 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Mask Transformer: Cross-domain Semantic Segmentation with Region-adaptive Transferability Estimation
Paper and Code
Apr 08, 2025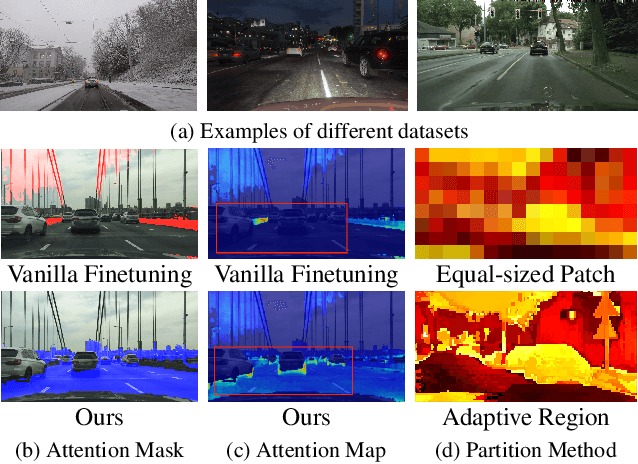
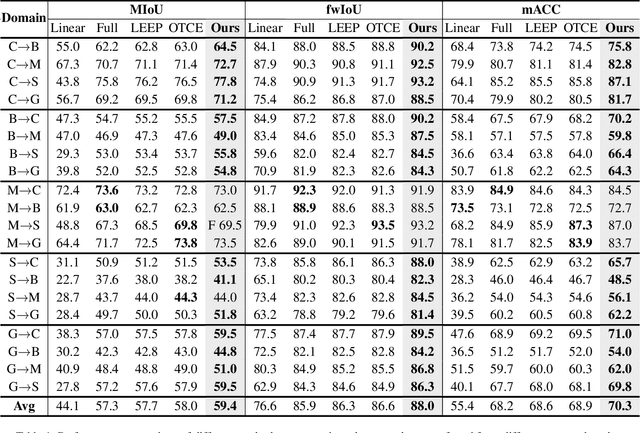
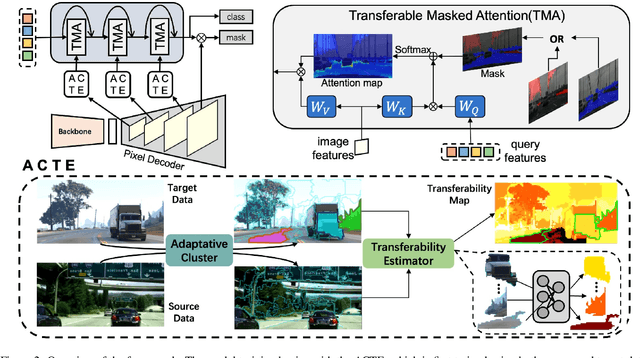
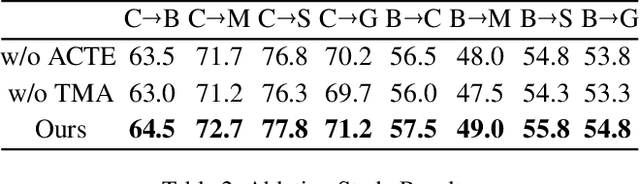
Recent advances in Vision Transformers (ViTs) have set new benchmarks in semantic segmentation. However, when adapting pretrained ViTs to new target domains, significant performance degradation often occurs due to distribution shifts, resulting in suboptimal global attention. Since self-attention mechanisms are inherently data-driven, they may fail to effectively attend to key objects when source and target domains exhibit differences in texture, scale, or object co-occurrence patterns. While global and patch-level domain adaptation methods provide partial solutions, region-level adaptation with dynamically shaped regions is crucial due to spatial heterogeneity in transferability across different image areas. We present Transferable Mask Transformer (TMT), a novel region-level adaptation framework for semantic segmentation that aligns cross-domain representations through spatial transferability analysis. TMT consists of two key components: (1) An Adaptive Cluster-based Transferability Estimator (ACTE) that dynamically segments images into structurally and semantically coherent regions for localized transferability assessment, and (2) A Transferable Masked Attention (TMA) module that integrates region-specific transferability maps into ViTs' attention mechanisms, prioritizing adaptation in regions with low transferability and high semantic uncertainty. Comprehensive evaluations across 20 cross-domain pairs demonstrate TMT's superiority, achieving an average 2% MIoU improvement over vanilla fine-tuning and a 1.28% increase compared to state-of-the-art baselines. The source code will be publicly available.