 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMBO: High-Resolution Generative Approach for Mammography Images
Jun 10, 2025Mammography is the gold standard for the detection and diagnosis of breast cancer. This procedure can be significantly enhanced with Artificial Intelligence (AI)-based software, which assists radiologists in identifying abnormalities. However, training AI systems requires large and diverse datasets, which are often difficult to obtain due to privacy and ethical constraints. To address this issue, the paper introduces MAMmography ensemBle mOdel (MAMBO), a novel patch-based diffusion approach designed to generate full-resolution mammograms. Diffusion models have shown breakthrough results in realistic image generation, yet few studies have focused on mammograms, and none have successfully generated high-resolution outputs required to capture fine-grained features of small lesions. To achieve this, MAMBO integrates separate diffusion models to capture both local and global (image-level) contexts. The contextual information is then fed into the final patch-based model, significantly aiding the noise removal process. This thoughtful design enables MAMBO to generate highly realistic mammograms of up to 3840x3840 pixels. Importantly, this approach can be used to enhance the training of classification models and extended to anomaly detection. Experiments, both numerical and radiologist validation, assess MAMBO's capabilities in image generation, super-resolution, and anomaly detection, highlighting its potential to enhance mammography analysis for more accurate diagnoses and earlier lesion detection.
Unsupervised Video Anomaly Detection with Diffusion Models Conditioned on Compact Motion Representations
Jul 19, 2023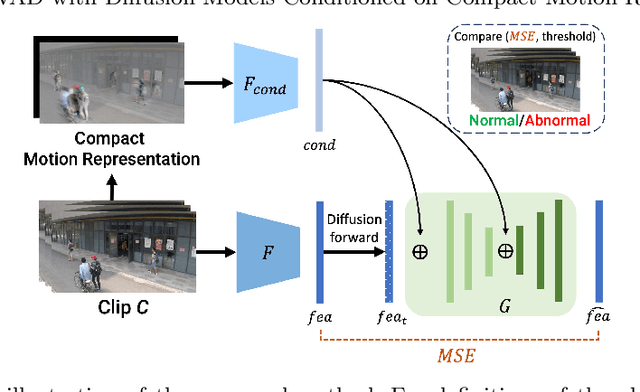
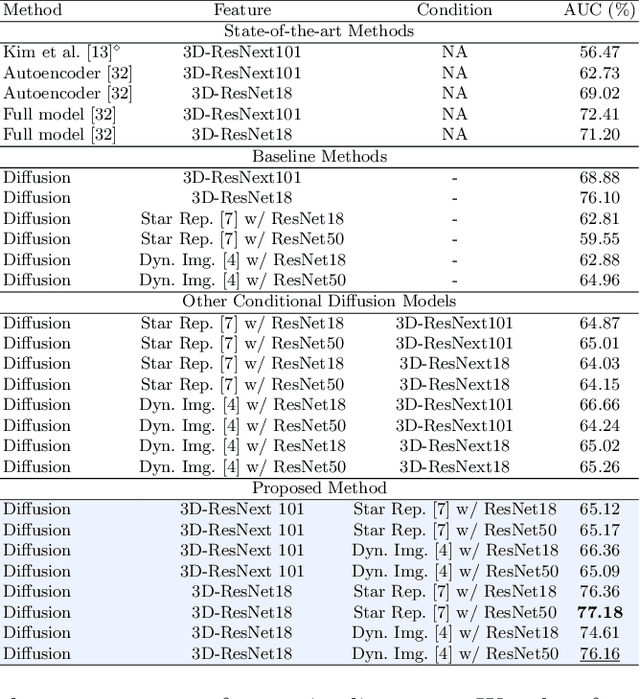


This paper aims to address the unsupervised video anomaly detection (VAD) problem, which involves classifying each frame in a video as normal or abnormal, without any access to labels. To accomplish this, the proposed method employs conditional diffusion models, where the input data is the spatiotemporal features extracted from a pre-trained network, and the condition is the features extracted from compact motion representations that summarize a given video segment in terms of its motion and appearance. Our method utilizes a data-driven threshold and considers a high reconstruction error as an indicator of anomalous events. This study is the first to utilize compact motion representations for VAD and the experiments conducted on two large-scale VAD benchmarks demonstrate that they supply relevant information to the diffusion model, and consequently improve VAD performances w.r.t the prior art. Importantly, our method exhibits better generalization performance across different datasets, notably outperforming both the state-of-the-art and baseline methods. The code of our method is available at https://github.com/AnilOsmanTur/conditioned_video_anomaly_diffusion
Exploring Diffusion Models for Unsupervised Video Anomaly Detection
Apr 12, 2023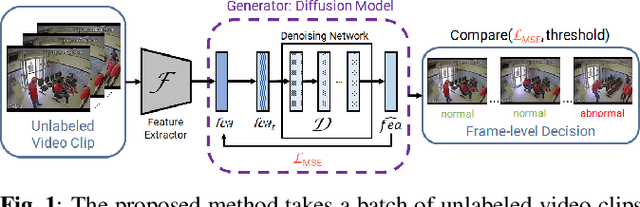

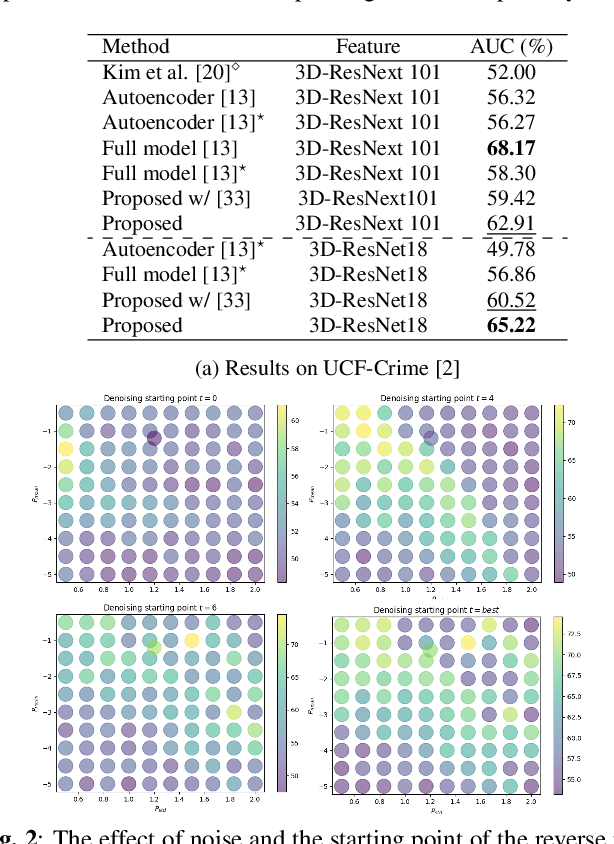
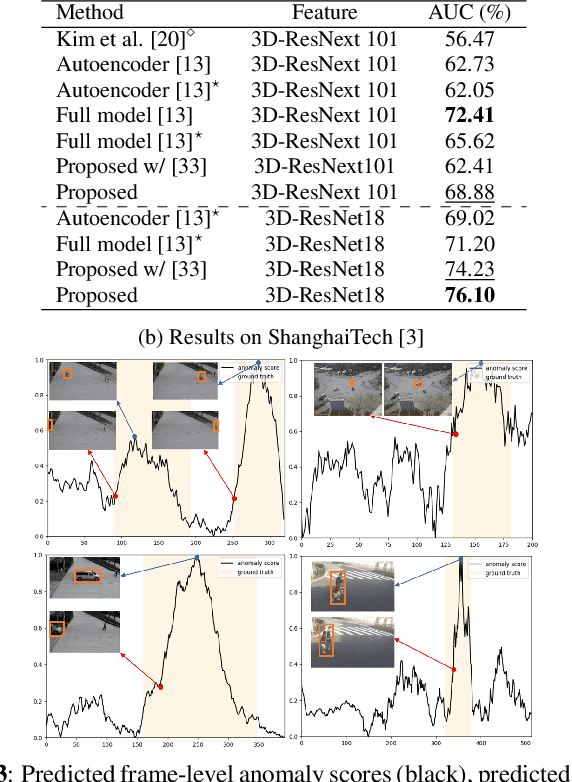
This paper investigates the performance of diffusion models for video anomaly detection (VAD) within the most challenging but also the most operational scenario in which the data annotations are not used. As being sparse, diverse, contextual, and often ambiguous, detecting abnormal events precisely is a very ambitious task. To this end, we rely only on the information-rich spatio-temporal data, and the reconstruction power of the diffusion models such that a high reconstruction error is utilized to decide the abnormality. Experiments performed on two large-scale video anomaly detection datasets demonstrate the consistent improvement of the proposed method over the state-of-the-art generative models while in some cases our method achieves better scores than the more complex models. This is the first study using a diffusion model and examining its parameters' influence to present guidance for VAD in surveillance scenarios.
Evaluation Of Hidden Markov Models Using Deep CNN Features In Isolated Sign Recognition
Jun 19, 2020



Isolated sign recognition from video streams is a challenging problem due to the multi-modal nature of the signs, where both local and global hand features and face gestures needs to be attended simultaneously. This problem has recently been studied widely using deep Convolutional Neural Network (CNN) based features and Long Short-Term Memory (LSTM) based deep sequence models. However, the current literature is lack of providing empirical analysis using Hidden Markov Models (HMMs) with deep features. In this study, we provide a framework that is composed of three modules to solve isolated sign recognition problem using different sequence models. The dimensions of deep features are usually too large to work with HMM models. To solve this problem, we propose two alternative CNN based architectures as the second module in our framework, to reduce deep feature dimensions effectively. After extensive experiments, we show that using pretrained Resnet50 features and one of our CNN based dimension reduction models, HMMs can classify isolated signs with 90.15\% accuracy in Montalbano dataset using RGB and Skeletal data. This performance is comparable with the current LSTM based models. HMMs have fewer parameters and can be trained and run on commodity computers fast, without requiring GPUs. Therefore, our analysis with deep features show that HMMs could also be utilized as well as deep sequence models in challenging isolated sign recognition problem.