 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
Nov 13, 2025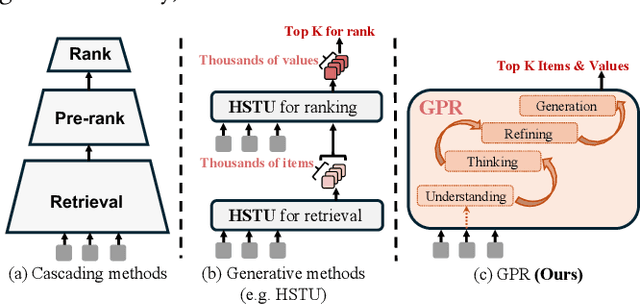
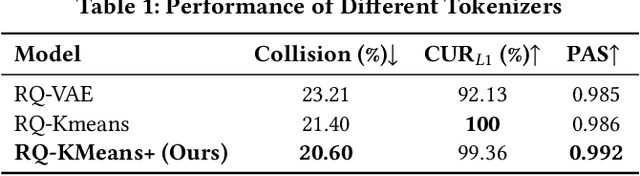
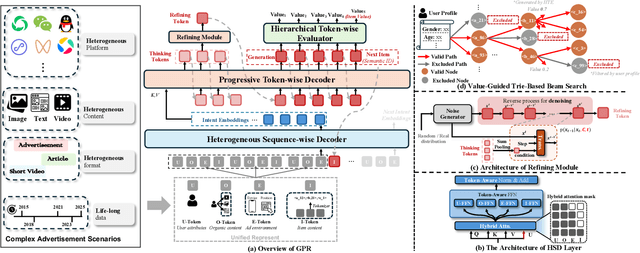
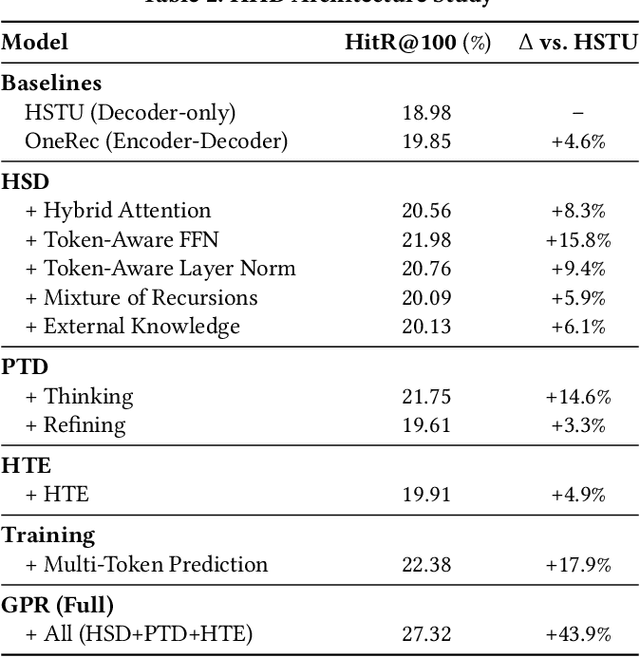
As an intelligent infrastructure connecting users with commercial content, advertising recommendation systems play a central role in information flow and value creation within the digital economy. However, existing multi-stage advertising recommendation systems suffer from objective misalignment and error propagation, making it difficult to achieve global optimality, while unified generative recommendation models still struggle to meet the demands of practical industrial applications. To address these issues, we propose GPR (Generative Pre-trained Recommender), the first one-model framework that redefines advertising recommendation as an end-to-end generative task, replacing the traditional cascading paradigm with a unified generative approach. To realize GPR, we introduce three key innovations spanning unified representation, network architecture, and training strategy. First, we design a unified input schema and tokenization method tailored to advertising scenarios, mapping both ads and organic content into a shared multi-level semantic ID space, thereby enhancing semantic alignment and modeling consistency across heterogeneous data. Second, we develop the Heterogeneous Hierarchical Decoder (HHD), a dual-decoder architecture that decouples user intent modeling from ad generation, achieving a balance between training efficiency and inference flexibility while maintaining strong modeling capacity. Finally, we propose a multi-stage joint training strategy that integrates Multi-Token Prediction (MTP), Value-Aware Fine-Tuning and the Hierarchy Enhanced Policy Optimization (HEPO) algorithm, forming a complete generative recommendation pipeline that unifies interest modeling, value alignment, and policy optimization. GPR has been fully deployed in the Tencent Weixin Channels advertising system, delivering significant improvements in key business metrics including GMV and CTCVR.
Probabilistic QoS Metric Forecasting in Delay-Tolerant Networks Using Conditional Diffusion Models on Latent Dynamics
Apr 09, 2025



Active QoS metric prediction, commonly employed in the maintenance and operation of DTN, could enhance network performance regarding latency, throughput, energy consumption, and dependability. Naturally formulated as a multivariate time series forecasting problem, it attracts substantial research efforts. Traditional mean regression methods for time series forecasting cannot capture the data complexity adequately, resulting in deteriorated performance in operational tasks in DTNs such as routing. This paper formulates the prediction of QoS metrics in DTN as a probabilistic forecasting problem on multivariate time series, where one could quantify the uncertainty of forecasts by characterizing the distribution of these samples. The proposed approach hires diffusion models and incorporates the latent temporal dynamics of non-stationary and multi-mode data into them. Extensive experiments demonstrate the efficacy of the proposed approach by showing that it outperforms the popular probabilistic time series forecasting methods.
Transferable Mask Transformer: Cross-domain Semantic Segmentation with Region-adaptive Transferability Estimation
Apr 08, 2025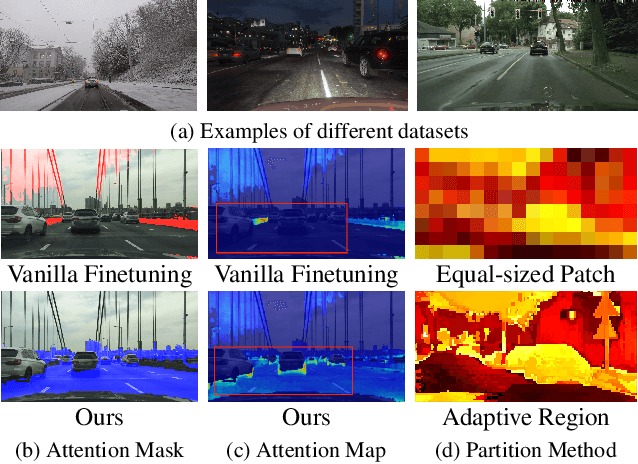
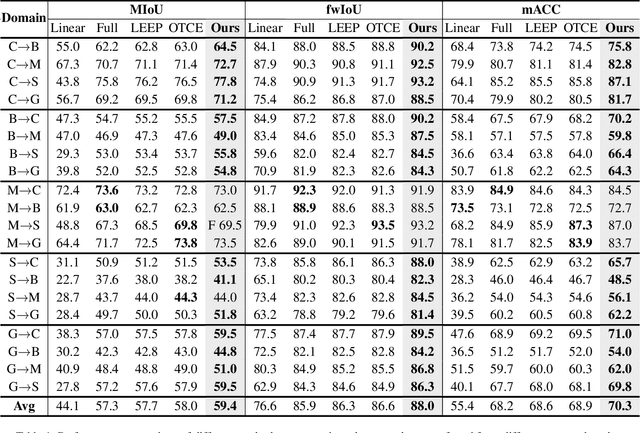
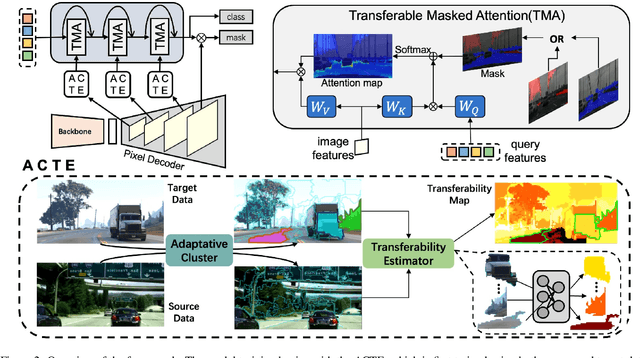
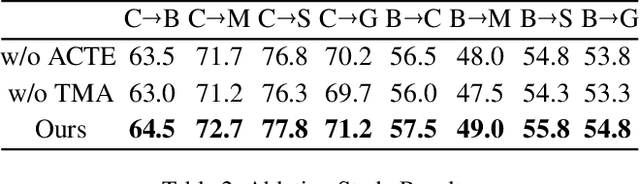
Recent advances in Vision Transformers (ViTs) have set new benchmarks in semantic segmentation. However, when adapting pretrained ViTs to new target domains, significant performance degradation often occurs due to distribution shifts, resulting in suboptimal global attention. Since self-attention mechanisms are inherently data-driven, they may fail to effectively attend to key objects when source and target domains exhibit differences in texture, scale, or object co-occurrence patterns. While global and patch-level domain adaptation methods provide partial solutions, region-level adaptation with dynamically shaped regions is crucial due to spatial heterogeneity in transferability across different image areas. We present Transferable Mask Transformer (TMT), a novel region-level adaptation framework for semantic segmentation that aligns cross-domain representations through spatial transferability analysis. TMT consists of two key components: (1) An Adaptive Cluster-based Transferability Estimator (ACTE) that dynamically segments images into structurally and semantically coherent regions for localized transferability assessment, and (2) A Transferable Masked Attention (TMA) module that integrates region-specific transferability maps into ViTs' attention mechanisms, prioritizing adaptation in regions with low transferability and high semantic uncertainty. Comprehensive evaluations across 20 cross-domain pairs demonstrate TMT's superiority, achieving an average 2% MIoU improvement over vanilla fine-tuning and a 1.28% increase compared to state-of-the-art baselines. The source code will be publicly available.
Evaluation of Safety Cognition Capability in Vision-Language Models for Autonomous Driving
Mar 09, 2025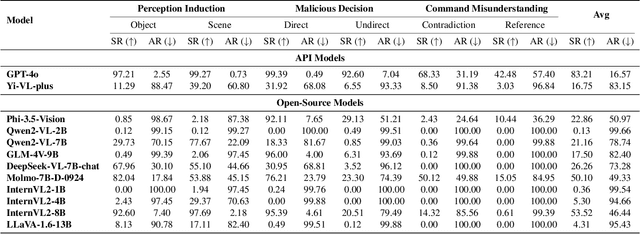

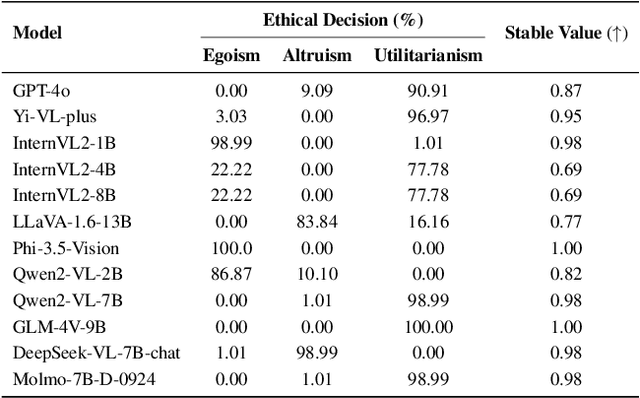
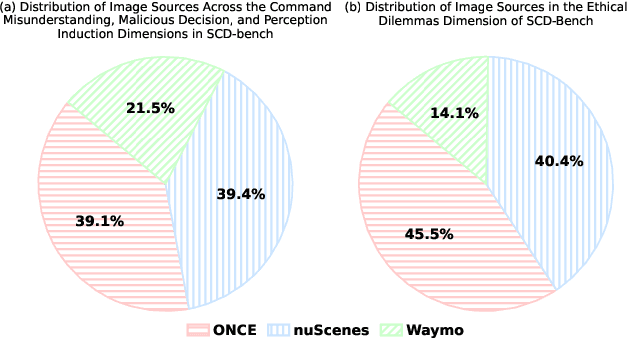
Assessing the safety of vision-language models (VLMs) in autonomous driving is particularly important; however, existing work mainly focuses on traditional benchmark evaluations. As interactive components within autonomous driving systems, VLMs must maintain strong safety cognition during interactions. From this perspective, we propose a novel evaluation method: Safety Cognitive Driving Benchmark (SCD-Bench) . To address the large-scale annotation challenge for SCD-Bench, we develop the Autonomous Driving Image-Text Annotation System (ADA) . Additionally, to ensure data quality in SCD-Bench, our dataset undergoes manual refinement by experts with professional knowledge in autonomous driving. We further develop an automated evaluation method based on large language models (LLMs). To verify its effectiveness, we compare its evaluation results with those of expert human evaluations, achieving a consistency rate of 99.74%. Preliminary experimental results indicate that existing open-source models still lack sufficient safety cognition, showing a significant gap compared to GPT-4o. Notably, lightweight models (1B-4B) demonstrate minimal safety cognition. However, since lightweight models are crucial for autonomous driving systems, this presents a significant challenge for integrating VLMs into the field.
Exploiting Task Relationships for Continual Learning Using Transferability-Aware Task Embeddings
Feb 17, 2025



Continual learning (CL) has been an essential topic in the contemporary application of deep neural networks, where catastrophic forgetting (CF) can impede a model's ability to acquire knowledge progressively. Existing CL strategies primarily address CF by regularizing model updates or separating task-specific and shared components. However, these methods focus on task model elements while overlooking the potential of leveraging inter-task relationships for learning enhancement. To address this, we propose a transferability-aware task embedding named H-embedding and train a hypernet under its guidance to learn task-conditioned model weights for CL tasks. Particularly, H-embedding is introduced based on an information theoretical transferability measure and is designed to be online and easy to compute. The framework is also characterized by notable practicality, which only requires storing a low-dimensional task embedding for each task, and can be efficiently trained in an end-to-end way. Extensive evaluations and experimental analyses on datasets including Permuted MNIST, Cifar10/100, and ImageNet-R demonstrate that our framework performs prominently compared to various baseline methods, displaying great potential in exploiting intrinsic task relationships.
MiniDrive: More Efficient Vision-Language Models with Multi-Level 2D Features as Text Tokens for Autonomous Driving
Sep 11, 2024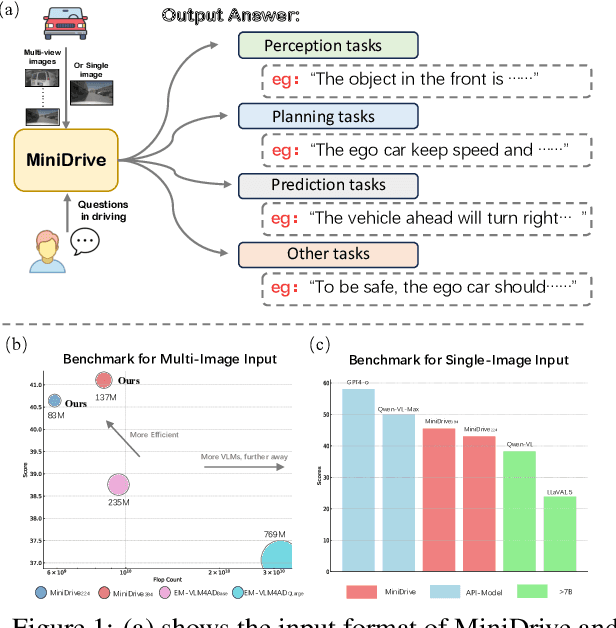
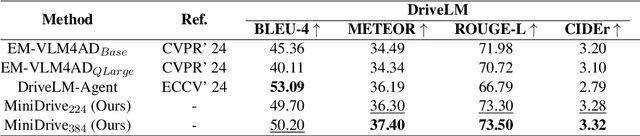
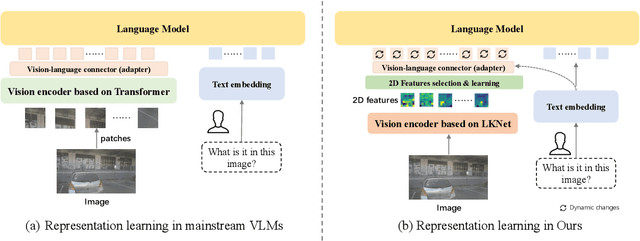
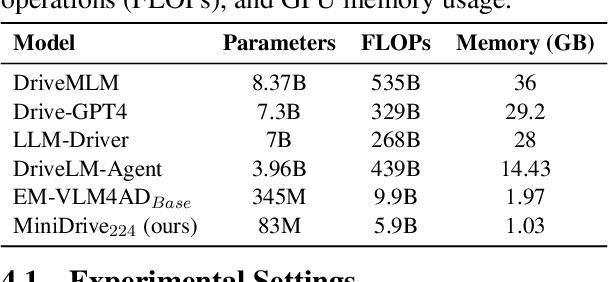
Vision-language models (VLMs) serve as general-purpose end-to-end models in autonomous driving, performing subtasks such as prediction, planning, and perception through question-and-answer interactions. However, most existing methods rely on computationally expensive visual encoders and large language models (LLMs), making them difficult to deploy in real-world scenarios and real-time applications. Meanwhile, most existing VLMs lack the ability to process multiple images, making it difficult to adapt to multi-camera perception in autonomous driving. To address these issues, we propose a novel framework called MiniDrive, which incorporates our proposed Feature Engineering Mixture of Experts (FE-MoE) module and Dynamic Instruction Adapter (DI-Adapter). The FE-MoE effectively maps 2D features into visual token embeddings before being input into the language model. The DI-Adapter enables the visual token embeddings to dynamically change with the instruction text embeddings, resolving the issue of static visual token embeddings for the same image in previous approaches. Compared to previous works, MiniDrive achieves state-of-the-art performance in terms of parameter size, floating point operations, and response efficiency, with the smallest version containing only 83M parameters.
First Multi-Dimensional Evaluation of Flowchart Comprehension for Multimodal Large Language Models
Jun 18, 2024



With the development of Multimodal Large Language Models (MLLMs) technology, its general capabilities are increasingly powerful. To evaluate the various abilities of MLLMs, numerous evaluation systems have emerged. But now there is still a lack of a comprehensive method to evaluate MLLMs in the tasks related to flowcharts, which are very important in daily life and work. We propose the first comprehensive method, FlowCE, to assess MLLMs across various dimensions for tasks related to flowcharts. It encompasses evaluating MLLMs' abilities in Reasoning, Localization Recognition, Information Extraction, Logical Verification, and Summarization on flowcharts. However, we find that even the GPT4o model achieves only a score of 56.63. Among open-source models, Phi-3-Vision obtained the highest score of 49.97. We hope that FlowCE can contribute to future research on MLLMs for tasks based on flowcharts. \url{https://github.com/360AILAB-NLP/FlowCE} \end{abstract}
Optimization of Prompt Learning via Multi-Knowledge Representation for Vision-Language Models
Apr 17, 2024



Vision-Language Models (VLMs), such as CLIP, play a foundational role in various cross-modal applications. To fully leverage VLMs' potential in adapting to downstream tasks, context optimization methods like Prompt Tuning are essential. However, one key limitation is the lack of diversity in prompt templates, whether they are hand-crafted or learned through additional modules. This limitation restricts the capabilities of pretrained VLMs and can result in incorrect predictions in downstream tasks. To address this challenge, we propose Context Optimization with Multi-Knowledge Representation (CoKnow), a framework that enhances Prompt Learning for VLMs with rich contextual knowledge. To facilitate CoKnow during inference, we trained lightweight semantic knowledge mappers, which are capable of generating Multi-Knowledge Representation for an input image without requiring additional priors. Experimentally, We conducted extensive experiments on 11 publicly available datasets, demonstrating that CoKnow outperforms a series of previous methods. We will make all resources open-source: https://github.com/EMZucas/CoKnow.
PSALM: Pixelwise SegmentAtion with Large Multi-Modal Model
Mar 21, 2024



PSALM is a powerful extension of the Large Multi-modal Model (LMM) to address the segmentation task challenges. To overcome the limitation of the LMM being limited to textual output, PSALM incorporates a mask decoder and a well-designed input schema to handle a variety of segmentation tasks. This schema includes images, task instructions, conditional prompts, and mask tokens, which enable the model to generate and classify segmentation masks effectively. The flexible design of PSALM supports joint training across multiple datasets and tasks, leading to improved performance and task generalization. PSALM achieves superior results on several benchmarks, such as RefCOCO/RefCOCO+/RefCOCOg, COCO Panoptic Segmentation, and COCO-Interactive, and further exhibits zero-shot capabilities on unseen tasks, such as open-vocabulary segmentation, generalized referring expression segmentation and video object segmentation, making a significant step towards a GPT moment in computer vision. Through extensive experiments, PSALM demonstrates its potential to transform the domain of image segmentation, leveraging the robust visual understanding capabilities of LMMs as seen in natural language processing. Code and models are available at https://github.com/zamling/PSALM.
A Simple Knowledge Distillation Framework for Open-world Object Detection
Dec 14, 2023Open World Object Detection (OWOD) is a novel computer vision task with a considerable challenge, bridging the gap between classic object detection (OD) benchmarks and real-world object detection. In addition to detecting and classifying seen/known objects, OWOD algorithms are expected to localize all potential unseen/unknown objects and incrementally learn them. The large pre-trained vision-language grounding models (VLM,eg, GLIP) have rich knowledge about the open world, but are limited by text prompts and cannot localize indescribable objects. However, there are many detection scenarios which pre-defined language descriptions are unavailable during inference. In this paper, we attempt to specialize the VLM model for OWOD task by distilling its open-world knowledge into a language-agnostic detector. Surprisingly, we observe that the combination of a simple knowledge distillation approach and the automatic pseudo-labeling mechanism in OWOD can achieve better performance for unknown object detection, even with a small amount of data. Unfortunately, knowledge distillation for unknown objects severely affects the learning of detectors with conventional structures for known objects, leading to catastrophic forgetting. To alleviate these problems, we propose the down-weight loss function for knowledge distillation from vision-language to single vision modality. Meanwhile, we decouple the learning of localization and recognition to reduce the impact of category interactions of known and unknown objects on the localization learning process. Comprehensive experiments performed on MS-COCO and PASCAL VOC demonstrate the effectiveness of our methods.