 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA$^{2}$V-SLP: Alignment-Aware Variational Modeling for Disentangled Sign Language Production
Feb 12, 2026Building upon recent structural disentanglement frameworks for sign language production, we propose A$^{2}$V-SLP, an alignment-aware variational framework that learns articulator-wise disentangled latent distributions rather than deterministic embeddings. A disentangled Variational Autoencoder (VAE) encodes ground-truth sign pose sequences and extracts articulator-specific mean and variance vectors, which are used as distributional supervision for training a non-autoregressive Transformer. Given text embeddings, the Transformer predicts both latent means and log-variances, while the VAE decoder reconstructs the final sign pose sequences through stochastic sampling at the decoding stage. This formulation maintains articulator-level representations by avoiding deterministic latent collapse through distributional latent modeling. In addition, we integrate a gloss attention mechanism to strengthen alignment between linguistic input and articulated motion. Experimental results show consistent gains over deterministic latent regression, achieving state-of-the-art back-translation performance and improved motion realism in a fully gloss-free setting.
SLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work
Aug 09, 2025Sign Language Production (SLP) is the task of generating sign language video from spoken language inputs. The field has seen a range of innovations over the last few years, with the introduction of deep learning-based approaches providing significant improvements in the realism and naturalness of generated outputs. However, the lack of standardized evaluation metrics for SLP approaches hampers meaningful comparisons across different systems. To address this, we introduce the first Sign Language Production Challenge, held as part of the third SLRTP Workshop at CVPR 2025. The competition's aims are to evaluate architectures that translate from spoken language sentences to a sequence of skeleton poses, known as Text-to-Pose (T2P) translation, over a range of metrics. For our evaluation data, we use the RWTH-PHOENIX-Weather-2014T dataset, a German Sign Language - Deutsche Gebardensprache (DGS) weather broadcast dataset. In addition, we curate a custom hidden test set from a similar domain of discourse. This paper presents the challenge design and the winning methodologies. The challenge attracted 33 participants who submitted 231 solutions, with the top-performing team achieving BLEU-1 scores of 31.40 and DTW-MJE of 0.0574. The winning approach utilized a retrieval-based framework and a pre-trained language model. As part of the workshop, we release a standardized evaluation network, including high-quality skeleton extraction-based keypoints establishing a consistent baseline for the SLP field, which will enable future researchers to compare their work against a broader range of methods.
Disentangle and Regularize: Sign Language Production with Articulator-Based Disentanglement and Channel-Aware Regularization
Apr 09, 2025



In this work, we propose a simple gloss-free, transformer-based sign language production (SLP) framework that directly maps spoken-language text to sign pose sequences. We first train a pose autoencoder that encodes sign poses into a compact latent space using an articulator-based disentanglement strategy, where features corresponding to the face, right hand, left hand, and body are modeled separately to promote structured and interpretable representation learning. Next, a non-autoregressive transformer decoder is trained to predict these latent representations from sentence-level text embeddings. To guide this process, we apply channel-aware regularization by aligning predicted latent distributions with priors extracted from the ground-truth encodings using a KL-divergence loss. The contribution of each channel to the loss is weighted according to its associated articulator region, enabling the model to account for the relative importance of different articulators during training. Our approach does not rely on gloss supervision or pretrained models, and achieves state-of-the-art results on the PHOENIX14T dataset using only a modest training set.
E-TSL: A Continuous Educational Turkish Sign Language Dataset with Baseline Methods
May 05, 2024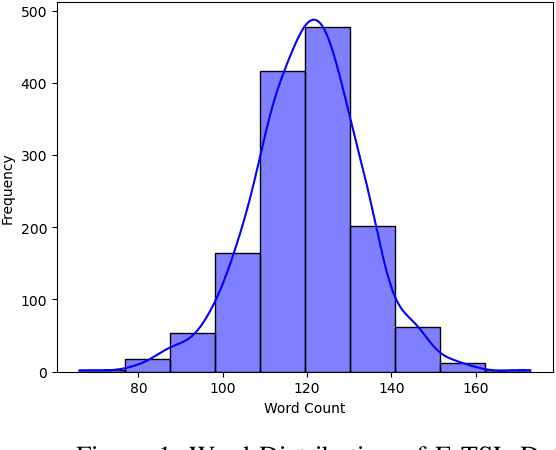


This study introduces the continuous Educational Turkish Sign Language (E-TSL) dataset, collected from online Turkish language lessons for 5th, 6th, and 8th grades. The dataset comprises 1,410 videos totaling nearly 24 hours and includes performances from 11 signers. Turkish, an agglutinative language, poses unique challenges for sign language translation, particularly with a vocabulary where 64% are singleton words and 85% are rare words, appearing less than five times. We developed two baseline models to address these challenges: the Pose to Text Transformer (P2T-T) and the Graph Neural Network based Transformer (GNN-T) models. The GNN-T model achieved 19.13% BLEU-1 score and 3.28% BLEU-4 score, presenting a significant challenge compared to existing benchmarks. The P2T-T model, while demonstrating slightly lower performance in BLEU scores, achieved a higher ROUGE-L score of 22.09%. Additionally, we benchmarked our model using the well-known PHOENIX-Weather 2014T dataset to validate our approach.
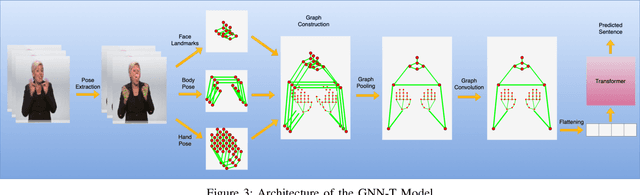
SkelCap: Automated Generation of Descriptive Text from Skeleton Keypoint Sequences
May 05, 2024



Numerous sign language datasets exist, yet they typically cover only a limited selection of the thousands of signs used globally. Moreover, creating diverse sign language datasets is an expensive and challenging task due to the costs associated with gathering a varied group of signers. Motivated by these challenges, we aimed to develop a solution that addresses these limitations. In this context, we focused on textually describing body movements from skeleton keypoint sequences, leading to the creation of a new dataset. We structured this dataset around AUTSL, a comprehensive isolated Turkish sign language dataset. We also developed a baseline model, SkelCap, which can generate textual descriptions of body movements. This model processes the skeleton keypoints data as a vector, applies a fully connected layer for embedding, and utilizes a transformer neural network for sequence-to-sequence modeling. We conducted extensive evaluations of our model, including signer-agnostic and sign-agnostic assessments. The model achieved promising results, with a ROUGE-L score of 0.98 and a BLEU-4 score of 0.94 in the signer-agnostic evaluation. The dataset we have prepared, namely the AUTSL-SkelCap, will be made publicly available soon.
Meta-Transfer Derm-Diagnosis: Exploring Few-Shot Learning and Transfer Learning for Skin Disease Classification in Long-Tail Distribution
Apr 25, 2024
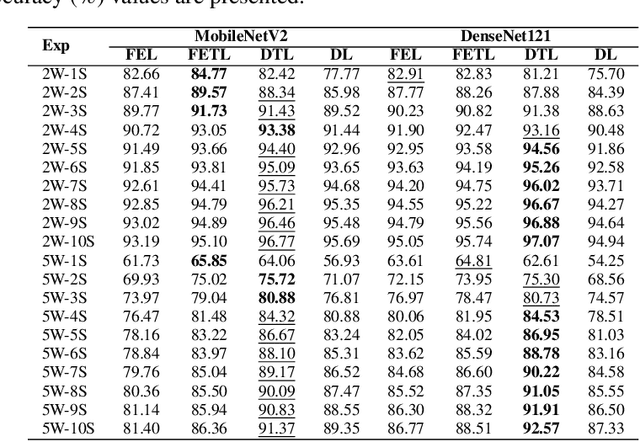
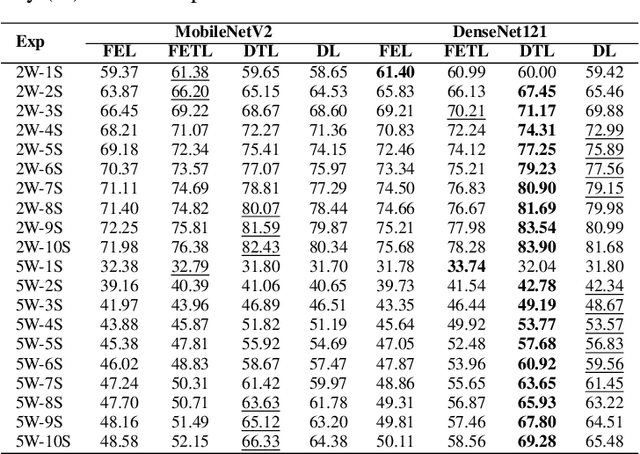
Addressing the challenges of rare diseases is difficult, especially with the limited number of reference images and a small patient population. This is more evident in rare skin diseases, where we encounter long-tailed data distributions that make it difficult to develop unbiased and broadly effective models. The diverse ways in which image datasets are gathered and their distinct purposes also add to these challenges. Our study conducts a detailed examination of the benefits and drawbacks of episodic and conventional training methodologies, adopting a few-shot learning approach alongside transfer learning. We evaluated our models using the ISIC2018, Derm7pt, and SD-198 datasets. With minimal labeled examples, our models showed substantial information gains and better performance compared to previously trained models. Our research emphasizes the improved ability to represent features in DenseNet121 and MobileNetV2 models, achieved by using pre-trained models on ImageNet to increase similarities within classes. Moreover, our experiments, ranging from 2-way to 5-way classifications with up to 10 examples, showed a growing success rate for traditional transfer learning methods as the number of examples increased. The addition of data augmentation techniques significantly improved our transfer learning based model performance, leading to higher performances than existing methods, especially in the SD-198 and ISIC2018 datasets. All source code related to this work will be made publicly available soon at the provided URL.
Adversarial Sparse Teacher: Defense Against Distillation-Based Model Stealing Attacks Using Adversarial Examples
Mar 08, 2024Knowledge Distillation (KD) facilitates the transfer of discriminative capabilities from an advanced teacher model to a simpler student model, ensuring performance enhancement without compromising accuracy. It is also exploited for model stealing attacks, where adversaries use KD to mimic the functionality of a teacher model. Recent developments in this domain have been influenced by the Stingy Teacher model, which provided empirical analysis showing that sparse outputs can significantly degrade the performance of student models. Addressing the risk of intellectual property leakage, our work introduces an approach to train a teacher model that inherently protects its logits, influenced by the Nasty Teacher concept. Differing from existing methods, we incorporate sparse outputs of adversarial examples with standard training data to strengthen the teacher's defense against student distillation. Our approach carefully reduces the relative entropy between the original and adversarially perturbed outputs, allowing the model to produce adversarial logits with minimal impact on overall performance. The source codes will be made publicly available soon.
SVInvNet: A Densely Connected Encoder-Decoder Architecture for Seismic Velocity Inversion
Dec 13, 2023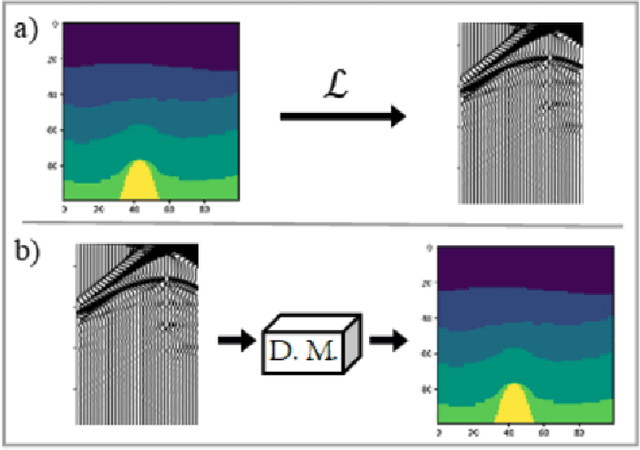
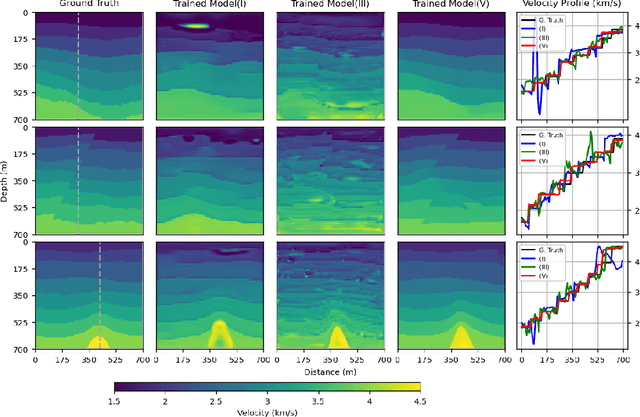
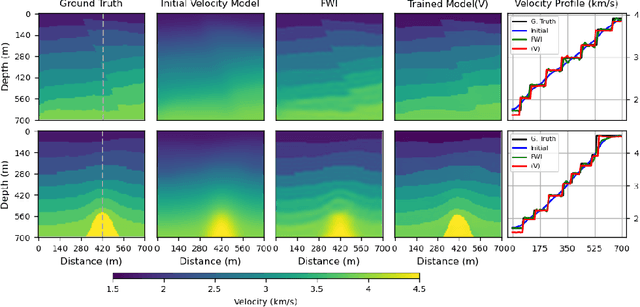
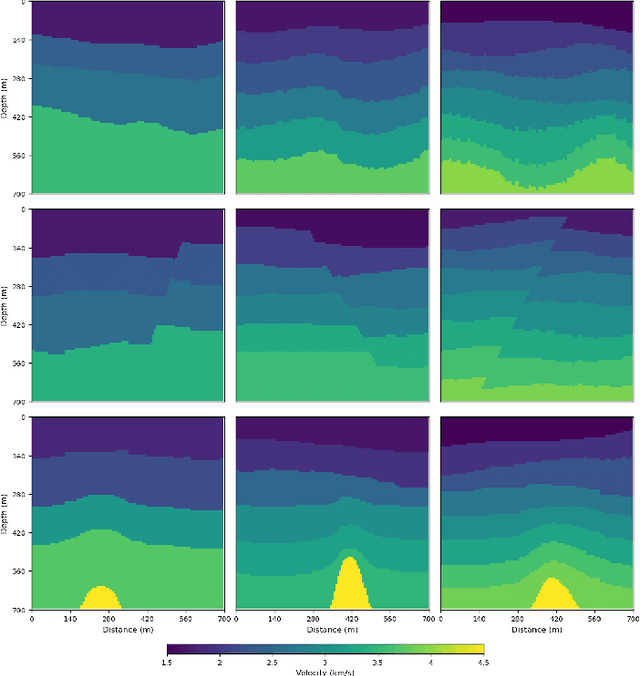
This study presents a deep learning-based approach to seismic velocity inversion problem, focusing on both noisy and noiseless training datasets of varying sizes. Our Seismic Velocity Inversion Network (SVInvNet) introduces a novel architecture that contains a multi-connection encoder-decoder structure enhanced with dense blocks. This design is specifically tuned to effectively process complex information, crucial for addressing the challenges of non-linear seismic velocity inversion. For training and testing, we created diverse seismic velocity models, including multi-layered, faulty, and salt dome categories. We also investigated how different kinds of ambient noise, both coherent and stochastic, and the size of the training dataset affect learning outcomes. SVInvNet is trained on datasets ranging from 750 to 6,000 samples and is tested using a large benchmark dataset of 12,000 samples. Despite its fewer parameters compared to the baseline, SVInvNet achieves superior performance with this dataset. The outcomes of the SVInvNet are additionally compared to those of the Full Waveform Inversion (FWI) method. The comparative analysis clearly reveals the effectiveness of the proposed model.
Using Motion History Images with 3D Convolutional Networks in Isolated Sign Language Recognition
Oct 24, 2021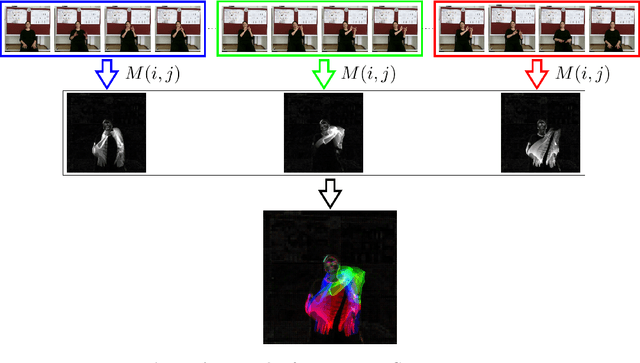

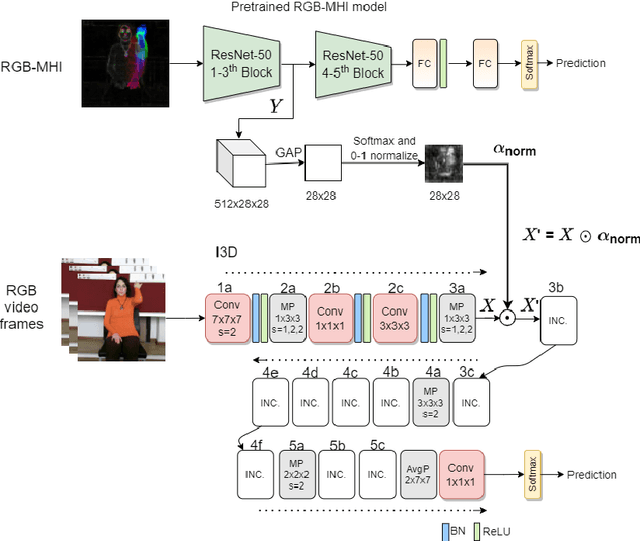

Sign language recognition using computational models is a challenging problem that requires simultaneous spatio-temporal modeling of the multiple sources, i.e. faces, hands, body etc. In this paper, we propose an isolated sign language recognition model based on a model trained using Motion History Images (MHI) that are generated from RGB video frames. RGB-MHI images represent spatio-temporal summary of each sign video effectively in a single RGB image. We propose two different approaches using this model. In the first approach, we use RGB-MHI model as a motion-based spatial attention module integrated in a 3D-CNN architecture. In the second approach, we use RGB-MHI model features directly with a late fusion technique with the features of a 3D-CNN model. We perform extensive experiments on two recently released large-scale isolated sign language datasets, namely AUTSL and BosphorusSign22k datasets. Our experiments show that our models, which use only RGB data, can compete with the state-of-the-art models in the literature that use multi-modal data.
Towards disease-aware image editing of chest X-rays
Sep 03, 2021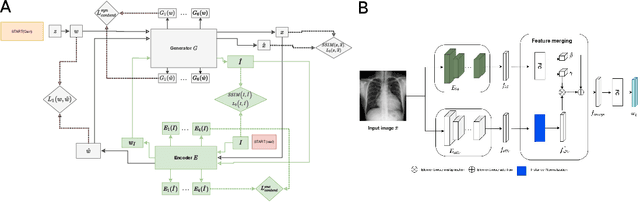
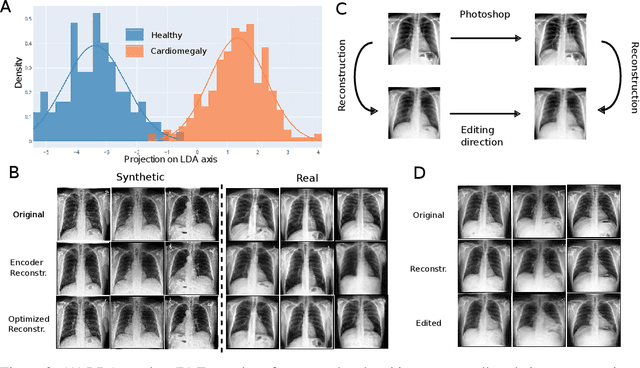
Disease-aware image editing by means of generative adversarial networks (GANs) constitutes a promising avenue for advancing the use of AI in the healthcare sector. Here, we present a proof of concept of this idea. While GAN-based techniques have been successful in generating and manipulating natural images, their application to the medical domain, however, is still in its infancy. Working with the CheXpert data set, we show that StyleGAN can be trained to generate realistic chest X-rays. Inspired by the Cyclic Reverse Generator (CRG) framework, we train an encoder that allows for faithfully inverting the generator on synthetic X-rays and provides organ-level reconstructions of real ones. Employing a guided manipulation of latent codes, we confer the medical condition of cardiomegaly (increased heart size) onto real X-rays from healthy patients. This work was presented in the Medical Imaging meets Neurips Workshop 2020, which was held as part of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020) in Vancouver, Canada