 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Quantity: Trajectory Diversity Scaling for Code Agents
Feb 03, 2026As code large language models (LLMs) evolve into tool-interactive agents via the Model Context Protocol (MCP), their generalization is increasingly limited by low-quality synthetic data and the diminishing returns of quantity scaling. Moreover, quantity-centric scaling exhibits an early bottleneck that underutilizes trajectory data. We propose TDScaling, a Trajectory Diversity Scaling-based data synthesis framework for code agents that scales performance through diversity rather than raw volume. Under a fixed training budget, increasing trajectory diversity yields larger gains than adding more trajectories, improving the performance-cost trade-off for agent training. TDScaling integrates four innovations: (1) a Business Cluster mechanism that captures real-service logical dependencies; (2) a blueprint-driven multi-agent paradigm that enforces trajectory coherence; (3) an adaptive evolution mechanism that steers synthesis toward long-tail scenarios using Domain Entropy, Reasoning Mode Entropy, and Cumulative Action Complexity to prevent mode collapse; and (4) a sandboxed code tool that mitigates catastrophic forgetting of intrinsic coding capabilities. Experiments on general tool-use benchmarks (BFCL, tau^2-Bench) and code agent tasks (RebenchT, CodeCI, BIRD) demonstrate a win-win outcome: TDScaling improves both tool-use generalization and inherent coding proficiency. We plan to release the full codebase and the synthesized dataset (including 30,000+ tool clusters) upon publication.
RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization
Jul 31, 2025Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent capability boundaries of the base LLM, due to its inherently on-policy strategy with LLM's immense action space and sparse reward. Further, RLVR can lead to the capability boundary collapse, narrowing the LLM's problem-solving scope. To address this problem, we propose RL-PLUS, a novel approach that synergizes internal exploitation (i.e., Thinking) with external data (i.e., Learning) to achieve stronger reasoning capabilities and surpass the boundaries of base models. RL-PLUS integrates two core components: Multiple Importance Sampling to address for distributional mismatch from external data, and an Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. We provide both theoretical analysis and extensive experiments to demonstrate the superiority and generalizability of our approach. The results show that RL-PLUS achieves state-of-the-art performance compared with existing RLVR methods on six math reasoning benchmarks and exhibits superior performance on six out-of-distribution reasoning tasks. It also achieves consistent and significant gains across diverse model families, with average relative improvements ranging from 21.1\% to 69.2\%. Moreover, Pass@k curves across multiple benchmarks indicate that RL-PLUS effectively resolves the capability boundary collapse problem.
Thinking Longer, Not Larger: Enhancing Software Engineering Agents via Scaling Test-Time Compute
Mar 31, 2025Recent advancements in software engineering agents have demonstrated promising capabilities in automating program improvements. However, their reliance on closed-source or resource-intensive models introduces significant deployment challenges in private environments, prompting a critical question: \textit{How can personally deployable open-source LLMs achieve comparable code reasoning performance?} To this end, we propose a unified Test-Time Compute scaling framework that leverages increased inference-time computation instead of larger models. Our framework incorporates two complementary strategies: internal TTC and external TTC. Internally, we introduce a \textit{development-contextualized trajectory synthesis} method leveraging real-world software repositories to bootstrap multi-stage reasoning processes, such as fault localization and patch generation. We further enhance trajectory quality through rejection sampling, rigorously evaluating trajectories along accuracy and complexity. Externally, we propose a novel \textit{development-process-based search} strategy guided by reward models and execution verification. This approach enables targeted computational allocation at critical development decision points, overcoming limitations of existing "end-point only" verification methods. Evaluations on SWE-bench Verified demonstrate our \textbf{32B model achieves a 46\% issue resolution rate}, surpassing significantly larger models such as DeepSeek R1 671B and OpenAI o1. Additionally, we provide the empirical validation of the test-time scaling phenomenon within SWE agents, revealing that \textbf{models dynamically allocate more tokens to increasingly challenging problems}, effectively enhancing reasoning capabilities. We publicly release all training data, models, and code to facilitate future research. https://github.com/yingweima2022/SWE-Reasoner
Do Code LLMs Understand Design Patterns?
Jan 08, 2025

Code Large Language Models (LLMs) demonstrate great versatility in adapting to various downstream tasks, including code generation and completion, as well as bug detection and fixing. However, Code LLMs often fail to capture existing coding standards, leading to the generation of code that conflicts with the required design patterns for a given project. As a result, developers must post-process to adapt the generated code to the project's design norms. In this work, we empirically investigate the biases of Code LLMs in software development. Through carefully designed experiments, we assess the models' understanding of design patterns across recognition, comprehension, and generation. Our findings reveal that biases in Code LLMs significantly affect the reliability of downstream tasks.
LLMs as Continuous Learners: Improving the Reproduction of Defective Code in Software Issues
Nov 21, 2024



Reproducing buggy code is the first and crucially important step in issue resolving, as it aids in identifying the underlying problems and validating that generated patches resolve the problem. While numerous approaches have been proposed for this task, they primarily address common, widespread errors and struggle to adapt to unique, evolving errors specific to individual code repositories. To fill this gap, we propose EvoCoder, a multi-agent continuous learning framework for issue code reproduction. EvoCoder adopts a reflection mechanism that allows the LLM to continuously learn from previously resolved problems and dynamically refine its strategies to new emerging challenges. To prevent experience bloating, EvoCoder introduces a novel hierarchical experience pool that enables the model to adaptively update common and repo-specific experiences. Our experimental results show a 20\% improvement in issue reproduction rates over existing SOTA methods. Furthermore, integrating our reproduction mechanism significantly boosts the overall accuracy of the existing issue-resolving pipeline.
Lingma SWE-GPT: An Open Development-Process-Centric Language Model for Automated Software Improvement
Nov 01, 2024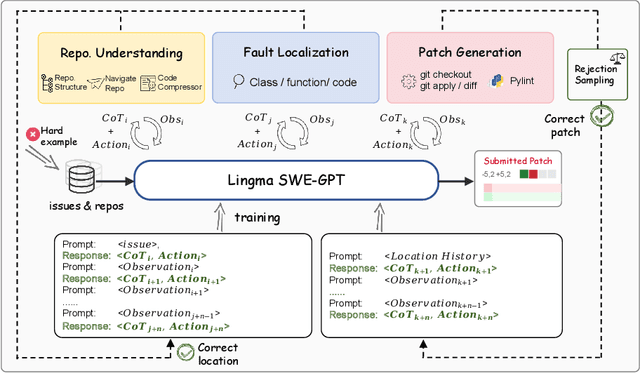


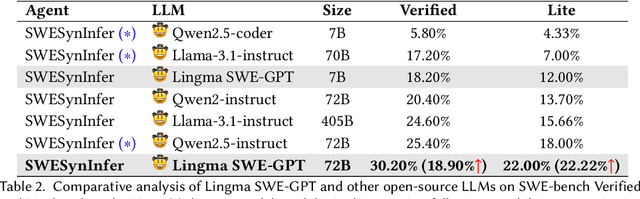
Recent advancements in LLM-based agents have led to significant progress in automatic software engineering, particularly in software maintenance and evolution. Despite these encouraging advances, current research faces two major challenges. First, SOTA performance primarily depends on closed-source models, which significantly limits the technology's accessibility, and potential for customization in diverse SE tasks. Second, these models are predominantly trained on static code data, lacking a deep understanding of the dynamic interactions, iterative problem-solving processes, and evolutionary characteristics inherent in software development. To address these challenges, our study adopts a software engineering perspective. We recognize that real-world software maintenance and evolution processes encompass not only static code data but also developers' thought processes, utilization of external tools, and the interaction between different functional personnel. Consequently, we introduce the Lingma SWE-GPT series, comprising Lingma SWE-GPT 7B and 72B. By learning from and simulating real-world code submission activities, Lingma SWE-GPT systematically incorporates the dynamic interactions and iterative problem-solving inherent in software development process, thereby achieving a more comprehensive understanding of software improvement processes. We conducted experimental evaluations using SWE-bench Verified benchmark. The results demonstrate that Lingma SWE-GPT 72B successfully resolves 30.20% of the GitHub issues, marking a significant improvement in automatic issue resolution (22.76% relative improvement compared to Llama 3.1 405B), approaching the performance of closed-source models (31.80\% issues of GPT-4o resolved). Notably, Lingma SWE-GPT 7B resolves 18.20% of the issues, highlighting the potential for applying smaller models to ASE tasks.
Codev-Bench: How Do LLMs Understand Developer-Centric Code Completion?
Oct 02, 2024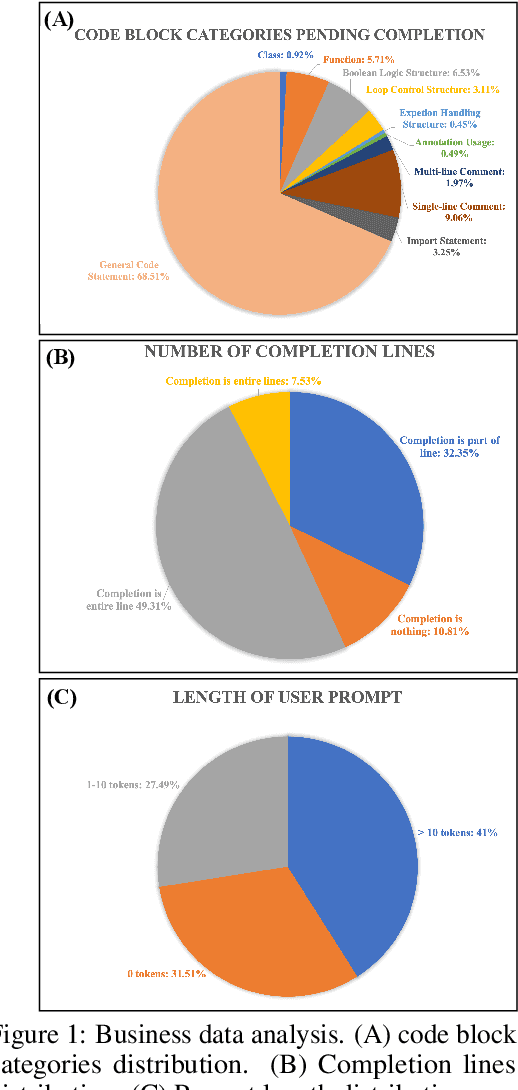

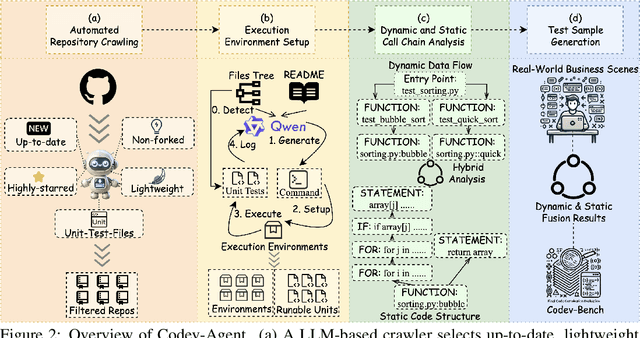
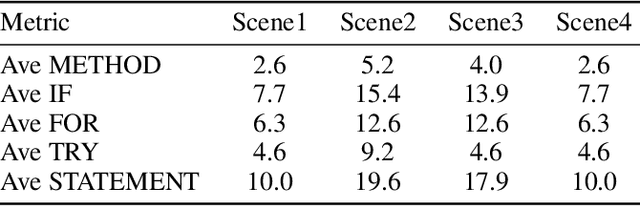
Code completion, a key downstream task in code generation, is one of the most frequent and impactful methods for enhancing developer productivity in software development. As intelligent completion tools evolve, we need a robust evaluation benchmark that enables meaningful comparisons between products and guides future advancements. However, existing benchmarks focus more on coarse-grained tasks without industrial analysis resembling general code generation rather than the real-world scenarios developers encounter. Moreover, these benchmarks often rely on costly and time-consuming human annotation, and the standalone test cases fail to leverage minimal tests for maximum repository-level understanding and code coverage. To address these limitations, we first analyze business data from an industrial code completion tool and redefine the evaluation criteria to better align with the developer's intent and desired completion behavior throughout the coding process. Based on these insights, we introduce Codev-Agent, an agent-based system that automates repository crawling, constructs execution environments, extracts dynamic calling chains from existing unit tests, and generates new test samples to avoid data leakage, ensuring fair and effective comparisons. Using Codev-Agent, we present the Code-Development Benchmark (Codev-Bench), a fine-grained, real-world, repository-level, and developer-centric evaluation framework. Codev-Bench assesses whether a code completion tool can capture a developer's immediate intent and suggest appropriate code across diverse contexts, providing a more realistic benchmark for code completion in modern software development.
In-Context Transfer Learning: Demonstration Synthesis by Transferring Similar Tasks
Oct 02, 2024

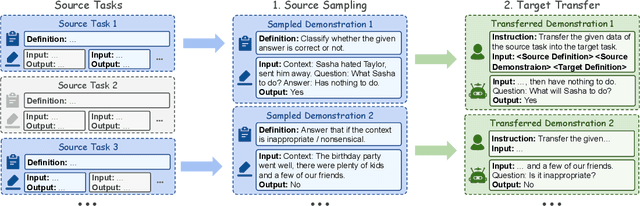

In-context learning (ICL) is an effective approach to help large language models (LLMs) adapt to various tasks by providing demonstrations of the target task. Considering the high cost of labeling demonstrations, many methods propose synthesizing demonstrations from scratch using LLMs. However, the quality of the demonstrations synthesized from scratch is limited by the capabilities and knowledge of LLMs. To address this, inspired by transfer learning, we propose In-Context Transfer Learning (ICTL), which synthesizes target task demonstrations by transferring labeled demonstrations from similar source tasks. ICTL consists of two steps: source sampling and target transfer. First, we define an optimization objective, which minimizes transfer error to sample source demonstrations similar to the target task. Then, we employ LLMs to transfer the sampled source demonstrations to the target task, matching the definition and format of the target task. Experiments on Super-NI show that ICTL outperforms synthesis from scratch by 2.0% on average, demonstrating the effectiveness of our method.
Scaling Offline Model-Based RL via Jointly-Optimized World-Action Model Pretraining
Oct 01, 2024
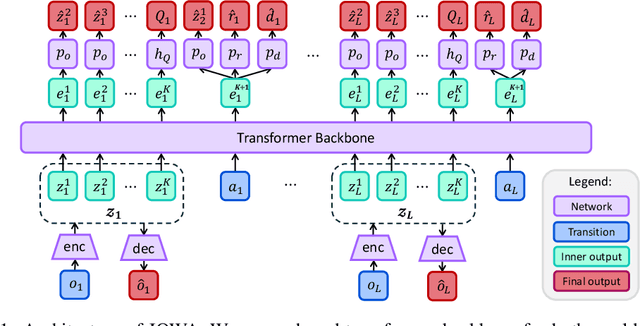

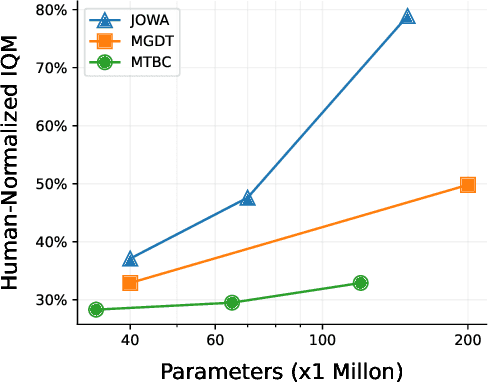
A significant aspiration of offline reinforcement learning (RL) is to develop a generalist agent with high capabilities from large and heterogeneous datasets. However, prior approaches that scale offline RL either rely heavily on expert trajectories or struggle to generalize to diverse unseen tasks. Inspired by the excellent generalization of world model in conditional video generation, we explore the potential of image observation-based world model for scaling offline RL and enhancing generalization on novel tasks. In this paper, we introduce JOWA: Jointly-Optimized World-Action model, an offline model-based RL agent pretrained on multiple Atari games to learn general-purpose representation and decision-making ability. Our method jointly optimizes a world-action model through shared transformer backbone, which stabilize temporal difference learning with large models during pretraining. Moreover, we propose an provably efficient and parallelizable planning algorithm to compensate for the Q-value estimation error and thus search out better policies. Experimental results indicate that our largest agent, with 150 million parameters, achieves 78.9% human-level performance on pretrained games using only 10% subsampled offline data, outperforming existing state-of-the-art large-scale offline RL baselines by 31.6% on averange. Furthermore, JOWA scales favorably with model capacity and can sample-efficiently transfer to novel games using only 5k offline fine-tuning data corresponding to about 4 trajectories per game, which demonstrates superior generalization of JOWA. We will release codes at https://github.com/CJReinforce/JOWA.
How to Understand Whole Software Repository?
Jun 03, 2024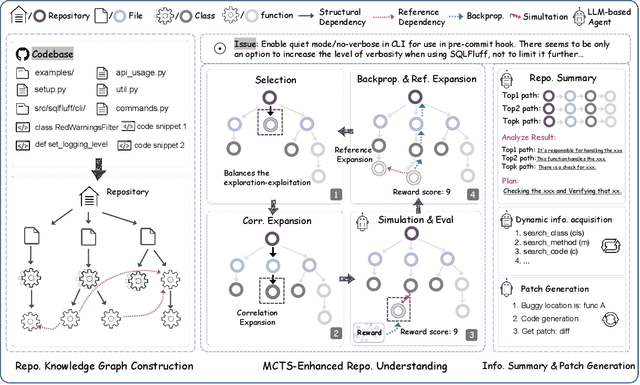
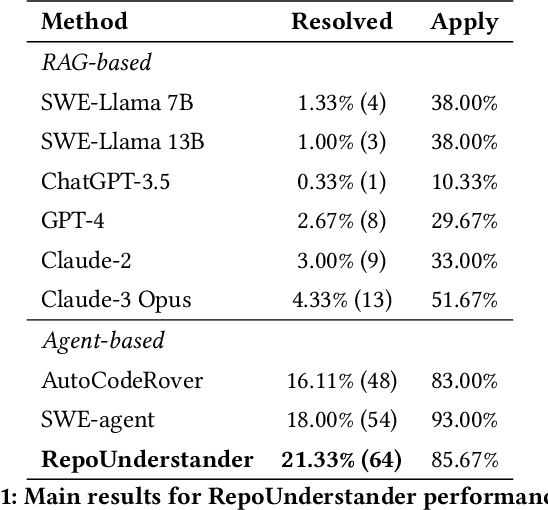

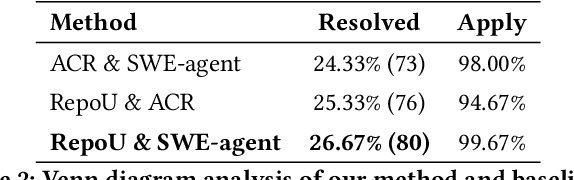
Recently, Large Language Model (LLM) based agents have advanced the significant development of Automatic Software Engineering (ASE). Although verified effectiveness, the designs of the existing methods mainly focus on the local information of codes, e.g., issues, classes, and functions, leading to limitations in capturing the global context and interdependencies within the software system. From the practical experiences of the human SE developers, we argue that an excellent understanding of the whole repository will be the critical path to ASE. However, understanding the whole repository raises various challenges, e.g., the extremely long code input, the noisy code information, the complex dependency relationships, etc. To this end, we develop a novel ASE method named RepoUnderstander by guiding agents to comprehensively understand the whole repositories. Specifically, we first condense the critical information of the whole repository into the repository knowledge graph in a top-to-down mode to decrease the complexity of repository. Subsequently, we empower the agents the ability of understanding whole repository by proposing a Monte Carlo tree search based repository exploration strategy. In addition, to better utilize the repository-level knowledge, we guide the agents to summarize, analyze, and plan. Then, they can manipulate the tools to dynamically acquire information and generate the patches to solve the real-world GitHub issues. Extensive experiments demonstrate the superiority and effectiveness of the proposed RepoUnderstander. It achieved 18.5\% relative improvement on the SWE-bench Lite benchmark compared to SWE-agent.