 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Video Anomaly Detection with Diffusion Models Conditioned on Compact Motion Representations
Paper and Code
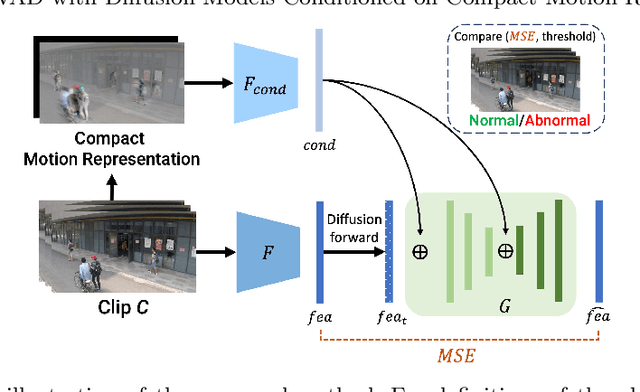
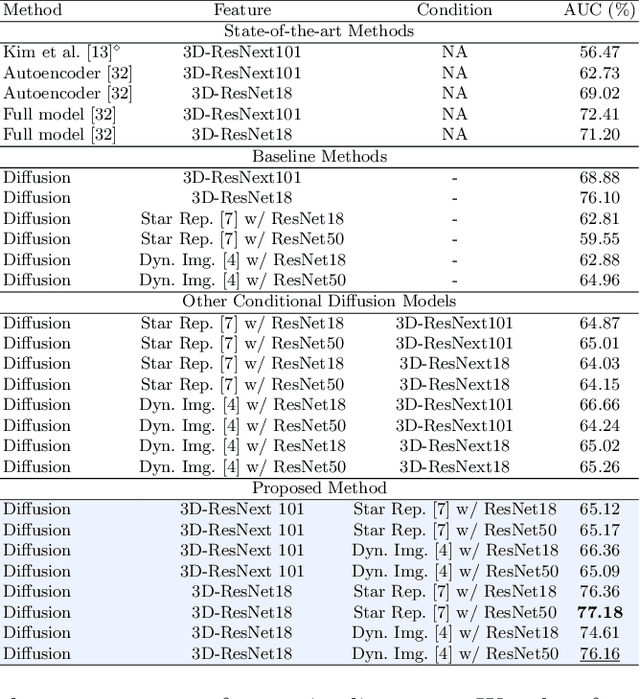


This paper aims to address the unsupervised video anomaly detection (VAD) problem, which involves classifying each frame in a video as normal or abnormal, without any access to labels. To accomplish this, the proposed method employs conditional diffusion models, where the input data is the spatiotemporal features extracted from a pre-trained network, and the condition is the features extracted from compact motion representations that summarize a given video segment in terms of its motion and appearance. Our method utilizes a data-driven threshold and considers a high reconstruction error as an indicator of anomalous events. This study is the first to utilize compact motion representations for VAD and the experiments conducted on two large-scale VAD benchmarks demonstrate that they supply relevant information to the diffusion model, and consequently improve VAD performances w.r.t the prior art. Importantly, our method exhibits better generalization performance across different datasets, notably outperforming both the state-of-the-art and baseline methods. The code of our method is available at https://github.com/AnilOsmanTur/conditioned_video_anomaly_diffusion