 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXaMCaP: Subset Selection with Entropy Gain Maximization for Probing Capability Gains of Large Chart Understanding Training Sets
Feb 04, 2026Recent works focus on synthesizing Chart Understanding (ChartU) training sets to inject advanced chart knowledge into Multimodal Large Language Models (MLLMs), where the sufficiency of the knowledge is typically verified by quantifying capability gains via the fine-tune-then-evaluate paradigm. However, full-set fine-tuning MLLMs to assess such gains incurs significant time costs, hindering the iterative refinement cycles of the ChartU dataset. Reviewing the ChartU dataset synthesis and data selection domains, we find that subsets can potentially probe the MLLMs' capability gains from full-set fine-tuning. Given that data diversity is vital for boosting MLLMs' performance and entropy reflects this feature, we propose EXaMCaP, which uses entropy gain maximization to select a subset. To obtain a high-diversity subset, EXaMCaP chooses the maximum-entropy subset from the large ChartU dataset. As enumerating all possible subsets is impractical, EXaMCaP iteratively selects samples to maximize the gain in set entropy relative to the current set, approximating the maximum-entropy subset of the full dataset. Experiments show that EXaMCaP outperforms baselines in probing the capability gains of the ChartU training set, along with its strong effectiveness across diverse subset sizes and compatibility with various MLLM architectures.
Separate and Locate: Rethink the Text in Text-based Visual Question Answering
Aug 31, 2023


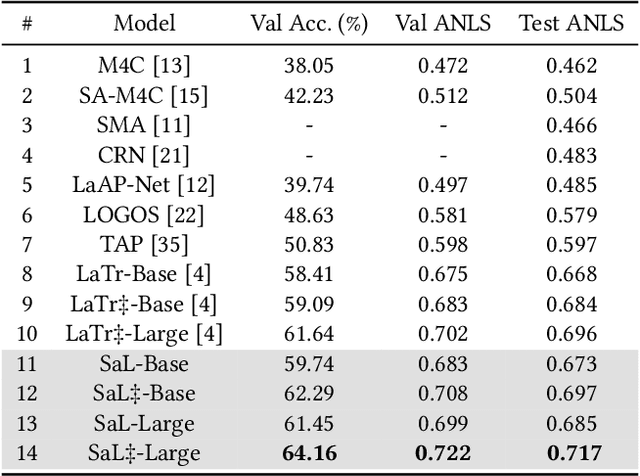
Text-based Visual Question Answering (TextVQA) aims at answering questions about the text in images. Most works in this field focus on designing network structures or pre-training tasks. All these methods list the OCR texts in reading order (from left to right and top to bottom) to form a sequence, which is treated as a natural language ``sentence''. However, they ignore the fact that most OCR words in the TextVQA task do not have a semantical contextual relationship. In addition, these approaches use 1-D position embedding to construct the spatial relation between OCR tokens sequentially, which is not reasonable. The 1-D position embedding can only represent the left-right sequence relationship between words in a sentence, but not the complex spatial position relationship. To tackle these problems, we propose a novel method named Separate and Locate (SaL) that explores text contextual cues and designs spatial position embedding to construct spatial relations between OCR texts. Specifically, we propose a Text Semantic Separate (TSS) module that helps the model recognize whether words have semantic contextual relations. Then, we introduce a Spatial Circle Position (SCP) module that helps the model better construct and reason the spatial position relationships between OCR texts. Our SaL model outperforms the baseline model by 4.44% and 3.96% accuracy on TextVQA and ST-VQA datasets. Compared with the pre-training state-of-the-art method pre-trained on 64 million pre-training samples, our method, without any pre-training tasks, still achieves 2.68% and 2.52% accuracy improvement on TextVQA and ST-VQA. Our code and models will be released at https://github.com/fangbufang/SaL.
CATS: A Pragmatic Chinese Answer-to-Sequence Dataset with Large Scale and High Quality
Jun 20, 2023There are three problems existing in the popular data-to-text datasets. First, the large-scale datasets either contain noise or lack real application scenarios. Second, the datasets close to real applications are relatively small in size. Last, current datasets bias in the English language while leaving other languages underexplored. To alleviate these limitations, in this paper, we present CATS, a pragmatic Chinese answer-to-sequence dataset with large scale and high quality. The dataset aims to generate textual descriptions for the answer in the practical TableQA system. Further, to bridge the structural gap between the input SQL and table and establish better semantic alignments, we propose a Unified Graph Transformation approach to establish a joint encoding space for the two hybrid knowledge resources and convert this task to a graph-to-text problem. The experiment results demonstrate the effectiveness of our proposed method. Further analysis on CATS attests to both the high quality and challenges of the dataset.
Plan-then-Seam: Towards Efficient Table-to-Text Generation
Feb 28, 2023
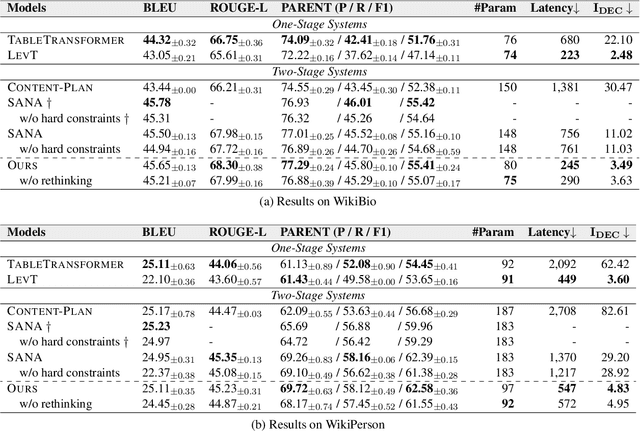
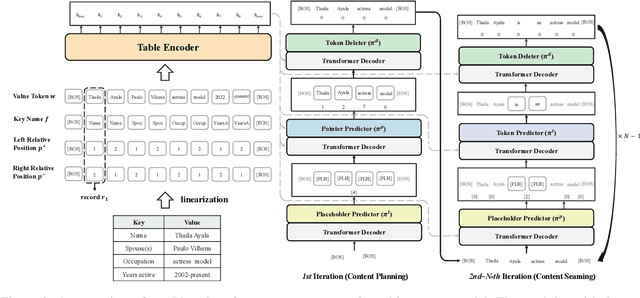

Table-to-text generation aims at automatically generating text to help people conveniently obtain salient information in tables. Recent works explicitly decompose the generation process into content planning and surface generation stages, employing two autoregressive networks for them respectively. However, they are computationally expensive due to the non-parallelizable nature of autoregressive decoding and the redundant parameters of two networks. In this paper, we propose the first totally non-autoregressive table-to-text model (Plan-then-Seam, PTS) that produces its outputs in parallel with one single network. PTS firstly writes and calibrates one plan of the content to be generated with a novel rethinking pointer predictor, and then takes the plan as the context for seaming to decode the description. These two steps share parameters and perform iteratively to capture token inter-dependency while keeping parallel decoding. Experiments on two public benchmarks show that PTS achieves 3.0~5.6 times speedup for inference time, reducing 50% parameters, while maintaining as least comparable performance against strong two-stage table-to-text competitors.
Towards Escaping from Language Bias and OCR Error: Semantics-Centered Text Visual Question Answering
Mar 24, 2022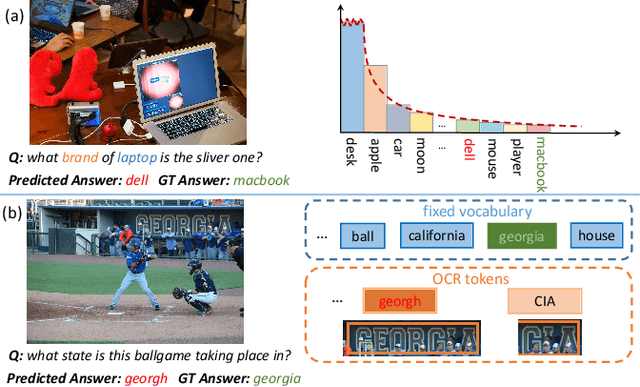

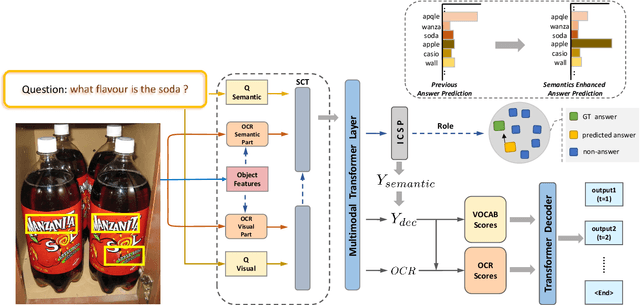

Texts in scene images convey critical information for scene understanding and reasoning. The abilities of reading and reasoning matter for the model in the text-based visual question answering (TextVQA) process. However, current TextVQA models do not center on the text and suffer from several limitations. The model is easily dominated by language biases and optical character recognition (OCR) errors due to the absence of semantic guidance in the answer prediction process. In this paper, we propose a novel Semantics-Centered Network (SC-Net) that consists of an instance-level contrastive semantic prediction module (ICSP) and a semantics-centered transformer module (SCT). Equipped with the two modules, the semantics-centered model can resist the language biases and the accumulated errors from OCR. Extensive experiments on TextVQA and ST-VQA datasets show the effectiveness of our model. SC-Net surpasses previous works with a noticeable margin and is more reasonable for the TextVQA task.