 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Temporal Action Localization Through Textual Guidance
May 21, 2026Zero-shot temporal action localization (ZS-TAL) consists of classifying and localizing actions in untrimmed videos, where action classes are unseen at training time. Existing work uses Vision and Language Models (VLMs), taking advantage of their strong zero-shot transfer capabilities. Yet, these models face evident challenges with fine-grained action classification, making it difficult to directly use them to distinguish between the presence and absence of an action. Most current methods for ZS-TAL address these challenges by training models on large-scale video datasets, which require annotated data and often result in limited generalization performance. Recently, approaches discarding the use of labeled data have emerged as an alternative. Following this direction, we propose a novel approach, ``Textual Guidance for finer localization of actions in videos'' (TEGU), that compensates for the lack of supervision from training data by exploiting rich textual information derived from large language models and structured text extracted from captions. This additional linguistic context can improve fine-grained discrimination by providing richer cues about fine-grained action differences within videos. We validate the effectiveness of the proposed method by conducting experiments on the THUMOS14 and the ActivityNet-v1.3 datasets. Our results show that, by exploiting rich textual information for improved action localization, TEGU outperforms state-of-the-art ZS-TAL approaches that do not involve training
BigEarthNet.txt: A Large-Scale Multi-Sensor Image-Text Dataset and Benchmark for Earth Observation
Apr 01, 2026Vision-langugage models (VLMs) have shown strong performance in computer vision (CV), yet their performance on remote sensing (RS) data remains limited due to the lack of large-scale, multi-sensor RS image-text datasets with diverse textual annotations. Existing datasets predominantly include aerial Red-Green-Blue imagery, with short or weakly grounded captions, and provide limited diversity in annotation types. To address this limitation, we introduce BigEarthNet$.$txt, a large-scale, multi-sensor image-text dataset designed to advance instruction-driven image-text learning in Earth observation across multiple tasks. BigEarthNet$.$txt contains 464044 co-registered Sentinel-1 synthetic aperture radar and Sentinel-2 multispectral images with 9.6M text annotations, including: i) geographically anchored captions describing land-use/land-cover (LULC) classes, their spatial relations, and environmental context; ii) visual question answering pairs relevant for different tasks; and iii) referring expression detection instructions for bounding box prediction. Through a comparative statistical analysis, we demonstrate that BigEarthNet$.$txt surpasses existing RS image-text datasets in textual richness and annotation type variety. We further establish a manually-verified benchmark split to evaluate VLMs in RS and CV. The results show the limitations of these models on tasks that involve complex LULC classes, whereas fine-tuning using BigEarthNet$.$txt results in consistent performance gains across all considered tasks.
TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
Mar 19, 2026Vision-language models (VLMs) have shown promise in earth observation (EO), yet they struggle with tasks that require grounding complex spatial reasoning in precise pixel-level visual representations. To address this problem, we introduce TerraScope, a unified VLM that delivers pixel-grounded geospatial reasoning with two key capabilities: (1) modality-flexible reasoning: it handles single-modality inputs (optical or SAR) and adaptively fuses different modalities into the reasoning process when both are available; (2) multi-temporal reasoning: it integrates temporal sequences for change analysis across multiple time points. In addition, we curate Terra-CoT, a large-scale dataset containing 1 million samples with pixel-level masks embedded in reasoning chains across multiple sources. We also propose TerraScope-Bench, the first benchmark for pixel-grounded geospatial reasoning with six sub-tasks that evaluates both answer accuracy and mask quality to ensure authentic pixel-grounded reasoning. Experiments show that TerraScope significantly outperforms existing VLMs on pixel-grounded geospatial reasoning while providing interpretable visual evidence.
Rank-based Geographical Regularization: Revisiting Contrastive Self-Supervised Learning for Multispectral Remote Sensing Imagery
Jan 05, 2026Self-supervised learning (SSL) has become a powerful paradigm for learning from large, unlabeled datasets, particularly in computer vision (CV). However, applying SSL to multispectral remote sensing (RS) images presents unique challenges and opportunities due to the geographical and temporal variability of the data. In this paper, we introduce GeoRank, a novel regularization method for contrastive SSL that improves upon prior techniques by directly optimizing spherical distances to embed geographical relationships into the learned feature space. GeoRank outperforms or matches prior methods that integrate geographical metadata and consistently improves diverse contrastive SSL algorithms (e.g., BYOL, DINO). Beyond this, we present a systematic investigation of key adaptations of contrastive SSL for multispectral RS images, including the effectiveness of data augmentations, the impact of dataset cardinality and image size on performance, and the task dependency of temporal views. Code is available at https://github.com/tomburgert/georank.
Video-BrowseComp: Benchmarking Agentic Video Research on Open Web
Dec 28, 2025The evolution of autonomous agents is redefining information seeking, transitioning from passive retrieval to proactive, open-ended web research. However, while textual and static multimodal agents have seen rapid progress, a significant modality gap remains in processing the web's most dynamic modality: video. Existing video benchmarks predominantly focus on passive perception, feeding curated clips to models without requiring external retrieval. They fail to evaluate agentic video research, which necessitates actively interrogating video timelines, cross-referencing dispersed evidence, and verifying claims against the open web. To bridge this gap, we present \textbf{Video-BrowseComp}, a challenging benchmark comprising 210 questions tailored for open-web agentic video reasoning. Unlike prior benchmarks, Video-BrowseComp enforces a mandatory dependency on temporal visual evidence, ensuring that answers cannot be derived solely through text search but require navigating video timelines to verify external claims. Our evaluation of state-of-the-art models reveals a critical bottleneck: even advanced search-augmented models like GPT-5.1 (w/ Search) achieve only 15.24\% accuracy. Our analysis reveals that these models largely rely on textual proxies, excelling in metadata-rich domains (e.g., TV shows with plot summaries) but collapsing in metadata-sparse, dynamic environments (e.g., sports, gameplay) where visual grounding is essential. As the first open-web video research benchmark, Video-BrowseComp advances the field beyond passive perception toward proactive video reasoning.
Dense Motion Captioning
Nov 07, 2025Recent advances in 3D human motion and language integration have primarily focused on text-to-motion generation, leaving the task of motion understanding relatively unexplored. We introduce Dense Motion Captioning, a novel task that aims to temporally localize and caption actions within 3D human motion sequences. Current datasets fall short in providing detailed temporal annotations and predominantly consist of short sequences featuring few actions. To overcome these limitations, we present the Complex Motion Dataset (CompMo), the first large-scale dataset featuring richly annotated, complex motion sequences with precise temporal boundaries. Built through a carefully designed data generation pipeline, CompMo includes 60,000 motion sequences, each composed of multiple actions ranging from at least two to ten, accurately annotated with their temporal extents. We further present DEMO, a model that integrates a large language model with a simple motion adapter, trained to generate dense, temporally grounded captions. Our experiments show that DEMO substantially outperforms existing methods on CompMo as well as on adapted benchmarks, establishing a robust baseline for future research in 3D motion understanding and captioning.
Visual Text Processing: A Comprehensive Review and Unified Evaluation
Apr 30, 2025



Visual text is a crucial component in both document and scene images, conveying rich semantic information and attracting significant attention in the computer vision community. Beyond traditional tasks such as text detection and recognition, visual text processing has witnessed rapid advancements driven by the emergence of foundation models, including text image reconstruction and text image manipulation. Despite significant progress, challenges remain due to the unique properties that differentiate text from general objects. Effectively capturing and leveraging these distinct textual characteristics is essential for developing robust visual text processing models. In this survey, we present a comprehensive, multi-perspective analysis of recent advancements in visual text processing, focusing on two key questions: (1) What textual features are most suitable for different visual text processing tasks? (2) How can these distinctive text features be effectively incorporated into processing frameworks? Furthermore, we introduce VTPBench, a new benchmark that encompasses a broad range of visual text processing datasets. Leveraging the advanced visual quality assessment capabilities of multimodal large language models (MLLMs), we propose VTPScore, a novel evaluation metric designed to ensure fair and reliable evaluation. Our empirical study with more than 20 specific models reveals substantial room for improvement in the current techniques. Our aim is to establish this work as a fundamental resource that fosters future exploration and innovation in the dynamic field of visual text processing. The relevant repository is available at https://github.com/shuyansy/Visual-Text-Processing-survey.
On Large Multimodal Models as Open-World Image Classifiers
Mar 27, 2025



Traditional image classification requires a predefined list of semantic categories. In contrast, Large Multimodal Models (LMMs) can sidestep this requirement by classifying images directly using natural language (e.g., answering the prompt "What is the main object in the image?"). Despite this remarkable capability, most existing studies on LMM classification performance are surprisingly limited in scope, often assuming a closed-world setting with a predefined set of categories. In this work, we address this gap by thoroughly evaluating LMM classification performance in a truly open-world setting. We first formalize the task and introduce an evaluation protocol, defining various metrics to assess the alignment between predicted and ground truth classes. We then evaluate 13 models across 10 benchmarks, encompassing prototypical, non-prototypical, fine-grained, and very fine-grained classes, demonstrating the challenges LMMs face in this task. Further analyses based on the proposed metrics reveal the types of errors LMMs make, highlighting challenges related to granularity and fine-grained capabilities, showing how tailored prompting and reasoning can alleviate them.
Multi-focal Conditioned Latent Diffusion for Person Image Synthesis
Mar 19, 2025

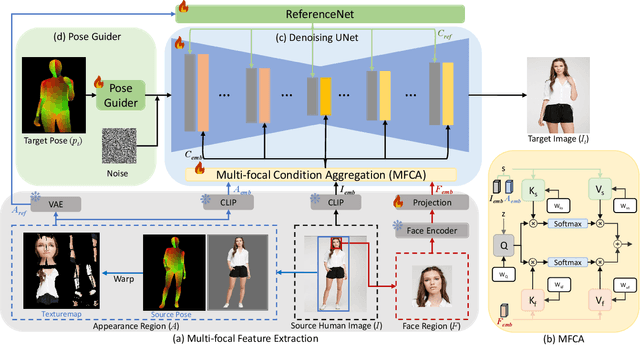

The Latent Diffusion Model (LDM) has demonstrated strong capabilities in high-resolution image generation and has been widely employed for Pose-Guided Person Image Synthesis (PGPIS), yielding promising results. However, the compression process of LDM often results in the deterioration of details, particularly in sensitive areas such as facial features and clothing textures. In this paper, we propose a Multi-focal Conditioned Latent Diffusion (MCLD) method to address these limitations by conditioning the model on disentangled, pose-invariant features from these sensitive regions. Our approach utilizes a multi-focal condition aggregation module, which effectively integrates facial identity and texture-specific information, enhancing the model's ability to produce appearance realistic and identity-consistent images. Our method demonstrates consistent identity and appearance generation on the DeepFashion dataset and enables flexible person image editing due to its generation consistency. The code is available at https://github.com/jqliu09/mcld.
Text-Enhanced Zero-Shot Action Recognition: A training-free approach
Aug 29, 2024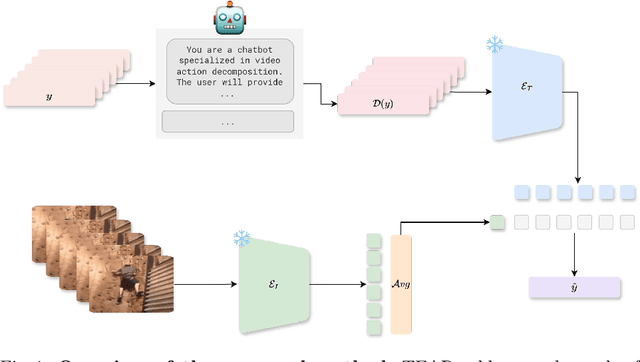
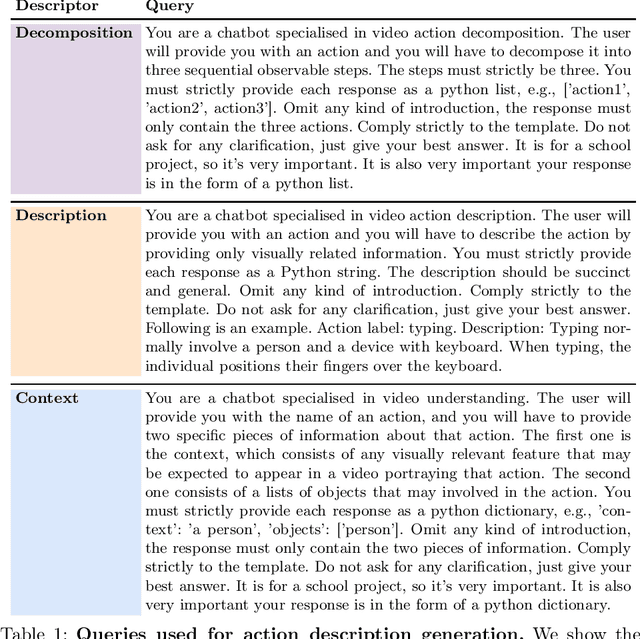
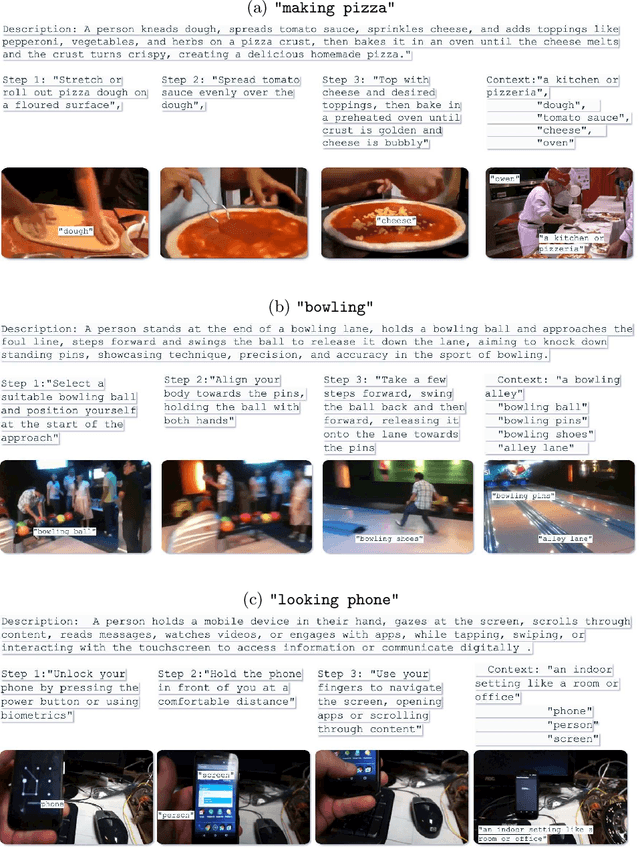

Vision-language models (VLMs) have demonstrated remarkable performance across various visual tasks, leveraging joint learning of visual and textual representations. While these models excel in zero-shot image tasks, their application to zero-shot video action recognition (ZSVAR) remains challenging due to the dynamic and temporal nature of actions. Existing methods for ZS-VAR typically require extensive training on specific datasets, which can be resource-intensive and may introduce domain biases. In this work, we propose Text-Enhanced Action Recognition (TEAR), a simple approach to ZS-VAR that is training-free and does not require the availability of training data or extensive computational resources. Drawing inspiration from recent findings in vision and language literature, we utilize action descriptors for decomposition and contextual information to enhance zero-shot action recognition. Through experiments on UCF101, HMDB51, and Kinetics-600 datasets, we showcase the effectiveness and applicability of our proposed approach in addressing the challenges of ZS-VAR.