 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Taxonomy of Structure from Motion Methods
May 21, 2025



Structure from Motion (SfM) refers to the problem of recovering both structure (i.e., 3D coordinates of points in the scene) and motion (i.e., camera matrices) starting from point correspondences in multiple images. It has attracted significant attention over the years, counting practical reconstruction pipelines as well as theoretical results. This paper is conceived as a conceptual review of SfM methods, which are grouped into three main categories, according to which part of the problem - between motion and structure - they focus on. The proposed taxonomy brings a new perspective on existing SfM approaches as well as insights into open problems and possible future research directions. Particular emphasis is given on identifying the theoretical conditions that make SfM well posed, which depend on the problem formulation that is being considered.
Outlier-Robust Multi-Model Fitting on Quantum Annealers
Apr 18, 2025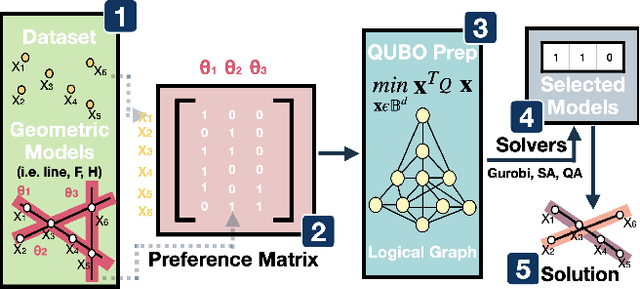
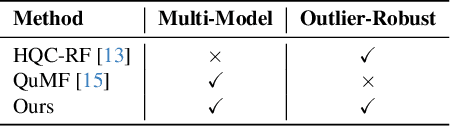
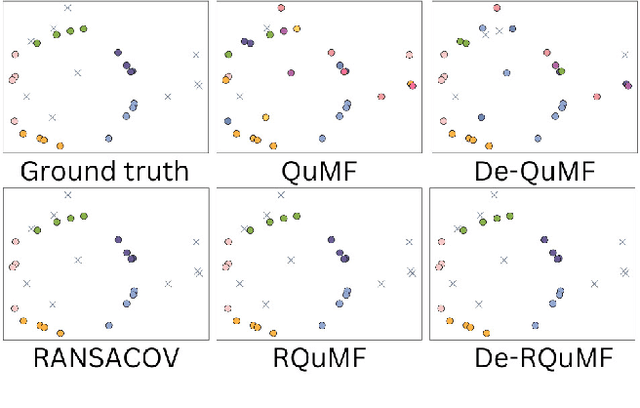

Multi-model fitting (MMF) presents a significant challenge in Computer Vision, particularly due to its combinatorial nature. While recent advancements in quantum computing offer promise for addressing NP-hard problems, existing quantum-based approaches for model fitting are either limited to a single model or consider multi-model scenarios within outlier-free datasets. This paper introduces a novel approach, the robust quantum multi-model fitting (R-QuMF) algorithm, designed to handle outliers effectively. Our method leverages the intrinsic capabilities of quantum hardware to tackle combinatorial challenges inherent in MMF tasks, and it does not require prior knowledge of the exact number of models, thereby enhancing its practical applicability. By formulating the problem as a maximum set coverage task for adiabatic quantum computers (AQC), R-QuMF outperforms existing quantum techniques, demonstrating superior performance across various synthetic and real-world 3D datasets. Our findings underscore the potential of quantum computing in addressing the complexities of MMF, especially in real-world scenarios with noisy and outlier-prone data.
An Algebraic Geometry Approach to Viewing Graph Solvability
Apr 04, 2025



The concept of viewing graph solvability has gained significant interest in the context of structure-from-motion. A viewing graph is a mathematical structure where nodes are associated to cameras and edges represent the epipolar geometry connecting overlapping views. Solvability studies under which conditions the cameras are uniquely determined by the graph. In this paper we propose a novel framework for analyzing solvability problems based on Algebraic Geometry, demonstrating its potential in understanding structure-from-motion graphs and proving a conjecture that was previously proposed.
Temporal-consistent CAMs for Weakly Supervised Video Segmentation in Waste Sorting
Feb 03, 2025In industrial settings, weakly supervised (WS) methods are usually preferred over their fully supervised (FS) counterparts as they do not require costly manual annotations. Unfortunately, the segmentation masks obtained in the WS regime are typically poor in terms of accuracy. In this work, we present a WS method capable of producing accurate masks for semantic segmentation in the case of video streams. More specifically, we build saliency maps that exploit the temporal coherence between consecutive frames in a video, promoting consistency when objects appear in different frames. We apply our method in a waste-sorting scenario, where we perform weakly supervised video segmentation (WSVS) by training an auxiliary classifier that distinguishes between videos recorded before and after a human operator, who manually removes specific wastes from a conveyor belt. The saliency maps of this classifier identify materials to be removed, and we modify the classifier training to minimize differences between the saliency map of a central frame and those in adjacent frames, after having compensated object displacement. Experiments on a real-world dataset demonstrate the benefits of integrating temporal coherence directly during the training phase of the classifier. Code and dataset are available upon request.
Socially Pertinent Robots in Gerontological Healthcare
Apr 11, 2024
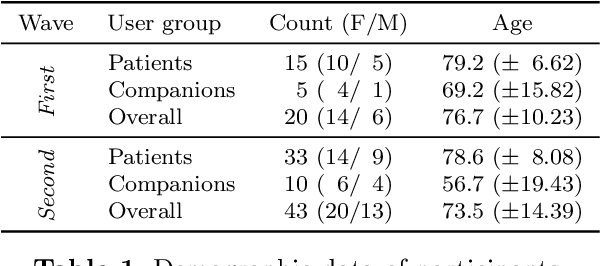
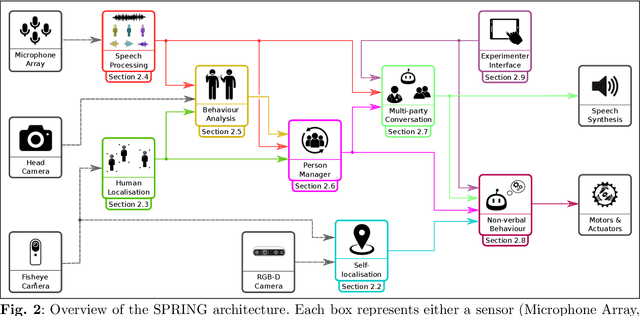
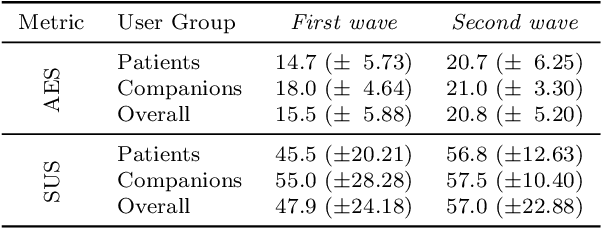
Despite the many recent achievements in developing and deploying social robotics, there are still many underexplored environments and applications for which systematic evaluation of such systems by end-users is necessary. While several robotic platforms have been used in gerontological healthcare, the question of whether or not a social interactive robot with multi-modal conversational capabilities will be useful and accepted in real-life facilities is yet to be answered. This paper is an attempt to partially answer this question, via two waves of experiments with patients and companions in a day-care gerontological facility in Paris with a full-sized humanoid robot endowed with social and conversational interaction capabilities. The software architecture, developed during the H2020 SPRING project, together with the experimental protocol, allowed us to evaluate the acceptability (AES) and usability (SUS) with more than 60 end-users. Overall, the users are receptive to this technology, especially when the robot perception and action skills are robust to environmental clutter and flexible to handle a plethora of different interactions.
Interactive Neural Painting
Jul 31, 2023



In the last few years, Neural Painting (NP) techniques became capable of producing extremely realistic artworks. This paper advances the state of the art in this emerging research domain by proposing the first approach for Interactive NP. Considering a setting where a user looks at a scene and tries to reproduce it on a painting, our objective is to develop a computational framework to assist the users creativity by suggesting the next strokes to paint, that can be possibly used to complete the artwork. To accomplish such a task, we propose I-Paint, a novel method based on a conditional transformer Variational AutoEncoder (VAE) architecture with a two-stage decoder. To evaluate the proposed approach and stimulate research in this area, we also introduce two novel datasets. Our experiments show that our approach provides good stroke suggestions and compares favorably to the state of the art. Additional details, code and examples are available at https://helia95.github.io/inp-website.
Rotation Synchronization via Deep Matrix Factorization
May 09, 2023



In this paper we address the rotation synchronization problem, where the objective is to recover absolute rotations starting from pairwise ones, where the unknowns and the measures are represented as nodes and edges of a graph, respectively. This problem is an essential task for structure from motion and simultaneous localization and mapping. We focus on the formulation of synchronization via neural networks, which has only recently begun to be explored in the literature. Inspired by deep matrix completion, we express rotation synchronization in terms of matrix factorization with a deep neural network. Our formulation exhibits implicit regularization properties and, more importantly, is unsupervised, whereas previous deep approaches are supervised. Our experiments show that we achieve comparable accuracy to the closest competitors in most scenes, while working under weaker assumptions.
Quantum Multi-Model Fitting
Mar 27, 2023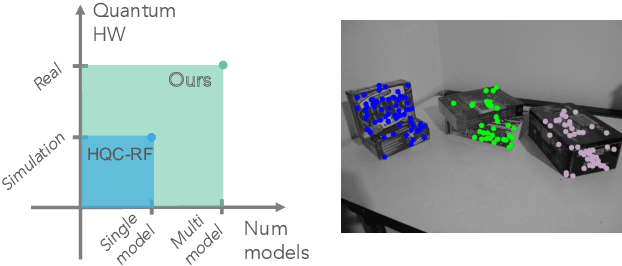


Geometric model fitting is a challenging but fundamental computer vision problem. Recently, quantum optimization has been shown to enhance robust fitting for the case of a single model, while leaving the question of multi-model fitting open. In response to this challenge, this paper shows that the latter case can significantly benefit from quantum hardware and proposes the first quantum approach to multi-model fitting (MMF). We formulate MMF as a problem that can be efficiently sampled by modern adiabatic quantum computers without the relaxation of the objective function. We also propose an iterative and decomposed version of our method, which supports real-world-sized problems. The experimental evaluation demonstrates promising results on a variety of datasets. The source code is available at: https://github.com/FarinaMatteo/qmmf.
Multimodal Emotion Recognition with Modality-Pairwise Unsupervised Contrastive Loss
Jul 23, 2022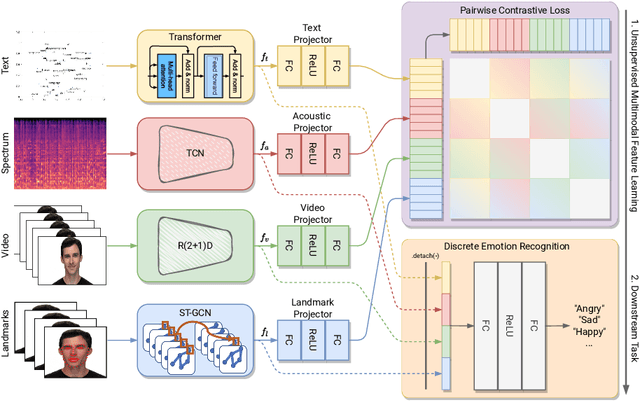



Emotion recognition is involved in several real-world applications. With an increase in available modalities, automatic understanding of emotions is being performed more accurately. The success in Multimodal Emotion Recognition (MER), primarily relies on the supervised learning paradigm. However, data annotation is expensive, time-consuming, and as emotion expression and perception depends on several factors (e.g., age, gender, culture) obtaining labels with a high reliability is hard. Motivated by these, we focus on unsupervised feature learning for MER. We consider discrete emotions, and as modalities text, audio and vision are used. Our method, as being based on contrastive loss between pairwise modalities, is the first attempt in MER literature. Our end-to-end feature learning approach has several differences (and advantages) compared to existing MER methods: i) it is unsupervised, so the learning is lack of data labelling cost; ii) it does not require data spatial augmentation, modality alignment, large number of batch size or epochs; iii) it applies data fusion only at inference; and iv) it does not require backbones pre-trained on emotion recognition task. The experiments on benchmark datasets show that our method outperforms several baseline approaches and unsupervised learning methods applied in MER. Particularly, it even surpasses a few supervised MER state-of-the-art.
Quantum Motion Segmentation
Mar 24, 2022
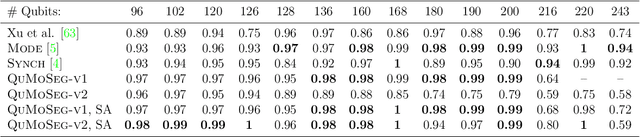


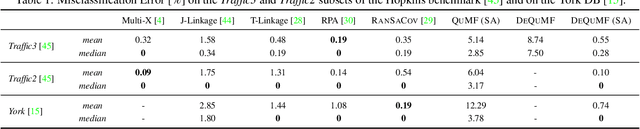
Motion segmentation is a challenging problem that seeks to identify independent motions in two or several input images. This paper introduces the first algorithm for motion segmentation that relies on adiabatic quantum optimization of the objective function. The proposed method achieves on-par performance with the state of the art on problem instances which can be mapped to modern quantum annealers.