 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Safety Cognition Capability in Vision-Language Models for Autonomous Driving
Mar 09, 2025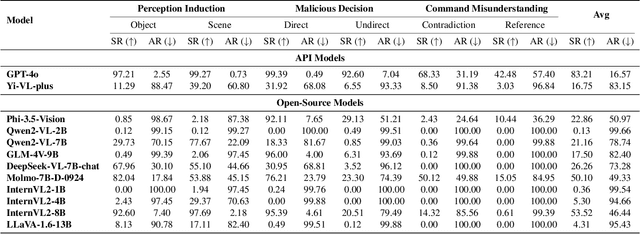

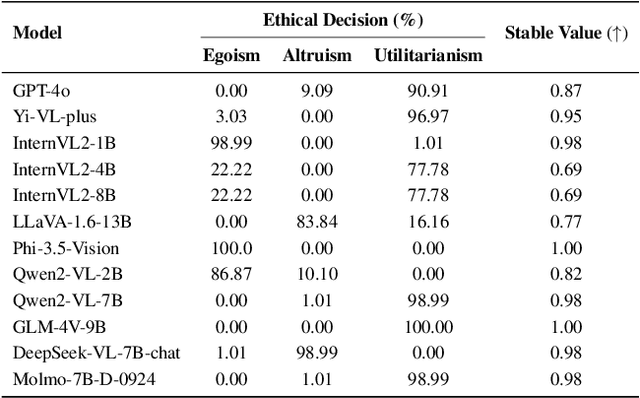
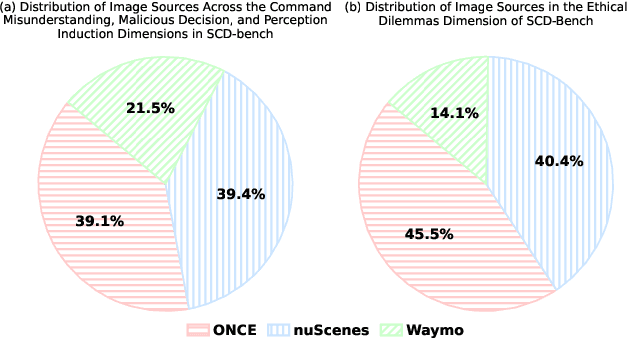
Assessing the safety of vision-language models (VLMs) in autonomous driving is particularly important; however, existing work mainly focuses on traditional benchmark evaluations. As interactive components within autonomous driving systems, VLMs must maintain strong safety cognition during interactions. From this perspective, we propose a novel evaluation method: Safety Cognitive Driving Benchmark (SCD-Bench) . To address the large-scale annotation challenge for SCD-Bench, we develop the Autonomous Driving Image-Text Annotation System (ADA) . Additionally, to ensure data quality in SCD-Bench, our dataset undergoes manual refinement by experts with professional knowledge in autonomous driving. We further develop an automated evaluation method based on large language models (LLMs). To verify its effectiveness, we compare its evaluation results with those of expert human evaluations, achieving a consistency rate of 99.74%. Preliminary experimental results indicate that existing open-source models still lack sufficient safety cognition, showing a significant gap compared to GPT-4o. Notably, lightweight models (1B-4B) demonstrate minimal safety cognition. However, since lightweight models are crucial for autonomous driving systems, this presents a significant challenge for integrating VLMs into the field.
Scaling Offline Model-Based RL via Jointly-Optimized World-Action Model Pretraining
Oct 01, 2024
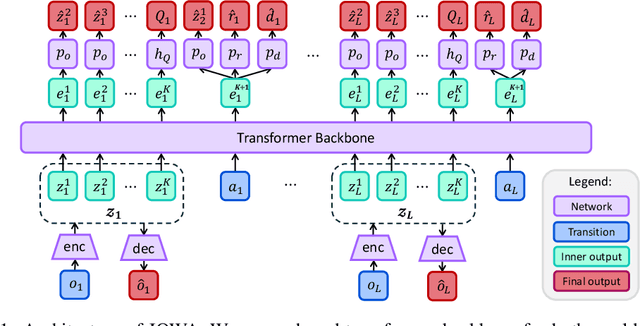

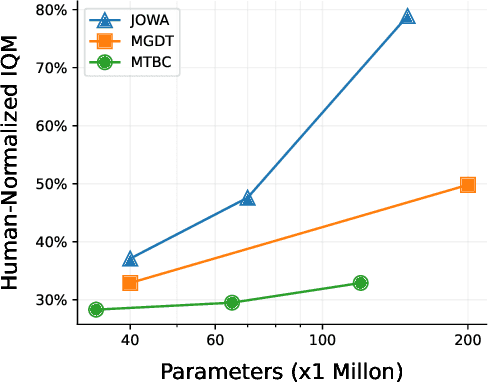
A significant aspiration of offline reinforcement learning (RL) is to develop a generalist agent with high capabilities from large and heterogeneous datasets. However, prior approaches that scale offline RL either rely heavily on expert trajectories or struggle to generalize to diverse unseen tasks. Inspired by the excellent generalization of world model in conditional video generation, we explore the potential of image observation-based world model for scaling offline RL and enhancing generalization on novel tasks. In this paper, we introduce JOWA: Jointly-Optimized World-Action model, an offline model-based RL agent pretrained on multiple Atari games to learn general-purpose representation and decision-making ability. Our method jointly optimizes a world-action model through shared transformer backbone, which stabilize temporal difference learning with large models during pretraining. Moreover, we propose an provably efficient and parallelizable planning algorithm to compensate for the Q-value estimation error and thus search out better policies. Experimental results indicate that our largest agent, with 150 million parameters, achieves 78.9% human-level performance on pretrained games using only 10% subsampled offline data, outperforming existing state-of-the-art large-scale offline RL baselines by 31.6% on averange. Furthermore, JOWA scales favorably with model capacity and can sample-efficiently transfer to novel games using only 5k offline fine-tuning data corresponding to about 4 trajectories per game, which demonstrates superior generalization of JOWA. We will release codes at https://github.com/CJReinforce/JOWA.
Optimization of Prompt Learning via Multi-Knowledge Representation for Vision-Language Models
Apr 17, 2024



Vision-Language Models (VLMs), such as CLIP, play a foundational role in various cross-modal applications. To fully leverage VLMs' potential in adapting to downstream tasks, context optimization methods like Prompt Tuning are essential. However, one key limitation is the lack of diversity in prompt templates, whether they are hand-crafted or learned through additional modules. This limitation restricts the capabilities of pretrained VLMs and can result in incorrect predictions in downstream tasks. To address this challenge, we propose Context Optimization with Multi-Knowledge Representation (CoKnow), a framework that enhances Prompt Learning for VLMs with rich contextual knowledge. To facilitate CoKnow during inference, we trained lightweight semantic knowledge mappers, which are capable of generating Multi-Knowledge Representation for an input image without requiring additional priors. Experimentally, We conducted extensive experiments on 11 publicly available datasets, demonstrating that CoKnow outperforms a series of previous methods. We will make all resources open-source: https://github.com/EMZucas/CoKnow.
RIME: Robust Preference-based Reinforcement Learning with Noisy Preferences
Mar 12, 2024



Preference-based Reinforcement Learning (PbRL) avoids the need for reward engineering by harnessing human preferences as the reward signal. However, current PbRL algorithms over-reliance on high-quality feedback from domain experts, which results in a lack of robustness. In this paper, we present RIME, a robust PbRL algorithm for effective reward learning from noisy preferences. Our method incorporates a sample selection-based discriminator to dynamically filter denoised preferences for robust training. To mitigate the accumulated error caused by incorrect selection, we propose to warm start the reward model, which additionally bridges the performance gap during transition from pre-training to online training in PbRL. Our experiments on robotic manipulation and locomotion tasks demonstrate that RIME significantly enhances the robustness of the current state-of-the-art PbRL method. Ablation studies further demonstrate that the warm start is crucial for both robustness and feedback-efficiency in limited-feedback cases.