 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Training-Free Scene Text Editing
Mar 25, 2026Scene text editing seeks to modify textual content in natural images while maintaining visual realism and semantic consistency. Existing methods often require task-specific training or paired data, limiting their scalability and adaptability. In this paper, we propose TextFlow, a training-free scene text editing framework that integrates the strengths of Attention Boost (AttnBoost) and Flow Manifold Steering (FMS) to enable flexible, high-fidelity text manipulation without additional training. Specifically, FMS preserves the structural and style consistency by modeling the visual flow of characters and background regions, while AttnBoost enhances the rendering of textual content through attention-based guidance. By jointly leveraging these complementary modules, our approach performs end-to-end text editing through semantic alignment and spatial refinement in a plug-and-play manner. Extensive experiments demonstrate that our framework achieves visual quality and text accuracy comparable to or superior to those of training-based counterparts, generalizing well across diverse scenes and languages. This study advances scene text editing toward a more efficient, generalizable, and training-free paradigm. Code is available at https://github.com/lyb18758/TextFlow
MMTIT-Bench: A Multilingual and Multi-Scenario Benchmark with Cognition-Perception-Reasoning Guided Text-Image Machine Translation
Mar 25, 2026End-to-end text-image machine translation (TIMT), which directly translates textual content in images across languages, is crucial for real-world multilingual scene understanding. Despite advances in vision-language large models (VLLMs), robustness across diverse visual scenes and low-resource languages remains underexplored due to limited evaluation resources. We present MMTIT-Bench, a human-verified multilingual and multi-scenario benchmark with 1,400 images spanning fourteen non-English and non-Chinese languages and diverse settings such as documents, scenes, and web images, enabling rigorous assessment of end-to-end TIMT. Beyond benchmarking, we study how reasoning-oriented data design improves translation. Although recent VLLMs have begun to incorporate long Chain-of-Thought (CoT) reasoning, effective thinking paradigms for TIMT are still immature: existing designs either cascade parsing and translation in a sequential manner or focus on language-only reasoning, overlooking the visual cognition central to VLLMs. We propose Cognition-Perception-Reasoning for Translation (CPR-Trans), a data paradigm that integrates scene cognition, text perception, and translation reasoning within a unified reasoning process. Using a VLLM-driven data generation pipeline, CPR-Trans provides structured, interpretable supervision that aligns perception with reasoning. Experiments on 3B and 7B models show consistent gains in accuracy and interpretability. We will release MMTIT-Bench to promote the multilingual and multi-scenario TIMT research upon acceptance.
Towards Real-World Document Parsing via Realistic Scene Synthesis and Document-Aware Training
Mar 25, 2026Document parsing has recently advanced with multimodal large language models (MLLMs) that directly map document images to structured outputs. Traditional cascaded pipelines depend on precise layout analysis and often fail under casually captured or non-standard conditions. Although end-to-end approaches mitigate this dependency, they still exhibit repetitive, hallucinated, and structurally inconsistent predictions - primarily due to the scarcity of large-scale, high-quality full-page (document-level) end-to-end parsing data and the lack of structure-aware training strategies. To address these challenges, we propose a data-training co-design framework for robust end-to-end document parsing. A Realistic Scene Synthesis strategy constructs large-scale, structurally diverse full-page end-to-end supervision by composing layout templates with rich document elements, while a Document-Aware Training Recipe introduces progressive learning and structure-token optimization to enhance structural fidelity and decoding stability. We further build Wild-OmniDocBench, a benchmark derived from real-world captured documents for robustness evaluation. Integrated into a 1B-parameter MLLM, our method achieves superior accuracy and robustness across both scanned/digital and real-world captured scenarios. All models, data synthesis pipelines, and benchmarks will be publicly released to advance future research in document understanding.
Towards Natural Language-Based Document Image Retrieval: New Dataset and Benchmark
Dec 23, 2025Document image retrieval (DIR) aims to retrieve document images from a gallery according to a given query. Existing DIR methods are primarily based on image queries that retrieve documents within the same coarse semantic category, e.g., newspapers or receipts. However, these methods struggle to effectively retrieve document images in real-world scenarios where textual queries with fine-grained semantics are usually provided. To bridge this gap, we introduce a new Natural Language-based Document Image Retrieval (NL-DIR) benchmark with corresponding evaluation metrics. In this work, natural language descriptions serve as semantically rich queries for the DIR task. The NL-DIR dataset contains 41K authentic document images, each paired with five high-quality, fine-grained semantic queries generated and evaluated through large language models in conjunction with manual verification. We perform zero-shot and fine-tuning evaluations of existing mainstream contrastive vision-language models and OCR-free visual document understanding (VDU) models. A two-stage retrieval method is further investigated for performance improvement while achieving both time and space efficiency. We hope the proposed NL-DIR benchmark can bring new opportunities and facilitate research for the VDU community. Datasets and codes will be publicly available at huggingface.co/datasets/nianbing/NL-DIR.
Gather and Trace: Rethinking Video TextVQA from an Instance-oriented Perspective
Aug 06, 2025Video text-based visual question answering (Video TextVQA) aims to answer questions by explicitly reading and reasoning about the text involved in a video. Most works in this field follow a frame-level framework which suffers from redundant text entities and implicit relation modeling, resulting in limitations in both accuracy and efficiency. In this paper, we rethink the Video TextVQA task from an instance-oriented perspective and propose a novel model termed GAT (Gather and Trace). First, to obtain accurate reading result for each video text instance, a context-aggregated instance gathering module is designed to integrate the visual appearance, layout characteristics, and textual contents of the related entities into a unified textual representation. Then, to capture dynamic evolution of text in the video flow, an instance-focused trajectory tracing module is utilized to establish spatio-temporal relationships between instances and infer the final answer. Extensive experiments on several public Video TextVQA datasets validate the effectiveness and generalization of our framework. GAT outperforms existing Video TextVQA methods, video-language pretraining methods, and video large language models in both accuracy and inference speed. Notably, GAT surpasses the previous state-of-the-art Video TextVQA methods by 3.86\% in accuracy and achieves ten times of faster inference speed than video large language models. The source code is available at https://github.com/zhangyan-ucas/GAT.
When Semantics Mislead Vision: Mitigating Large Multimodal Models Hallucinations in Scene Text Spotting and Understanding
Jun 05, 2025



Large Multimodal Models (LMMs) have achieved impressive progress in visual perception and reasoning. However, when confronted with visually ambiguous or non-semantic scene text, they often struggle to accurately spot and understand the content, frequently generating semantically plausible yet visually incorrect answers, which we refer to as semantic hallucination. In this work, we investigate the underlying causes of semantic hallucination and identify a key finding: Transformer layers in LLM with stronger attention focus on scene text regions are less prone to producing semantic hallucinations. Thus, we propose a training-free semantic hallucination mitigation framework comprising two key components: (1) ZoomText, a coarse-to-fine strategy that identifies potential text regions without external detectors; and (2) Grounded Layer Correction, which adaptively leverages the internal representations from layers less prone to hallucination to guide decoding, correcting hallucinated outputs for non-semantic samples while preserving the semantics of meaningful ones. To enable rigorous evaluation, we introduce TextHalu-Bench, a benchmark of over 1,730 samples spanning both semantic and non-semantic cases, with manually curated question-answer pairs designed to probe model hallucinations. Extensive experiments demonstrate that our method not only effectively mitigates semantic hallucination but also achieves strong performance on public benchmarks for scene text spotting and understanding.
VidText: Towards Comprehensive Evaluation for Video Text Understanding
May 28, 2025Visual texts embedded in videos carry rich semantic information, which is crucial for both holistic video understanding and fine-grained reasoning about local human actions. However, existing video understanding benchmarks largely overlook textual information, while OCR-specific benchmarks are constrained to static images, limiting their ability to capture the interaction between text and dynamic visual contexts. To address this gap, we propose VidText, a new benchmark designed for comprehensive and in-depth evaluation of video text understanding. VidText offers the following key features: 1) It covers a wide range of real-world scenarios and supports multilingual content, encompassing diverse settings where video text naturally appears. 2) It introduces a hierarchical evaluation framework with video-level, clip-level, and instance-level tasks, enabling assessment of both global summarization and local retrieval capabilities. 3) The benchmark also introduces a set of paired perception reasoning tasks, ranging from visual text perception to cross-modal reasoning between textual and visual information. Extensive experiments on 18 state-of-the-art Large Multimodal Models (LMMs) reveal that current models struggle across most tasks, with significant room for improvement. Further analysis highlights the impact of both model-intrinsic factors, such as input resolution and OCR capability, and external factors, including the use of auxiliary information and Chain-of-Thought reasoning strategies. We hope VidText will fill the current gap in video understanding benchmarks and serve as a foundation for future research on multimodal reasoning with video text in dynamic environments.
Track the Answer: Extending TextVQA from Image to Video with Spatio-Temporal Clues
Dec 17, 2024



Video text-based visual question answering (Video TextVQA) is a practical task that aims to answer questions by jointly reasoning textual and visual information in a given video. Inspired by the development of TextVQA in image domain, existing Video TextVQA approaches leverage a language model (e.g. T5) to process text-rich multiple frames and generate answers auto-regressively. Nevertheless, the spatio-temporal relationships among visual entities (including scene text and objects) will be disrupted and models are susceptible to interference from unrelated information, resulting in irrational reasoning and inaccurate answering. To tackle these challenges, we propose the TEA (stands for ``\textbf{T}rack th\textbf{E} \textbf{A}nswer'') method that better extends the generative TextVQA framework from image to video. TEA recovers the spatio-temporal relationships in a complementary way and incorporates OCR-aware clues to enhance the quality of reasoning questions. Extensive experiments on several public Video TextVQA datasets validate the effectiveness and generalization of our framework. TEA outperforms existing TextVQA methods, video-language pretraining methods and video large language models by great margins.
Focus, Distinguish, and Prompt: Unleashing CLIP for Efficient and Flexible Scene Text Retrieval
Aug 01, 2024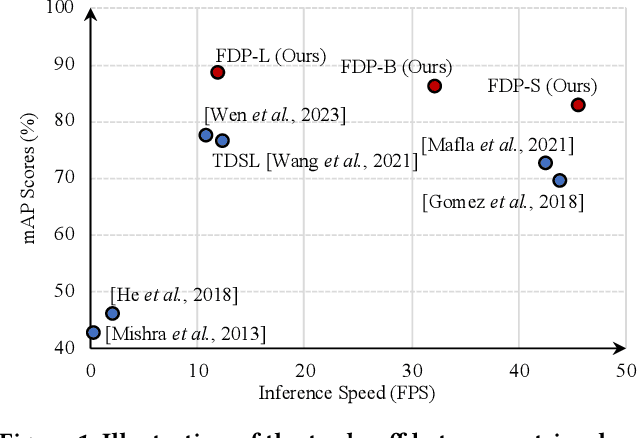
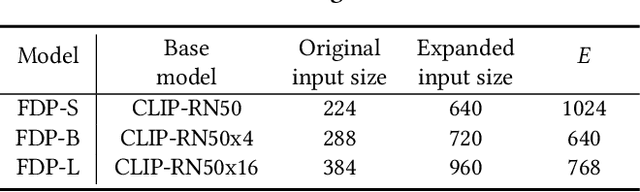


Scene text retrieval aims to find all images containing the query text from an image gallery. Current efforts tend to adopt an Optical Character Recognition (OCR) pipeline, which requires complicated text detection and/or recognition processes, resulting in inefficient and inflexible retrieval. Different from them, in this work we propose to explore the intrinsic potential of Contrastive Language-Image Pre-training (CLIP) for OCR-free scene text retrieval. Through empirical analysis, we observe that the main challenges of CLIP as a text retriever are: 1) limited text perceptual scale, and 2) entangled visual-semantic concepts. To this end, a novel model termed FDP (Focus, Distinguish, and Prompt) is developed. FDP first focuses on scene text via shifting the attention to the text area and probing the hidden text knowledge, and then divides the query text into content word and function word for processing, in which a semantic-aware prompting scheme and a distracted queries assistance module are utilized. Extensive experiments show that FDP significantly enhances the inference speed while achieving better or competitive retrieval accuracy compared to existing methods. Notably, on the IIIT-STR benchmark, FDP surpasses the state-of-the-art model by 4.37% with a 4 times faster speed. Furthermore, additional experiments under phrase-level and attribute-aware scene text retrieval settings validate FDP's particular advantages in handling diverse forms of query text. The source code will be publicly available at https://github.com/Gyann-z/FDP.
TextBlockV2: Towards Precise-Detection-Free Scene Text Spotting with Pre-trained Language Model
Mar 15, 2024Existing scene text spotters are designed to locate and transcribe texts from images. However, it is challenging for a spotter to achieve precise detection and recognition of scene texts simultaneously. Inspired by the glimpse-focus spotting pipeline of human beings and impressive performances of Pre-trained Language Models (PLMs) on visual tasks, we ask: 1) "Can machines spot texts without precise detection just like human beings?", and if yes, 2) "Is text block another alternative for scene text spotting other than word or character?" To this end, our proposed scene text spotter leverages advanced PLMs to enhance performance without fine-grained detection. Specifically, we first use a simple detector for block-level text detection to obtain rough positional information. Then, we finetune a PLM using a large-scale OCR dataset to achieve accurate recognition. Benefiting from the comprehensive language knowledge gained during the pre-training phase, the PLM-based recognition module effectively handles complex scenarios, including multi-line, reversed, occluded, and incomplete-detection texts. Taking advantage of the fine-tuned language model on scene recognition benchmarks and the paradigm of text block detection, extensive experiments demonstrate the superior performance of our scene text spotter across multiple public benchmarks. Additionally, we attempt to spot texts directly from an entire scene image to demonstrate the potential of PLMs, even Large Language Models (LLMs).