 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan-then-Seam: Towards Efficient Table-to-Text Generation
Paper and Code
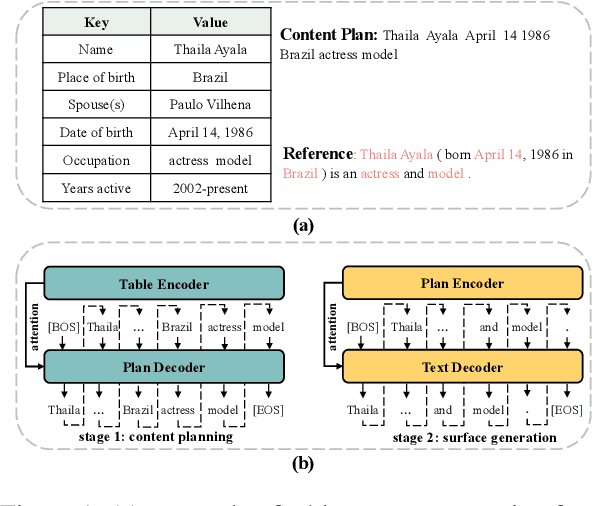
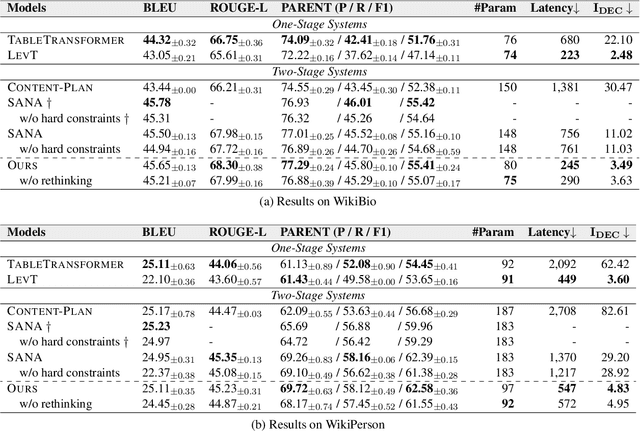
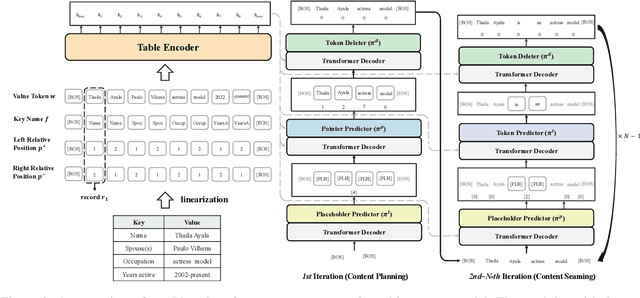

Table-to-text generation aims at automatically generating text to help people conveniently obtain salient information in tables. Recent works explicitly decompose the generation process into content planning and surface generation stages, employing two autoregressive networks for them respectively. However, they are computationally expensive due to the non-parallelizable nature of autoregressive decoding and the redundant parameters of two networks. In this paper, we propose the first totally non-autoregressive table-to-text model (Plan-then-Seam, PTS) that produces its outputs in parallel with one single network. PTS firstly writes and calibrates one plan of the content to be generated with a novel rethinking pointer predictor, and then takes the plan as the context for seaming to decode the description. These two steps share parameters and perform iteratively to capture token inter-dependency while keeping parallel decoding. Experiments on two public benchmarks show that PTS achieves 3.0~5.6 times speedup for inference time, reducing 50% parameters, while maintaining as least comparable performance against strong two-stage table-to-text competitors.