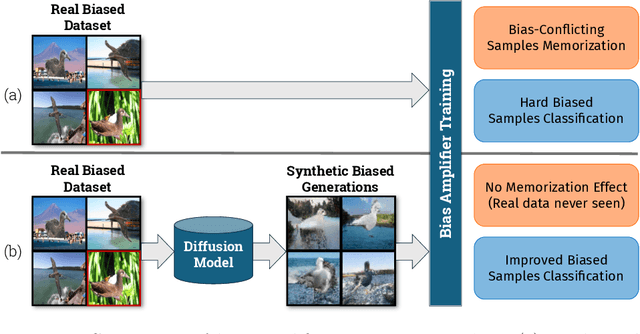
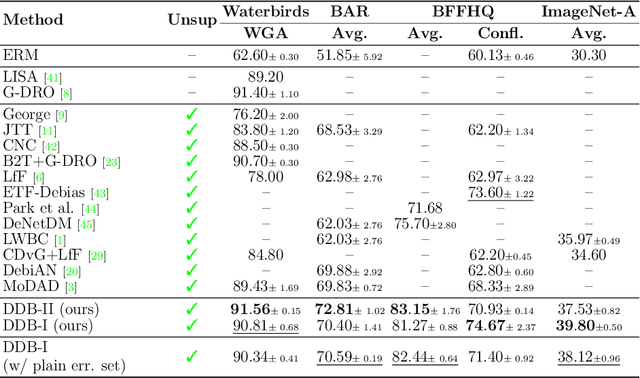
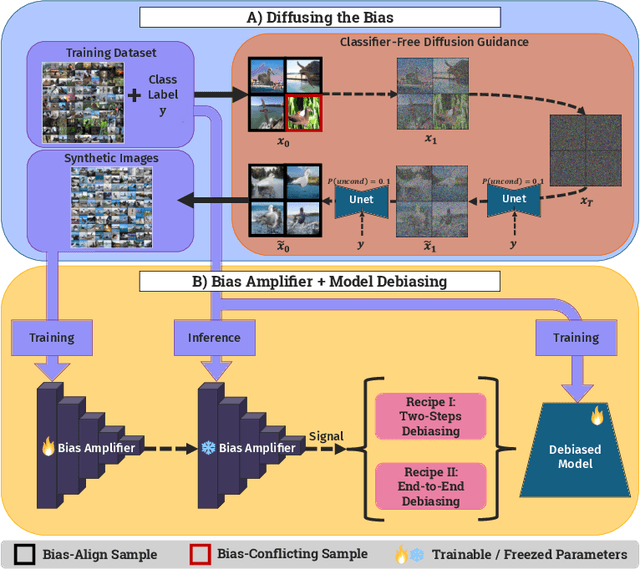

Deep learning model effectiveness in classification tasks is often challenged by the quality and quantity of training data which, whenever containing strong spurious correlations between specific attributes and target labels, can result in unrecoverable biases in model predictions. Tackling these biases is crucial in improving model generalization and trust, especially in real-world scenarios. This paper presents Diffusing DeBias (DDB), a novel approach acting as a plug-in for common methods in model debiasing while exploiting the inherent bias-learning tendency of diffusion models. Our approach leverages conditional diffusion models to generate synthetic bias-aligned images, used to train a bias amplifier model, to be further employed as an auxiliary method in different unsupervised debiasing approaches. Our proposed method, which also tackles the common issue of training set memorization typical of this type of tech- niques, beats current state-of-the-art in multiple benchmark datasets by significant margins, demonstrating its potential as a versatile and effective tool for tackling dataset bias in deep learning applications.
A Mutual Information Perspective on Multiple Latent Variable Generative Models for Positive View Generation
Jan 23, 2025



In image generation, Multiple Latent Variable Generative Models (MLVGMs) employ multiple latent variables to gradually shape the final images, from global characteristics to finer and local details (e.g., StyleGAN, NVAE), emerging as powerful tools for diverse applications. Yet their generative dynamics and latent variable utilization remain only empirically observed. In this work, we propose a novel framework to systematically quantify the impact of each latent variable in MLVGMs, using Mutual Information (MI) as a guiding metric. Our analysis reveals underutilized variables and can guide the use of MLVGMs in downstream applications. With this foundation, we introduce a method for generating synthetic data for Self-Supervised Contrastive Representation Learning (SSCRL). By leveraging the hierarchical and disentangled variables of MLVGMs, and guided by the previous analysis, we apply tailored latent perturbations to produce diverse views for SSCRL, without relying on real data altogether. Additionally, we introduce a Continuous Sampling (CS) strategy, where the generator dynamically creates new samples during SSCRL training, greatly increasing data variability. Our comprehensive experiments demonstrate the effectiveness of these contributions, showing that MLVGMs' generated views compete on par with or even surpass views generated from real data. This work establishes a principled approach to understanding and exploiting MLVGMs, advancing both generative modeling and self-supervised learning.
Pre-trained Multiple Latent Variable Generative Models are good defenders against Adversarial Attacks
Dec 04, 2024



Attackers can deliberately perturb classifiers' input with subtle noise, altering final predictions. Among proposed countermeasures, adversarial purification employs generative networks to preprocess input images, filtering out adversarial noise. In this study, we propose specific generators, defined Multiple Latent Variable Generative Models (MLVGMs), for adversarial purification. These models possess multiple latent variables that naturally disentangle coarse from fine features. Taking advantage of these properties, we autoencode images to maintain class-relevant information, while discarding and re-sampling any detail, including adversarial noise. The procedure is completely training-free, exploring the generalization abilities of pre-trained MLVGMs on the adversarial purification downstream task. Despite the lack of large models, trained on billions of samples, we show that smaller MLVGMs are already competitive with traditional methods, and can be used as foundation models. Official code released at https://github.com/SerezD/gen_adversarial.
Upper-Body Pose-based Gaze Estimation for Privacy-Preserving 3D Gaze Target Detection
Sep 26, 2024



Gaze Target Detection (GTD), i.e., determining where a person is looking within a scene from an external viewpoint, is a challenging task, particularly in 3D space. Existing approaches heavily rely on analyzing the person's appearance, primarily focusing on their face to predict the gaze target. This paper presents a novel approach to tackle this problem by utilizing the person's upper-body pose and available depth maps to extract a 3D gaze direction and employing a multi-stage or an end-to-end pipeline to predict the gazed target. When predicted accurately, the human body pose can provide valuable information about the head pose, which is a good approximation of the gaze direction, as well as the position of the arms and hands, which are linked to the activity the person is performing and the objects they are likely focusing on. Consequently, in addition to performing gaze estimation in 3D, we are also able to perform GTD simultaneously. We demonstrate state-of-the-art results on the most comprehensive publicly accessible 3D gaze target detection dataset without requiring images of the person's face, thus promoting privacy preservation in various application contexts. The code is available at https://github.com/intelligolabs/privacy-gtd-3D.
Say My Name: a Model's Bias Discovery Framework
Aug 18, 2024In the last few years, due to the broad applicability of deep learning to downstream tasks and end-to-end training capabilities, increasingly more concerns about potential biases to specific, non-representative patterns have been raised. Many works focusing on unsupervised debiasing usually leverage the tendency of deep models to learn ``easier'' samples, for example by clustering the latent space to obtain bias pseudo-labels. However, the interpretation of such pseudo-labels is not trivial, especially for a non-expert end user, as it does not provide semantic information about the bias features. To address this issue, we introduce ``Say My Name'' (SaMyNa), the first tool to identify biases within deep models semantically. Unlike existing methods, our approach focuses on biases learned by the model. Our text-based pipeline enhances explainability and supports debiasing efforts: applicable during either training or post-hoc validation, our method can disentangle task-related information and proposes itself as a tool to analyze biases. Evaluation on traditional benchmarks demonstrates its effectiveness in detecting biases and even disclaiming them, showcasing its broad applicability for model diagnosis.
Model Debiasing by Learnable Data Augmentation
Aug 09, 2024



Deep Neural Networks are well known for efficiently fitting training data, yet experiencing poor generalization capabilities whenever some kind of bias dominates over the actual task labels, resulting in models learning "shortcuts". In essence, such models are often prone to learn spurious correlations between data and labels. In this work, we tackle the problem of learning from biased data in the very realistic unsupervised scenario, i.e., when the bias is unknown. This is a much harder task as compared to the supervised case, where auxiliary, bias-related annotations, can be exploited in the learning process. This paper proposes a novel 2-stage learning pipeline featuring a data augmentation strategy able to regularize the training. First, biased/unbiased samples are identified by training over-biased models. Second, such subdivision (typically noisy) is exploited within a data augmentation framework, properly combining the original samples while learning mixing parameters, which has a regularization effect. Experiments on synthetic and realistic biased datasets show state-of-the-art classification accuracy, outperforming competing methods, ultimately proving robust performance on both biased and unbiased examples. Notably, being our training method totally agnostic to the level of bias, it also positively affects performance for any, even apparently unbiased, dataset, thus improving the model generalization regardless of the level of bias (or its absence) in the data.
Looking at Model Debiasing through the Lens of Anomaly Detection
Jul 25, 2024


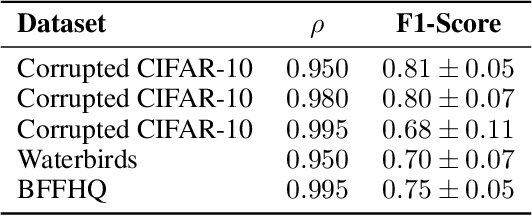
It is widely recognized that deep neural networks are sensitive to bias in the data. This means that during training these models are likely to learn spurious correlations between data and labels, resulting in limited generalization abilities and low performance. In this context, model debiasing approaches can be devised aiming at reducing the model's dependency on such unwanted correlations, either leveraging the knowledge of bias information or not. In this work, we focus on the latter and more realistic scenario, showing the importance of accurately predicting the bias-conflicting and bias-aligned samples to obtain compelling performance in bias mitigation. On this ground, we propose to conceive the problem of model bias from an out-of-distribution perspective, introducing a new bias identification method based on anomaly detection. We claim that when data is mostly biased, bias-conflicting samples can be regarded as outliers with respect to the bias-aligned distribution in the feature space of a biased model, thus allowing for precisely detecting them with an anomaly detection method. Coupling the proposed bias identification approach with bias-conflicting data upsampling and augmentation in a two-step strategy, we reach state-of-the-art performance on synthetic and real benchmark datasets. Ultimately, our proposed approach shows that the data bias issue does not necessarily require complex debiasing methods, given that an accurate bias identification procedure is defined.
Learnable Data Augmentation for One-Shot Unsupervised Domain Adaptation
Oct 03, 2023This paper presents a classification framework based on learnable data augmentation to tackle the One-Shot Unsupervised Domain Adaptation (OS-UDA) problem. OS-UDA is the most challenging setting in Domain Adaptation, as only one single unlabeled target sample is assumed to be available for model adaptation. Driven by such single sample, our method LearnAug-UDA learns how to augment source data, making it perceptually similar to the target. As a result, a classifier trained on such augmented data will generalize well for the target domain. To achieve this, we designed an encoder-decoder architecture that exploits a perceptual loss and style transfer strategies to augment the source data. Our method achieves state-of-the-art performance on two well-known Domain Adaptation benchmarks, DomainNet and VisDA. The project code is available at https://github.com/IIT-PAVIS/LearnAug-UDA
Leveraging Next-Active Objects for Context-Aware Anticipation in Egocentric Videos
Aug 16, 2023



Objects are crucial for understanding human-object interactions. By identifying the relevant objects, one can also predict potential future interactions or actions that may occur with these objects. In this paper, we study the problem of Short-Term Object interaction anticipation (STA) and propose NAOGAT (Next-Active-Object Guided Anticipation Transformer), a multi-modal end-to-end transformer network, that attends to objects in observed frames in order to anticipate the next-active-object (NAO) and, eventually, to guide the model to predict context-aware future actions. The task is challenging since it requires anticipating future action along with the object with which the action occurs and the time after which the interaction will begin, a.k.a. the time to contact (TTC). Compared to existing video modeling architectures for action anticipation, NAOGAT captures the relationship between objects and the global scene context in order to predict detections for the next active object and anticipate relevant future actions given these detections, leveraging the objects' dynamics to improve accuracy. One of the key strengths of our approach, in fact, is its ability to exploit the motion dynamics of objects within a given clip, which is often ignored by other models, and separately decoding the object-centric and motion-centric information. Through our experiments, we show that our model outperforms existing methods on two separate datasets, Ego4D and EpicKitchens-100 ("Unseen Set"), as measured by several additional metrics, such as time to contact, and next-active-object localization. The code will be available upon acceptance.