 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Escaping from Language Bias and OCR Error: Semantics-Centered Text Visual Question Answering
Paper and Code
Mar 24, 2022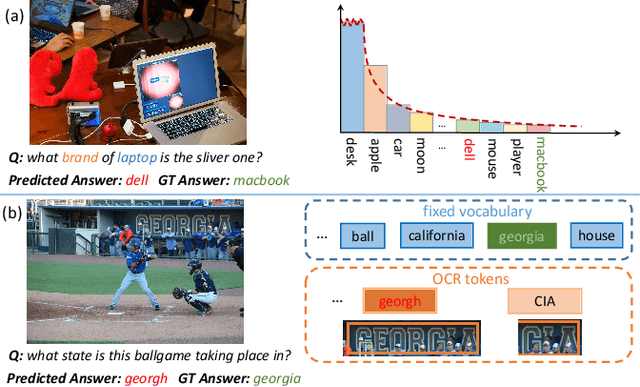

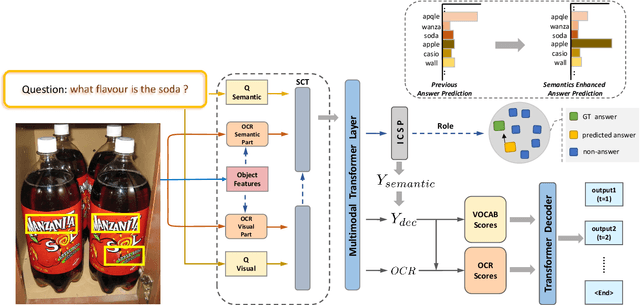

Texts in scene images convey critical information for scene understanding and reasoning. The abilities of reading and reasoning matter for the model in the text-based visual question answering (TextVQA) process. However, current TextVQA models do not center on the text and suffer from several limitations. The model is easily dominated by language biases and optical character recognition (OCR) errors due to the absence of semantic guidance in the answer prediction process. In this paper, we propose a novel Semantics-Centered Network (SC-Net) that consists of an instance-level contrastive semantic prediction module (ICSP) and a semantics-centered transformer module (SCT). Equipped with the two modules, the semantics-centered model can resist the language biases and the accumulated errors from OCR. Extensive experiments on TextVQA and ST-VQA datasets show the effectiveness of our model. SC-Net surpasses previous works with a noticeable margin and is more reasonable for the TextVQA task.