 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-BrowseComp: Benchmarking Agentic Video Research on Open Web
Dec 28, 2025The evolution of autonomous agents is redefining information seeking, transitioning from passive retrieval to proactive, open-ended web research. However, while textual and static multimodal agents have seen rapid progress, a significant modality gap remains in processing the web's most dynamic modality: video. Existing video benchmarks predominantly focus on passive perception, feeding curated clips to models without requiring external retrieval. They fail to evaluate agentic video research, which necessitates actively interrogating video timelines, cross-referencing dispersed evidence, and verifying claims against the open web. To bridge this gap, we present \textbf{Video-BrowseComp}, a challenging benchmark comprising 210 questions tailored for open-web agentic video reasoning. Unlike prior benchmarks, Video-BrowseComp enforces a mandatory dependency on temporal visual evidence, ensuring that answers cannot be derived solely through text search but require navigating video timelines to verify external claims. Our evaluation of state-of-the-art models reveals a critical bottleneck: even advanced search-augmented models like GPT-5.1 (w/ Search) achieve only 15.24\% accuracy. Our analysis reveals that these models largely rely on textual proxies, excelling in metadata-rich domains (e.g., TV shows with plot summaries) but collapsing in metadata-sparse, dynamic environments (e.g., sports, gameplay) where visual grounding is essential. As the first open-web video research benchmark, Video-BrowseComp advances the field beyond passive perception toward proactive video reasoning.
Fleming-R1: Toward Expert-Level Medical Reasoning via Reinforcement Learning
Sep 18, 2025While large language models show promise in medical applications, achieving expert-level clinical reasoning remains challenging due to the need for both accurate answers and transparent reasoning processes. To address this challenge, we introduce Fleming-R1, a model designed for verifiable medical reasoning through three complementary innovations. First, our Reasoning-Oriented Data Strategy (RODS) combines curated medical QA datasets with knowledge-graph-guided synthesis to improve coverage of underrepresented diseases, drugs, and multi-hop reasoning chains. Second, we employ Chain-of-Thought (CoT) cold start to distill high-quality reasoning trajectories from teacher models, establishing robust inference priors. Third, we implement a two-stage Reinforcement Learning from Verifiable Rewards (RLVR) framework using Group Relative Policy Optimization, which consolidates core reasoning skills while targeting persistent failure modes through adaptive hard-sample mining. Across diverse medical benchmarks, Fleming-R1 delivers substantial parameter-efficient improvements: the 7B variant surpasses much larger baselines, while the 32B model achieves near-parity with GPT-4o and consistently outperforms strong open-source alternatives. These results demonstrate that structured data design, reasoning-oriented initialization, and verifiable reinforcement learning can advance clinical reasoning beyond simple accuracy optimization. We release Fleming-R1 publicly to promote transparent, reproducible, and auditable progress in medical AI, enabling safer deployment in high-stakes clinical environments.
Video-XL-2: Towards Very Long-Video Understanding Through Task-Aware KV Sparsification
Jun 24, 2025Multi-modal large language models (MLLMs) models have made significant progress in video understanding over the past few years. However, processing long video inputs remains a major challenge due to high memory and computational costs. This makes it difficult for current models to achieve both strong performance and high efficiency in long video understanding. To address this challenge, we propose Video-XL-2, a novel MLLM that delivers superior cost-effectiveness for long-video understanding based on task-aware KV sparsification. The proposed framework operates with two key steps: chunk-based pre-filling and bi-level key-value decoding. Chunk-based pre-filling divides the visual token sequence into chunks, applying full attention within each chunk and sparse attention across chunks. This significantly reduces computational and memory overhead. During decoding, bi-level key-value decoding selectively reloads either dense or sparse key-values for each chunk based on its relevance to the task. This approach further improves memory efficiency and enhances the model's ability to capture fine-grained information. Video-XL-2 achieves state-of-the-art performance on various long video understanding benchmarks, outperforming existing open-source lightweight models. It also demonstrates exceptional efficiency, capable of processing over 10,000 frames on a single NVIDIA A100 (80GB) GPU and thousands of frames in just a few seconds.
When Semantics Mislead Vision: Mitigating Large Multimodal Models Hallucinations in Scene Text Spotting and Understanding
Jun 05, 2025



Large Multimodal Models (LMMs) have achieved impressive progress in visual perception and reasoning. However, when confronted with visually ambiguous or non-semantic scene text, they often struggle to accurately spot and understand the content, frequently generating semantically plausible yet visually incorrect answers, which we refer to as semantic hallucination. In this work, we investigate the underlying causes of semantic hallucination and identify a key finding: Transformer layers in LLM with stronger attention focus on scene text regions are less prone to producing semantic hallucinations. Thus, we propose a training-free semantic hallucination mitigation framework comprising two key components: (1) ZoomText, a coarse-to-fine strategy that identifies potential text regions without external detectors; and (2) Grounded Layer Correction, which adaptively leverages the internal representations from layers less prone to hallucination to guide decoding, correcting hallucinated outputs for non-semantic samples while preserving the semantics of meaningful ones. To enable rigorous evaluation, we introduce TextHalu-Bench, a benchmark of over 1,730 samples spanning both semantic and non-semantic cases, with manually curated question-answer pairs designed to probe model hallucinations. Extensive experiments demonstrate that our method not only effectively mitigates semantic hallucination but also achieves strong performance on public benchmarks for scene text spotting and understanding.
VidText: Towards Comprehensive Evaluation for Video Text Understanding
May 28, 2025Visual texts embedded in videos carry rich semantic information, which is crucial for both holistic video understanding and fine-grained reasoning about local human actions. However, existing video understanding benchmarks largely overlook textual information, while OCR-specific benchmarks are constrained to static images, limiting their ability to capture the interaction between text and dynamic visual contexts. To address this gap, we propose VidText, a new benchmark designed for comprehensive and in-depth evaluation of video text understanding. VidText offers the following key features: 1) It covers a wide range of real-world scenarios and supports multilingual content, encompassing diverse settings where video text naturally appears. 2) It introduces a hierarchical evaluation framework with video-level, clip-level, and instance-level tasks, enabling assessment of both global summarization and local retrieval capabilities. 3) The benchmark also introduces a set of paired perception reasoning tasks, ranging from visual text perception to cross-modal reasoning between textual and visual information. Extensive experiments on 18 state-of-the-art Large Multimodal Models (LMMs) reveal that current models struggle across most tasks, with significant room for improvement. Further analysis highlights the impact of both model-intrinsic factors, such as input resolution and OCR capability, and external factors, including the use of auxiliary information and Chain-of-Thought reasoning strategies. We hope VidText will fill the current gap in video understanding benchmarks and serve as a foundation for future research on multimodal reasoning with video text in dynamic environments.
Visual Text Processing: A Comprehensive Review and Unified Evaluation
Apr 30, 2025



Visual text is a crucial component in both document and scene images, conveying rich semantic information and attracting significant attention in the computer vision community. Beyond traditional tasks such as text detection and recognition, visual text processing has witnessed rapid advancements driven by the emergence of foundation models, including text image reconstruction and text image manipulation. Despite significant progress, challenges remain due to the unique properties that differentiate text from general objects. Effectively capturing and leveraging these distinct textual characteristics is essential for developing robust visual text processing models. In this survey, we present a comprehensive, multi-perspective analysis of recent advancements in visual text processing, focusing on two key questions: (1) What textual features are most suitable for different visual text processing tasks? (2) How can these distinctive text features be effectively incorporated into processing frameworks? Furthermore, we introduce VTPBench, a new benchmark that encompasses a broad range of visual text processing datasets. Leveraging the advanced visual quality assessment capabilities of multimodal large language models (MLLMs), we propose VTPScore, a novel evaluation metric designed to ensure fair and reliable evaluation. Our empirical study with more than 20 specific models reveals substantial room for improvement in the current techniques. Our aim is to establish this work as a fundamental resource that fosters future exploration and innovation in the dynamic field of visual text processing. The relevant repository is available at https://github.com/shuyansy/Visual-Text-Processing-survey.
TextCtrl: Diffusion-based Scene Text Editing with Prior Guidance Control
Oct 14, 2024



Centred on content modification and style preservation, Scene Text Editing (STE) remains a challenging task despite considerable progress in text-to-image synthesis and text-driven image manipulation recently. GAN-based STE methods generally encounter a common issue of model generalization, while Diffusion-based STE methods suffer from undesired style deviations. To address these problems, we propose TextCtrl, a diffusion-based method that edits text with prior guidance control. Our method consists of two key components: (i) By constructing fine-grained text style disentanglement and robust text glyph structure representation, TextCtrl explicitly incorporates Style-Structure guidance into model design and network training, significantly improving text style consistency and rendering accuracy. (ii) To further leverage the style prior, a Glyph-adaptive Mutual Self-attention mechanism is proposed which deconstructs the implicit fine-grained features of the source image to enhance style consistency and vision quality during inference. Furthermore, to fill the vacancy of the real-world STE evaluation benchmark, we create the first real-world image-pair dataset termed ScenePair for fair comparisons. Experiments demonstrate the effectiveness of TextCtrl compared with previous methods concerning both style fidelity and text accuracy.
First Creating Backgrounds Then Rendering Texts: A New Paradigm for Visual Text Blending
Oct 14, 2024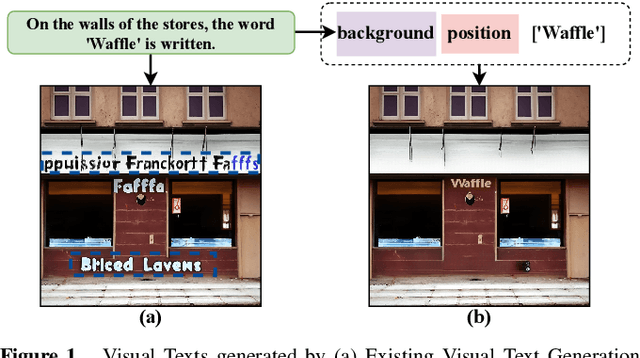

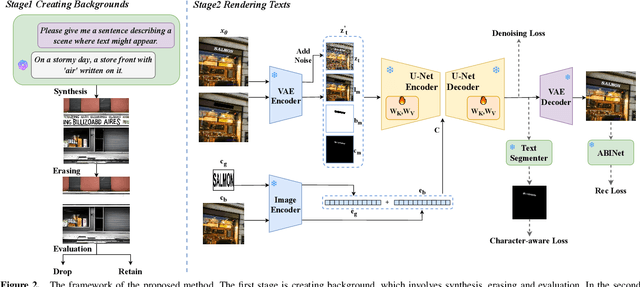
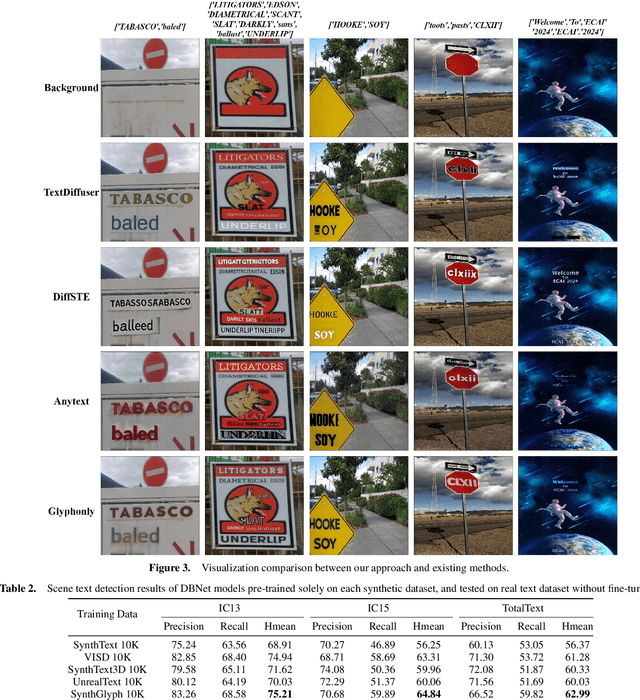
Diffusion models, known for their impressive image generation abilities, have played a pivotal role in the rise of visual text generation. Nevertheless, existing visual text generation methods often focus on generating entire images with text prompts, leading to imprecise control and limited practicality. A more promising direction is visual text blending, which focuses on seamlessly merging texts onto text-free backgrounds. However, existing visual text blending methods often struggle to generate high-fidelity and diverse images due to a shortage of backgrounds for synthesis and limited generalization capabilities. To overcome these challenges, we propose a new visual text blending paradigm including both creating backgrounds and rendering texts. Specifically, a background generator is developed to produce high-fidelity and text-free natural images. Moreover, a text renderer named GlyphOnly is designed for achieving visually plausible text-background integration. GlyphOnly, built on a Stable Diffusion framework, utilizes glyphs and backgrounds as conditions for accurate rendering and consistency control, as well as equipped with an adaptive text block exploration strategy for small-scale text rendering. We also explore several downstream applications based on our method, including scene text dataset synthesis for boosting scene text detectors, as well as text image customization and editing. Code and model will be available at \url{https://github.com/Zhenhang-Li/GlyphOnly}.
Video-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding
Sep 24, 2024


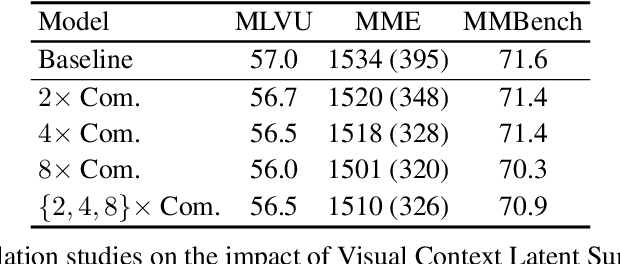
Although current Multi-modal Large Language Models (MLLMs) demonstrate promising results in video understanding, processing extremely long videos remains an ongoing challenge. Typically, MLLMs struggle with handling thousands of tokens that exceed the maximum context length of LLMs, and they experience reduced visual clarity due to token aggregation. Another challenge is the high computational cost stemming from the large number of video tokens. To tackle these issues, we propose Video-XL, an extra-long vision language model designed for efficient hour-scale video understanding. Specifically, we argue that LLMs can be adapted as effective visual condensers and introduce Visual Context Latent Summarization, which condenses visual contexts into highly compact forms. Extensive experiments demonstrate that our model achieves promising results on popular long video understanding benchmarks, despite being trained on limited image data. Moreover, Video-XL strikes a promising balance between efficiency and effectiveness, processing 1024 frames on a single 80GB GPU while achieving nearly 100\% accuracy in the Needle-in-a-Haystack evaluation. We envision Video-XL becoming a valuable tool for long video applications such as video summarization, surveillance anomaly detection, and Ad placement identification.
MLVU: A Comprehensive Benchmark for Multi-Task Long Video Understanding
Jun 06, 2024



The evaluation of Long Video Understanding (LVU) performance poses an important but challenging research problem. Despite previous efforts, the existing video understanding benchmarks are severely constrained by several issues, especially the insufficient lengths of videos, a lack of diversity in video types and evaluation tasks, and the inappropriateness for evaluating LVU performances. To address the above problems, we propose a new benchmark, called MLVU (Multi-task Long Video Understanding Benchmark), for the comprehensive and in-depth evaluation of LVU. MLVU presents the following critical values: 1) The substantial and flexible extension of video lengths, which enables the benchmark to evaluate LVU performance across a wide range of durations. 2) The inclusion of various video genres, e.g., movies, surveillance footage, egocentric videos, cartoons, game videos, etc., which reflects the models' LVU performances in different scenarios. 3) The development of diversified evaluation tasks, which enables a comprehensive examination of MLLMs' key abilities in long-video understanding. The empirical study with 20 latest MLLMs reveals significant room for improvement in today's technique, as all existing methods struggle with most of the evaluation tasks and exhibit severe performance degradation when handling longer videos. Additionally, it suggests that factors such as context length, image-understanding quality, and the choice of LLM backbone can play critical roles in future advancements. We anticipate that MLVU will advance the research of long video understanding by providing a comprehensive and in-depth analysis of MLLMs.