 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Motion History Images with 3D Convolutional Networks in Isolated Sign Language Recognition
Paper and Code
Oct 24, 2021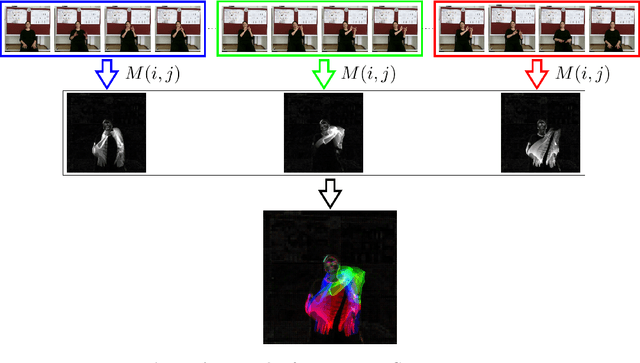

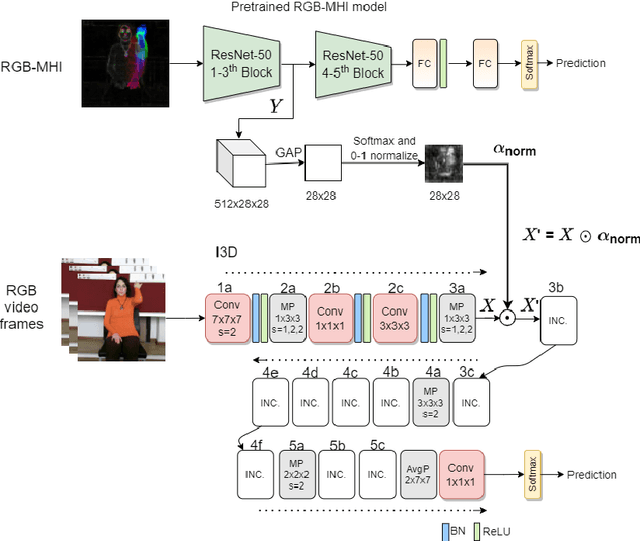

Sign language recognition using computational models is a challenging problem that requires simultaneous spatio-temporal modeling of the multiple sources, i.e. faces, hands, body etc. In this paper, we propose an isolated sign language recognition model based on a model trained using Motion History Images (MHI) that are generated from RGB video frames. RGB-MHI images represent spatio-temporal summary of each sign video effectively in a single RGB image. We propose two different approaches using this model. In the first approach, we use RGB-MHI model as a motion-based spatial attention module integrated in a 3D-CNN architecture. In the second approach, we use RGB-MHI model features directly with a late fusion technique with the features of a 3D-CNN model. We perform extensive experiments on two recently released large-scale isolated sign language datasets, namely AUTSL and BosphorusSign22k datasets. Our experiments show that our models, which use only RGB data, can compete with the state-of-the-art models in the literature that use multi-modal data.