 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Diffusion Models for Unsupervised Video Anomaly Detection
Paper and Code
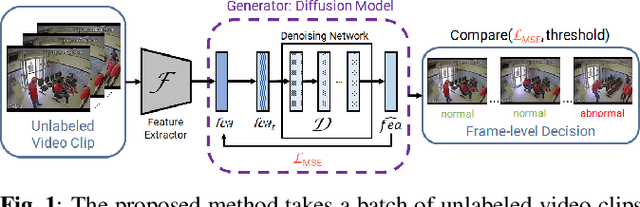

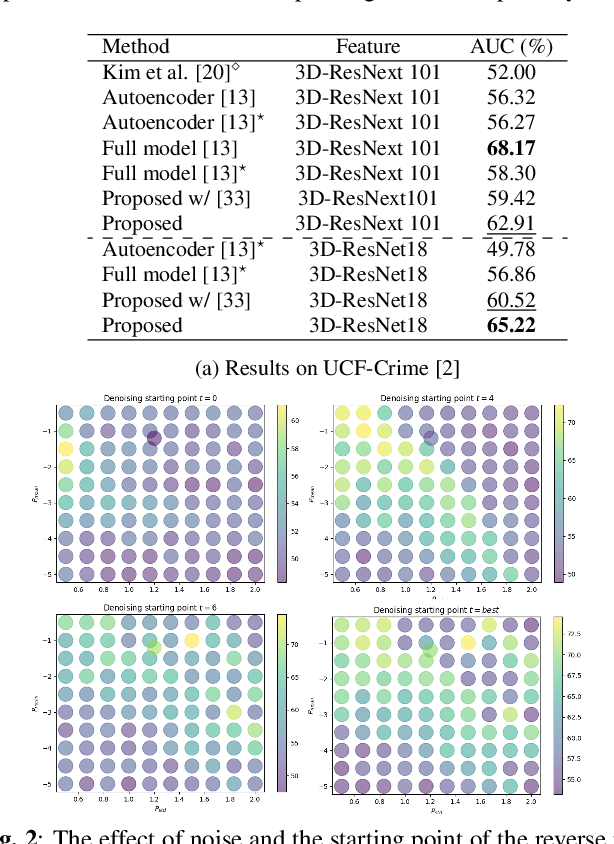
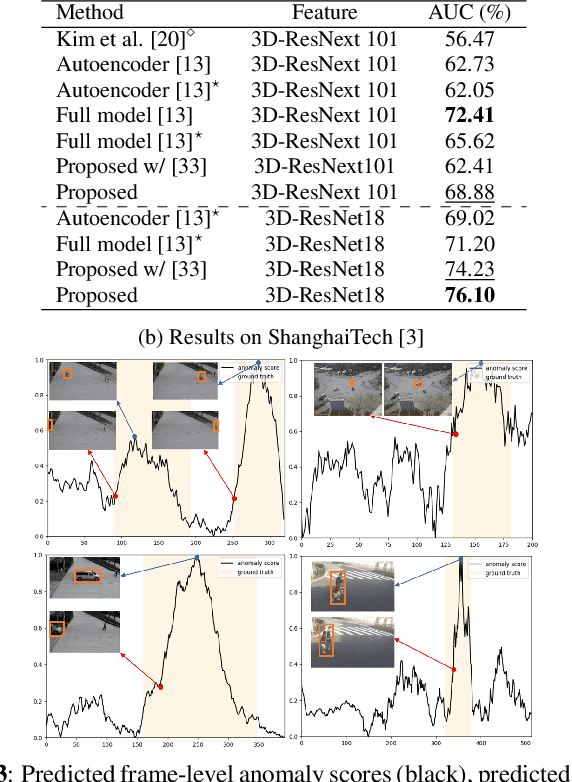
This paper investigates the performance of diffusion models for video anomaly detection (VAD) within the most challenging but also the most operational scenario in which the data annotations are not used. As being sparse, diverse, contextual, and often ambiguous, detecting abnormal events precisely is a very ambitious task. To this end, we rely only on the information-rich spatio-temporal data, and the reconstruction power of the diffusion models such that a high reconstruction error is utilized to decide the abnormality. Experiments performed on two large-scale video anomaly detection datasets demonstrate the consistent improvement of the proposed method over the state-of-the-art generative models while in some cases our method achieves better scores than the more complex models. This is the first study using a diffusion model and examining its parameters' influence to present guidance for VAD in surveillance scenarios.