 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Temporal Action Localization Through Textual Guidance
May 21, 2026Zero-shot temporal action localization (ZS-TAL) consists of classifying and localizing actions in untrimmed videos, where action classes are unseen at training time. Existing work uses Vision and Language Models (VLMs), taking advantage of their strong zero-shot transfer capabilities. Yet, these models face evident challenges with fine-grained action classification, making it difficult to directly use them to distinguish between the presence and absence of an action. Most current methods for ZS-TAL address these challenges by training models on large-scale video datasets, which require annotated data and often result in limited generalization performance. Recently, approaches discarding the use of labeled data have emerged as an alternative. Following this direction, we propose a novel approach, ``Textual Guidance for finer localization of actions in videos'' (TEGU), that compensates for the lack of supervision from training data by exploiting rich textual information derived from large language models and structured text extracted from captions. This additional linguistic context can improve fine-grained discrimination by providing richer cues about fine-grained action differences within videos. We validate the effectiveness of the proposed method by conducting experiments on the THUMOS14 and the ActivityNet-v1.3 datasets. Our results show that, by exploiting rich textual information for improved action localization, TEGU outperforms state-of-the-art ZS-TAL approaches that do not involve training
Towards Unconstrained Human-Object Interaction
Apr 15, 2026Human-Object Interaction (HOI) detection is a longstanding computer vision problem concerned with predicting the interaction between humans and objects. Current HOI models rely on a vocabulary of interactions at training and inference time, limiting their applicability to static environments. With the advent of Multimodal Large Language Models (MLLMs), it has become feasible to explore more flexible paradigms for interaction recognition. In this work, we revisit HOI detection through the lens of MLLMs and apply them to in-the-wild HOI detection. We define the Unconstrained HOI (U-HOI) task, a novel HOI domain that removes the requirement for a predefined list of interactions at both training and inference. We evaluate a range of MLLMs on this setting and introduce a pipeline that includes test-time inference and language-to-graph conversion to extract structured interactions from free-form text. Our findings highlight the limitations of current HOI detectors and the value of MLLMs for U-HOI. Code will be available at https://github.com/francescotonini/anyhoi
Specificity-aware reinforcement learning for fine-grained open-world classification
Mar 04, 2026Classifying fine-grained visual concepts under open-world settings, i.e., without a predefined label set, demands models to be both accurate and specific. Recent reasoning Large Multimodal Models (LMMs) exhibit strong visual understanding capability but tend to produce overly generic predictions when performing fine-grained image classification. Our preliminary analysis reveals that models do possess the intrinsic fine-grained domain knowledge. However, promoting more specific predictions (specificity) without compromising correct ones (correctness) remains a non-trivial and understudied challenge. In this work, we investigate how to steer reasoning LMMs toward predictions that are both correct and specific. We propose a novel specificity-aware reinforcement learning framework, SpeciaRL, to fine-tune reasoning LMMs on fine-grained image classification under the open-world setting. SpeciaRL introduces a dynamic, verifier-based reward signal anchored to the best predictions within online rollouts, promoting specificity while respecting the model's capabilities to prevent incorrect predictions. Our out-of-domain experiments show that SpeciaRL delivers the best trade-off between correctness and specificity across extensive fine-grained benchmarks, surpassing existing methods and advancing open-world fine-grained image classification. Code and model are publicly available at https://github.com/s-angheben/SpeciaRL.
Large Multimodal Models as General In-Context Classifiers
Feb 26, 2026Which multimodal model should we use for classification? Previous studies suggest that the answer lies in CLIP-like contrastive Vision-Language Models (VLMs), due to their remarkable performance in zero-shot classification. In contrast, Large Multimodal Models (LMM) are more suitable for complex tasks. In this work, we argue that this answer overlooks an important capability of LMMs: in-context learning. We benchmark state-of-the-art LMMs on diverse datasets for closed-world classification and find that, although their zero-shot performance is lower than CLIP's, LMMs with a few in-context examples can match or even surpass contrastive VLMs with cache-based adapters, their "in-context" equivalent. We extend this analysis to the open-world setting, where the generative nature of LMMs makes them more suitable for the task. In this challenging scenario, LMMs struggle whenever provided with imperfect context information. To address this issue, we propose CIRCLE, a simple training-free method that assigns pseudo-labels to in-context examples, iteratively refining them with the available context itself. Through extensive experiments, we show that CIRCLE establishes a robust baseline for open-world classification, surpassing VLM counterparts and highlighting the potential of LMMs to serve as unified classifiers, and a flexible alternative to specialized models.
Dynamic Scoring with Enhanced Semantics for Training-Free Human-Object Interaction Detection
Jul 23, 2025



Human-Object Interaction (HOI) detection aims to identify humans and objects within images and interpret their interactions. Existing HOI methods rely heavily on large datasets with manual annotations to learn interactions from visual cues. These annotations are labor-intensive to create, prone to inconsistency, and limit scalability to new domains and rare interactions. We argue that recent advances in Vision-Language Models (VLMs) offer untapped potential, particularly in enhancing interaction representation. While prior work has injected such potential and even proposed training-free methods, there remain key gaps. Consequently, we propose a novel training-free HOI detection framework for Dynamic Scoring with enhanced semantics (DYSCO) that effectively utilizes textual and visual interaction representations within a multimodal registry, enabling robust and nuanced interaction understanding. This registry incorporates a small set of visual cues and uses innovative interaction signatures to improve the semantic alignment of verbs, facilitating effective generalization to rare interactions. Additionally, we propose a unique multi-head attention mechanism that adaptively weights the contributions of the visual and textual features. Experimental results demonstrate that our DYSCO surpasses training-free state-of-the-art models and is competitive with training-based approaches, particularly excelling in rare interactions. Code is available at https://github.com/francescotonini/dysco.
On Large Multimodal Models as Open-World Image Classifiers
Mar 27, 2025



Traditional image classification requires a predefined list of semantic categories. In contrast, Large Multimodal Models (LMMs) can sidestep this requirement by classifying images directly using natural language (e.g., answering the prompt "What is the main object in the image?"). Despite this remarkable capability, most existing studies on LMM classification performance are surprisingly limited in scope, often assuming a closed-world setting with a predefined set of categories. In this work, we address this gap by thoroughly evaluating LMM classification performance in a truly open-world setting. We first formalize the task and introduce an evaluation protocol, defining various metrics to assess the alignment between predicted and ground truth classes. We then evaluate 13 models across 10 benchmarks, encompassing prototypical, non-prototypical, fine-grained, and very fine-grained classes, demonstrating the challenges LMMs face in this task. Further analyses based on the proposed metrics reveal the types of errors LMMs make, highlighting challenges related to granularity and fine-grained capabilities, showing how tailored prompting and reasoning can alleviate them.
Compositional Caching for Training-free Open-vocabulary Attribute Detection
Mar 24, 2025Attribute detection is crucial for many computer vision tasks, as it enables systems to describe properties such as color, texture, and material. Current approaches often rely on labor-intensive annotation processes which are inherently limited: objects can be described at an arbitrary level of detail (e.g., color vs. color shades), leading to ambiguities when the annotators are not instructed carefully. Furthermore, they operate within a predefined set of attributes, reducing scalability and adaptability to unforeseen downstream applications. We present Compositional Caching (ComCa), a training-free method for open-vocabulary attribute detection that overcomes these constraints. ComCa requires only the list of target attributes and objects as input, using them to populate an auxiliary cache of images by leveraging web-scale databases and Large Language Models to determine attribute-object compatibility. To account for the compositional nature of attributes, cache images receive soft attribute labels. Those are aggregated at inference time based on the similarity between the input and cache images, refining the predictions of underlying Vision-Language Models (VLMs). Importantly, our approach is model-agnostic, compatible with various VLMs. Experiments on public datasets demonstrate that ComCa significantly outperforms zero-shot and cache-based baselines, competing with recent training-based methods, proving that a carefully designed training-free approach can successfully address open-vocabulary attribute detection.
Automatic benchmarking of large multimodal models via iterative experiment programming
Jun 18, 2024



Assessing the capabilities of large multimodal models (LMMs) often requires the creation of ad-hoc evaluations. Currently, building new benchmarks requires tremendous amounts of manual work for each specific analysis. This makes the evaluation process tedious and costly. In this paper, we present APEx, Automatic Programming of Experiments, the first framework for automatic benchmarking of LMMs. Given a research question expressed in natural language, APEx leverages a large language model (LLM) and a library of pre-specified tools to generate a set of experiments for the model at hand, and progressively compile a scientific report. The report drives the testing procedure: based on the current status of the investigation, APEx chooses which experiments to perform and whether the results are sufficient to draw conclusions. Finally, the LLM refines the report, presenting the results to the user in natural language. Thanks to its modularity, our framework is flexible and extensible as new tools become available. Empirically, APEx reproduces the findings of existing studies while allowing for arbitrary analyses and hypothesis testing.
Vocabulary-free Image Classification and Semantic Segmentation
Apr 16, 2024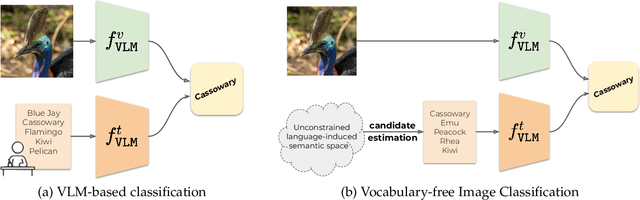
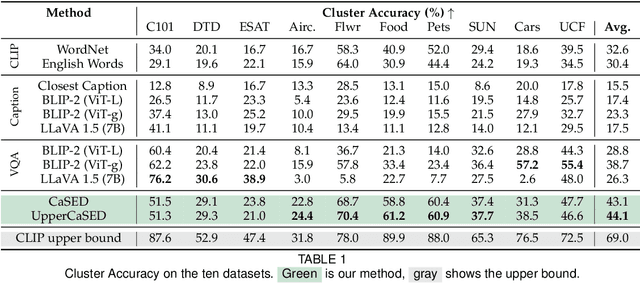
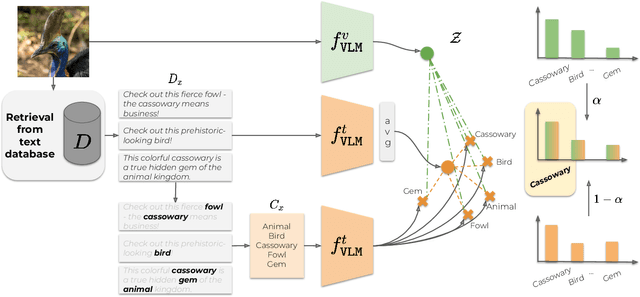
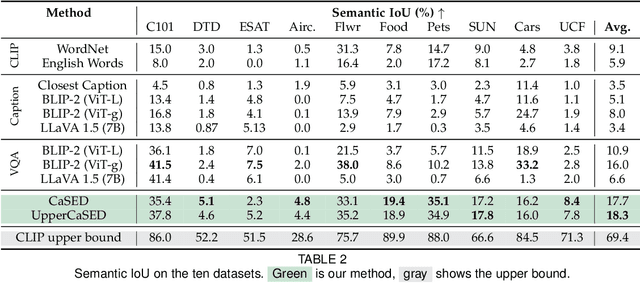
Large vision-language models revolutionized image classification and semantic segmentation paradigms. However, they typically assume a pre-defined set of categories, or vocabulary, at test time for composing textual prompts. This assumption is impractical in scenarios with unknown or evolving semantic context. Here, we address this issue and introduce the Vocabulary-free Image Classification (VIC) task, which aims to assign a class from an unconstrained language-induced semantic space to an input image without needing a known vocabulary. VIC is challenging due to the vastness of the semantic space, which contains millions of concepts, including fine-grained categories. To address VIC, we propose Category Search from External Databases (CaSED), a training-free method that leverages a pre-trained vision-language model and an external database. CaSED first extracts the set of candidate categories from the most semantically similar captions in the database and then assigns the image to the best-matching candidate category according to the same vision-language model. Furthermore, we demonstrate that CaSED can be applied locally to generate a coarse segmentation mask that classifies image regions, introducing the task of Vocabulary-free Semantic Segmentation. CaSED and its variants outperform other more complex vision-language models, on classification and semantic segmentation benchmarks, while using much fewer parameters.
Socially Pertinent Robots in Gerontological Healthcare
Apr 11, 2024
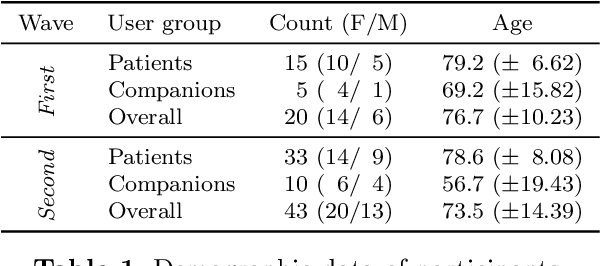
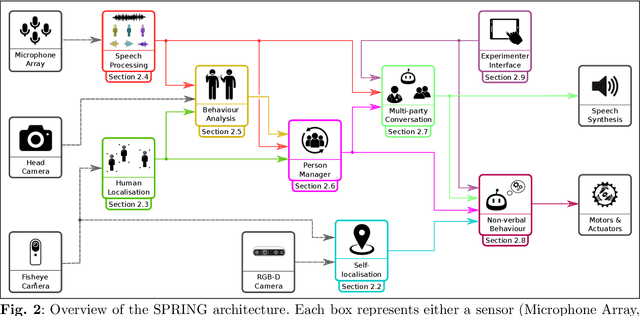
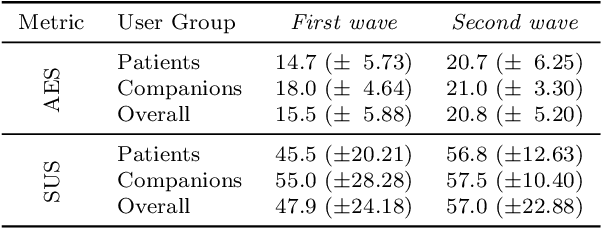
Despite the many recent achievements in developing and deploying social robotics, there are still many underexplored environments and applications for which systematic evaluation of such systems by end-users is necessary. While several robotic platforms have been used in gerontological healthcare, the question of whether or not a social interactive robot with multi-modal conversational capabilities will be useful and accepted in real-life facilities is yet to be answered. This paper is an attempt to partially answer this question, via two waves of experiments with patients and companions in a day-care gerontological facility in Paris with a full-sized humanoid robot endowed with social and conversational interaction capabilities. The software architecture, developed during the H2020 SPRING project, together with the experimental protocol, allowed us to evaluate the acceptability (AES) and usability (SUS) with more than 60 end-users. Overall, the users are receptive to this technology, especially when the robot perception and action skills are robust to environmental clutter and flexible to handle a plethora of different interactions.