 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Scoring with Enhanced Semantics for Training-Free Human-Object Interaction Detection
Jul 23, 2025



Human-Object Interaction (HOI) detection aims to identify humans and objects within images and interpret their interactions. Existing HOI methods rely heavily on large datasets with manual annotations to learn interactions from visual cues. These annotations are labor-intensive to create, prone to inconsistency, and limit scalability to new domains and rare interactions. We argue that recent advances in Vision-Language Models (VLMs) offer untapped potential, particularly in enhancing interaction representation. While prior work has injected such potential and even proposed training-free methods, there remain key gaps. Consequently, we propose a novel training-free HOI detection framework for Dynamic Scoring with enhanced semantics (DYSCO) that effectively utilizes textual and visual interaction representations within a multimodal registry, enabling robust and nuanced interaction understanding. This registry incorporates a small set of visual cues and uses innovative interaction signatures to improve the semantic alignment of verbs, facilitating effective generalization to rare interactions. Additionally, we propose a unique multi-head attention mechanism that adaptively weights the contributions of the visual and textual features. Experimental results demonstrate that our DYSCO surpasses training-free state-of-the-art models and is competitive with training-based approaches, particularly excelling in rare interactions. Code is available at https://github.com/francescotonini/dysco.
MADPOT: Medical Anomaly Detection with CLIP Adaptation and Partial Optimal Transport
Jul 09, 2025Medical anomaly detection (AD) is challenging due to diverse imaging modalities, anatomical variations, and limited labeled data. We propose a novel approach combining visual adapters and prompt learning with Partial Optimal Transport (POT) and contrastive learning (CL) to improve CLIP's adaptability to medical images, particularly for AD. Unlike standard prompt learning, which often yields a single representation, our method employs multiple prompts aligned with local features via POT to capture subtle abnormalities. CL further enforces intra-class cohesion and inter-class separation. Our method achieves state-of-the-art results in few-shot, zero-shot, and cross-dataset scenarios without synthetic data or memory banks. The code is available at https://github.com/mahshid1998/MADPOT.
CLIP-VAD: Exploiting Vision-Language Models for Voice Activity Detection
Oct 18, 2024



Voice Activity Detection (VAD) is the process of automatically determining whether a person is speaking and identifying the timing of their speech in an audiovisual data. Traditionally, this task has been tackled by processing either audio signals or visual data, or by combining both modalities through fusion or joint learning. In our study, drawing inspiration from recent advancements in visual-language models, we introduce a novel approach leveraging Contrastive Language-Image Pretraining (CLIP) models. The CLIP visual encoder analyzes video segments composed of the upper body of an individual, while the text encoder handles textual descriptions automatically generated through prompt engineering. Subsequently, embeddings from these encoders are fused through a deep neural network to perform VAD. Our experimental analysis across three VAD benchmarks showcases the superior performance of our method compared to existing visual VAD approaches. Notably, our approach outperforms several audio-visual methods despite its simplicity, and without requiring pre-training on extensive audio-visual datasets.
AL-GTD: Deep Active Learning for Gaze Target Detection
Sep 27, 2024



Gaze target detection aims at determining the image location where a person is looking. While existing studies have made significant progress in this area by regressing accurate gaze heatmaps, these achievements have largely relied on access to extensive labeled datasets, which demands substantial human labor. In this paper, our goal is to reduce the reliance on the size of labeled training data for gaze target detection. To achieve this, we propose AL-GTD, an innovative approach that integrates supervised and self-supervised losses within a novel sample acquisition function to perform active learning (AL). Additionally, it utilizes pseudo-labeling to mitigate distribution shifts during the training phase. AL-GTD achieves the best of all AUC results by utilizing only 40-50% of the training data, in contrast to state-of-the-art (SOTA) gaze target detectors requiring the entire training dataset to achieve the same performance. Importantly, AL-GTD quickly reaches satisfactory performance with 10-20% of the training data, showing the effectiveness of our acquisition function, which is able to acquire the most informative samples. We provide a comprehensive experimental analysis by adapting several AL methods for the task. AL-GTD outperforms AL competitors, simultaneously exhibiting superior performance compared to SOTA gaze target detectors when all are trained within a low-data regime. Code is available at https://github.com/francescotonini/al-gtd.
Upper-Body Pose-based Gaze Estimation for Privacy-Preserving 3D Gaze Target Detection
Sep 26, 2024



Gaze Target Detection (GTD), i.e., determining where a person is looking within a scene from an external viewpoint, is a challenging task, particularly in 3D space. Existing approaches heavily rely on analyzing the person's appearance, primarily focusing on their face to predict the gaze target. This paper presents a novel approach to tackle this problem by utilizing the person's upper-body pose and available depth maps to extract a 3D gaze direction and employing a multi-stage or an end-to-end pipeline to predict the gazed target. When predicted accurately, the human body pose can provide valuable information about the head pose, which is a good approximation of the gaze direction, as well as the position of the arms and hands, which are linked to the activity the person is performing and the objects they are likely focusing on. Consequently, in addition to performing gaze estimation in 3D, we are also able to perform GTD simultaneously. We demonstrate state-of-the-art results on the most comprehensive publicly accessible 3D gaze target detection dataset without requiring images of the person's face, thus promoting privacy preservation in various application contexts. The code is available at https://github.com/intelligolabs/privacy-gtd-3D.
Socially Pertinent Robots in Gerontological Healthcare
Apr 11, 2024
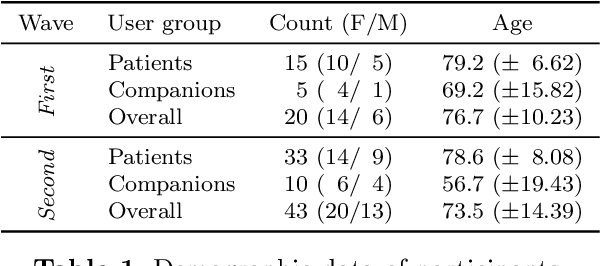
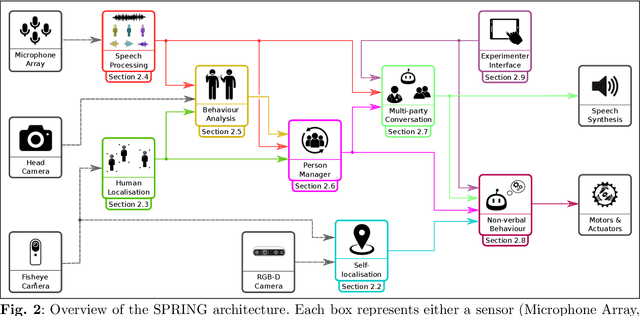
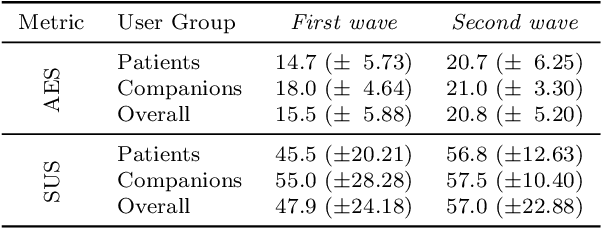
Despite the many recent achievements in developing and deploying social robotics, there are still many underexplored environments and applications for which systematic evaluation of such systems by end-users is necessary. While several robotic platforms have been used in gerontological healthcare, the question of whether or not a social interactive robot with multi-modal conversational capabilities will be useful and accepted in real-life facilities is yet to be answered. This paper is an attempt to partially answer this question, via two waves of experiments with patients and companions in a day-care gerontological facility in Paris with a full-sized humanoid robot endowed with social and conversational interaction capabilities. The software architecture, developed during the H2020 SPRING project, together with the experimental protocol, allowed us to evaluate the acceptability (AES) and usability (SUS) with more than 60 end-users. Overall, the users are receptive to this technology, especially when the robot perception and action skills are robust to environmental clutter and flexible to handle a plethora of different interactions.
Leveraging Next-Active Objects for Context-Aware Anticipation in Egocentric Videos
Aug 16, 2023



Objects are crucial for understanding human-object interactions. By identifying the relevant objects, one can also predict potential future interactions or actions that may occur with these objects. In this paper, we study the problem of Short-Term Object interaction anticipation (STA) and propose NAOGAT (Next-Active-Object Guided Anticipation Transformer), a multi-modal end-to-end transformer network, that attends to objects in observed frames in order to anticipate the next-active-object (NAO) and, eventually, to guide the model to predict context-aware future actions. The task is challenging since it requires anticipating future action along with the object with which the action occurs and the time after which the interaction will begin, a.k.a. the time to contact (TTC). Compared to existing video modeling architectures for action anticipation, NAOGAT captures the relationship between objects and the global scene context in order to predict detections for the next active object and anticipate relevant future actions given these detections, leveraging the objects' dynamics to improve accuracy. One of the key strengths of our approach, in fact, is its ability to exploit the motion dynamics of objects within a given clip, which is often ignored by other models, and separately decoding the object-centric and motion-centric information. Through our experiments, we show that our model outperforms existing methods on two separate datasets, Ego4D and EpicKitchens-100 ("Unseen Set"), as measured by several additional metrics, such as time to contact, and next-active-object localization. The code will be available upon acceptance.
Unsupervised Video Anomaly Detection with Diffusion Models Conditioned on Compact Motion Representations
Jul 19, 2023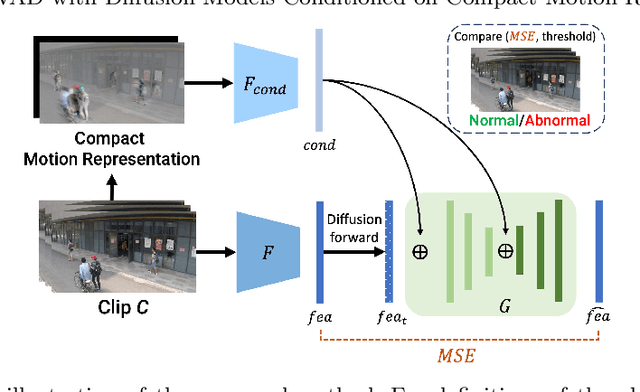
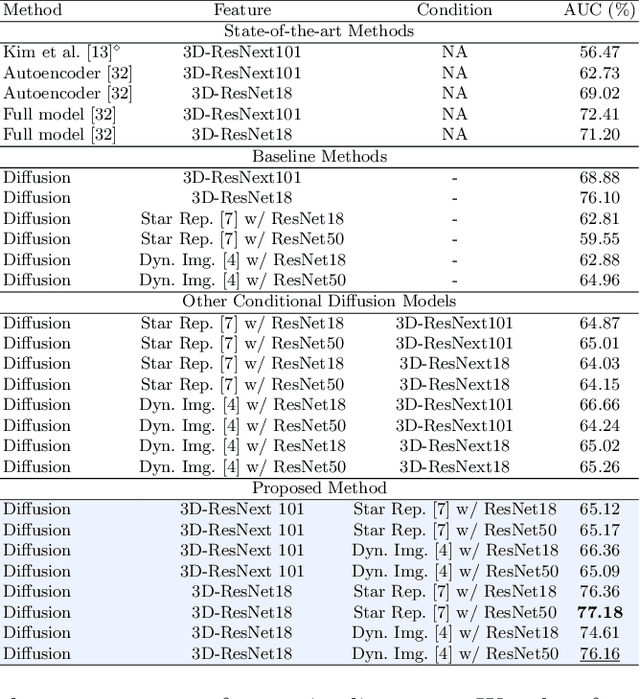


This paper aims to address the unsupervised video anomaly detection (VAD) problem, which involves classifying each frame in a video as normal or abnormal, without any access to labels. To accomplish this, the proposed method employs conditional diffusion models, where the input data is the spatiotemporal features extracted from a pre-trained network, and the condition is the features extracted from compact motion representations that summarize a given video segment in terms of its motion and appearance. Our method utilizes a data-driven threshold and considers a high reconstruction error as an indicator of anomalous events. This study is the first to utilize compact motion representations for VAD and the experiments conducted on two large-scale VAD benchmarks demonstrate that they supply relevant information to the diffusion model, and consequently improve VAD performances w.r.t the prior art. Importantly, our method exhibits better generalization performance across different datasets, notably outperforming both the state-of-the-art and baseline methods. The code of our method is available at https://github.com/AnilOsmanTur/conditioned_video_anomaly_diffusion
Object-aware Gaze Target Detection
Jul 18, 2023Gaze target detection aims to predict the image location where the person is looking and the probability that a gaze is out of the scene. Several works have tackled this task by regressing a gaze heatmap centered on the gaze location, however, they overlooked decoding the relationship between the people and the gazed objects. This paper proposes a Transformer-based architecture that automatically detects objects (including heads) in the scene to build associations between every head and the gazed-head/object, resulting in a comprehensive, explainable gaze analysis composed of: gaze target area, gaze pixel point, the class and the image location of the gazed-object. Upon evaluation of the in-the-wild benchmarks, our method achieves state-of-the-art results on all metrics (up to 2.91% gain in AUC, 50% reduction in gaze distance, and 9% gain in out-of-frame average precision) for gaze target detection and 11-13% improvement in average precision for the classification and the localization of the gazed-objects. The code of the proposed method is available https://github.com/francescotonini/object-aware-gaze-target-detection
Guided Attention for Next Active Object @ EGO4D STA Challenge
May 25, 2023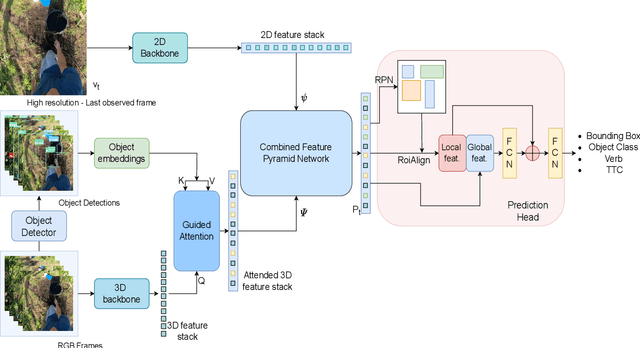
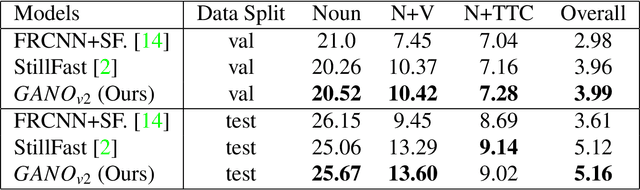
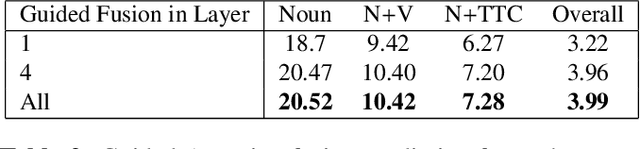
In this technical report, we describe the Guided-Attention mechanism based solution for the short-term anticipation (STA) challenge for the EGO4D challenge. It combines the object detections, and the spatiotemporal features extracted from video clips, enhancing the motion and contextual information, and further decoding the object-centric and motion-centric information to address the problem of STA in egocentric videos. For the challenge, we build our model on top of StillFast with Guided Attention applied on fast network. Our model obtains better performance on the validation set and also achieves state-of-the-art (SOTA) results on the challenge test set for EGO4D Short-Term Object Interaction Anticipation Challenge.