 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Mask Transformer: Cross-domain Semantic Segmentation with Region-adaptive Transferability Estimation
Apr 08, 2025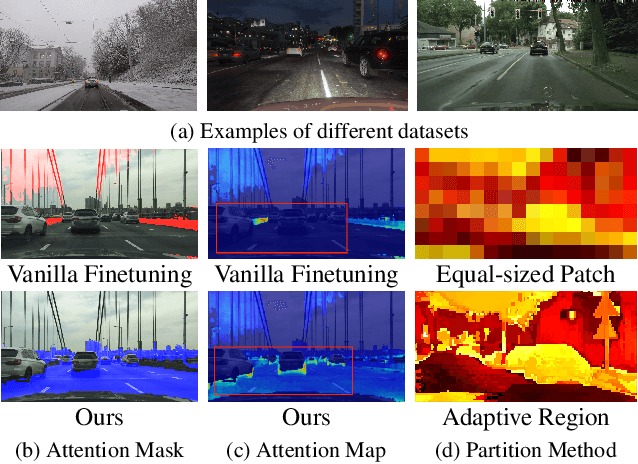
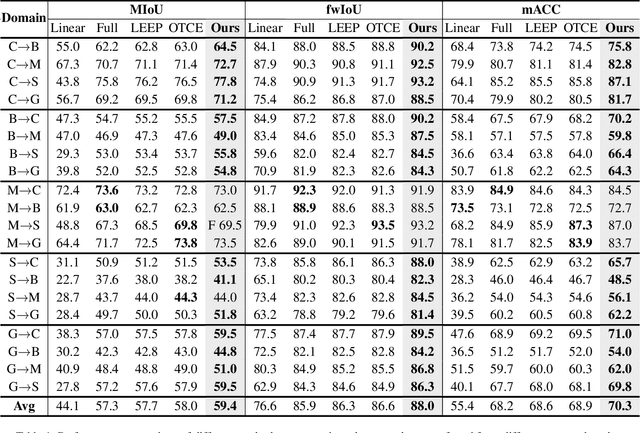
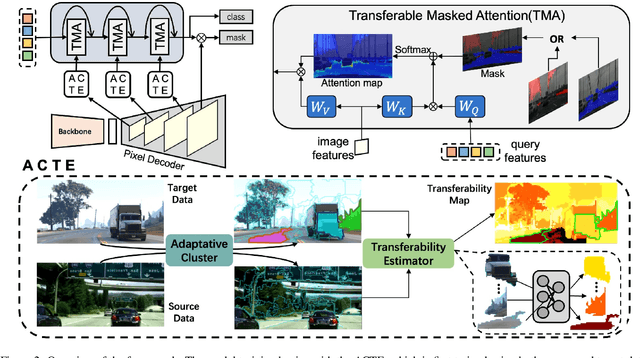
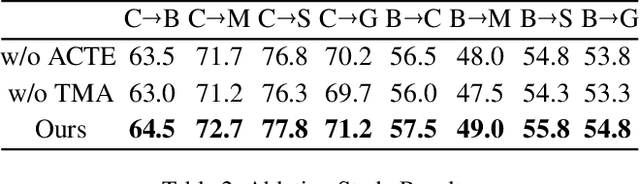
Recent advances in Vision Transformers (ViTs) have set new benchmarks in semantic segmentation. However, when adapting pretrained ViTs to new target domains, significant performance degradation often occurs due to distribution shifts, resulting in suboptimal global attention. Since self-attention mechanisms are inherently data-driven, they may fail to effectively attend to key objects when source and target domains exhibit differences in texture, scale, or object co-occurrence patterns. While global and patch-level domain adaptation methods provide partial solutions, region-level adaptation with dynamically shaped regions is crucial due to spatial heterogeneity in transferability across different image areas. We present Transferable Mask Transformer (TMT), a novel region-level adaptation framework for semantic segmentation that aligns cross-domain representations through spatial transferability analysis. TMT consists of two key components: (1) An Adaptive Cluster-based Transferability Estimator (ACTE) that dynamically segments images into structurally and semantically coherent regions for localized transferability assessment, and (2) A Transferable Masked Attention (TMA) module that integrates region-specific transferability maps into ViTs' attention mechanisms, prioritizing adaptation in regions with low transferability and high semantic uncertainty. Comprehensive evaluations across 20 cross-domain pairs demonstrate TMT's superiority, achieving an average 2% MIoU improvement over vanilla fine-tuning and a 1.28% increase compared to state-of-the-art baselines. The source code will be publicly available.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Adaptive Loss Scaling for Mixed Precision Training
Oct 28, 2019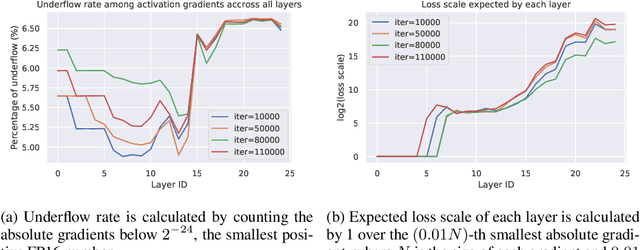



Mixed precision training (MPT) is becoming a practical technique to improve the speed and energy efficiency of training deep neural networks by leveraging the fast hardware support for IEEE half-precision floating point that is available in existing GPUs. MPT is typically used in combination with a technique called loss scaling, that works by scaling up the loss value up before the start of backpropagation in order to minimize the impact of numerical underflow on training. Unfortunately, existing methods make this loss scale value a hyperparameter that needs to be tuned per-model, and a single scale cannot be adapted to different layers at different training stages. We introduce a loss scaling-based training method called adaptive loss scaling that makes MPT easier and more practical to use, by removing the need to tune a model-specific loss scale hyperparameter. We achieve this by introducing layer-wise loss scale values which are automatically computed during training to deal with underflow more effectively than existing methods. We present experimental results on a variety of networks and tasks that show our approach can shorten the time to convergence and improve accuracy compared to the existing state-of-the-art MPT and single-precision floating point
Deep Neural Network Approximation for Custom Hardware: Where We've Been, Where We're Going
Jan 21, 2019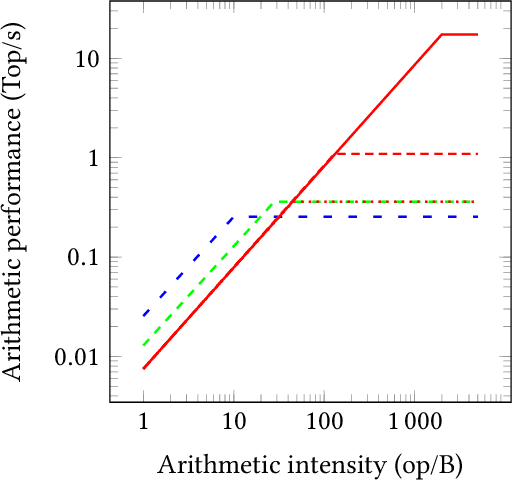
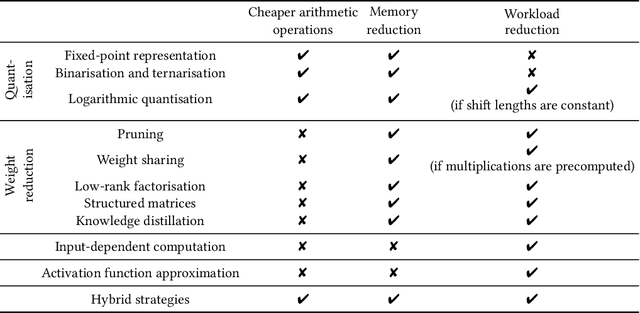
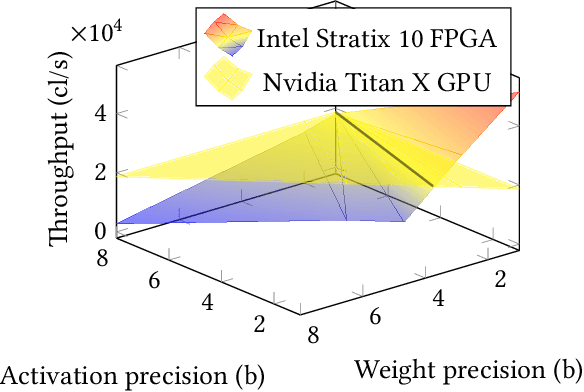
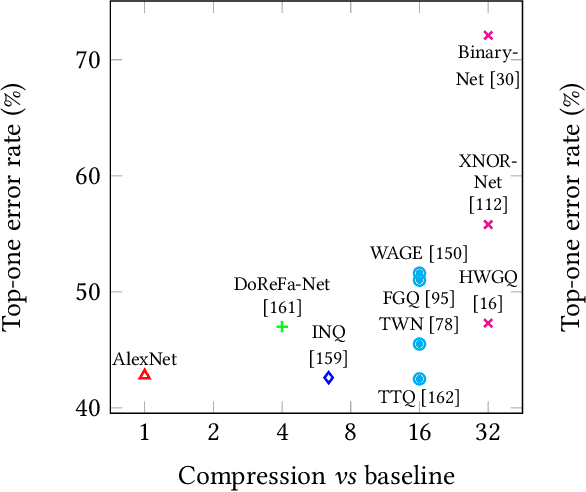
Deep neural networks have proven to be particularly effective in visual and audio recognition tasks. Existing models tend to be computationally expensive and memory intensive, however, and so methods for hardware-oriented approximation have become a hot topic. Research has shown that custom hardware-based neural network accelerators can surpass their general-purpose processor equivalents in terms of both throughput and energy efficiency. Application-tailored accelerators, when co-designed with approximation-based network training methods, transform large, dense and computationally expensive networks into small, sparse and hardware-efficient alternatives, increasing the feasibility of network deployment. In this article, we provide a comprehensive evaluation of approximation methods for high-performance network inference along with in-depth discussion of their effectiveness for custom hardware implementation. We also include proposals for future research based on a thorough analysis of current trends. This article represents the first survey providing detailed comparisons of custom hardware accelerators featuring approximation for both convolutional and recurrent neural networks, through which we hope to inspire exciting new developments in the field.
Learning Grouped Convolution for Efficient Domain Adaptation
Nov 23, 2018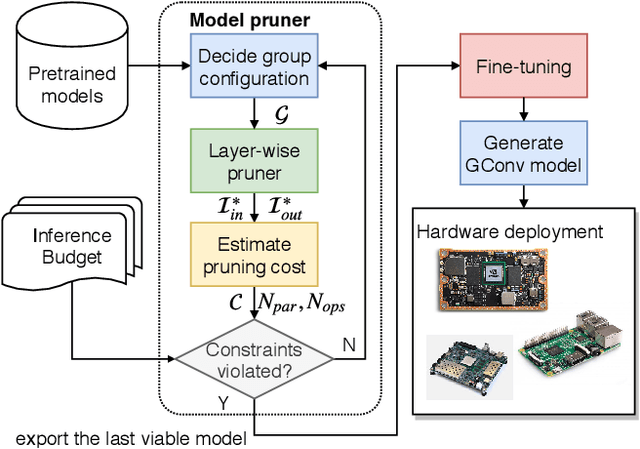

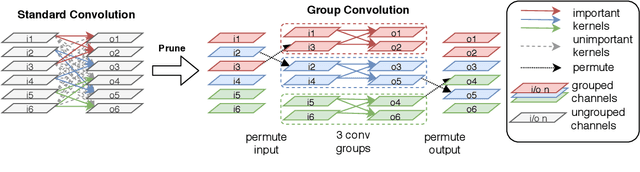
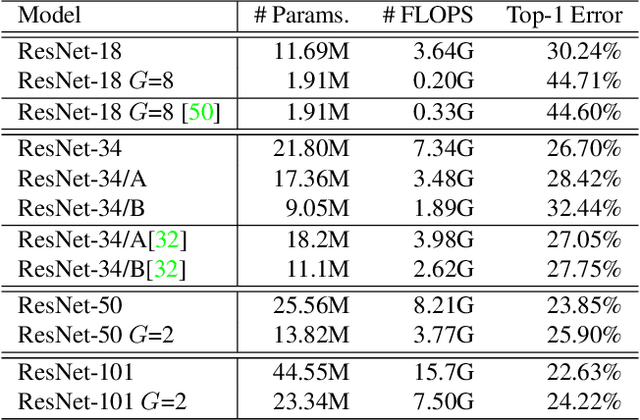
This paper presents Dokei, an effective supervised domain adaptation method to transform a pre-trained CNN model to one involving efficient grouped convolution. The basis of this approach is formalised as a novel optimisation problem constrained by group sparsity pattern (GSP), and a practical solution based on structured regularisation and maximal bipartite matching is provided. We show that it is vital to keep the connections specified by GSP when mapping pre-trained weights to grouped convolution. We evaluate Dokei on various domains and hardware platforms to demonstrate its effectiveness. The models resulting from Dokei are shown to be more accurate and slimmer than prior work targeting grouped convolution, and more regular and easier to deploy than other pruning techniques.
Towards Efficient Convolutional Neural Network for Domain-Specific Applications on FPGA
Sep 04, 2018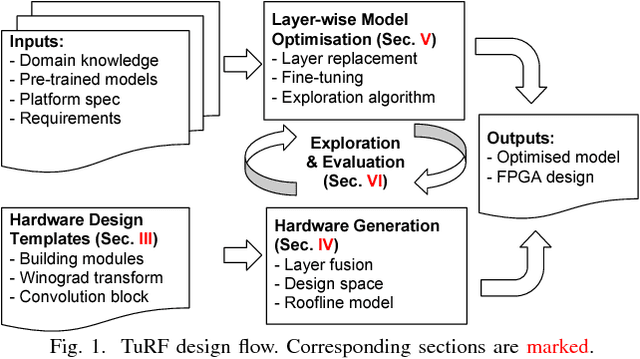
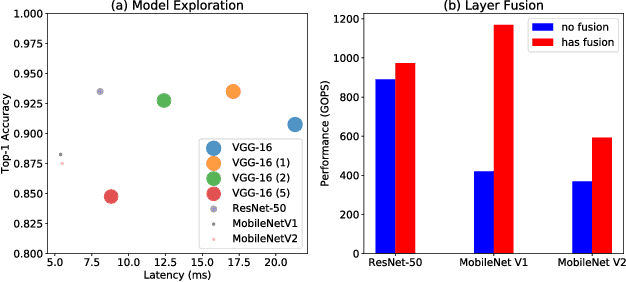
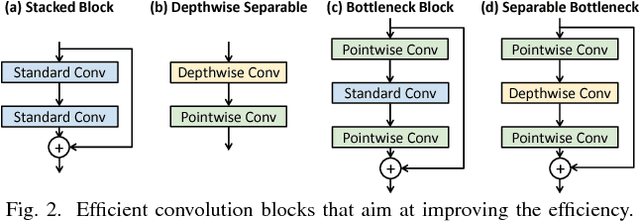
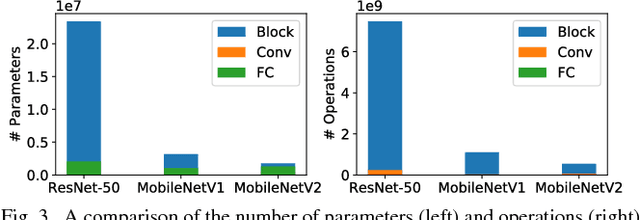
FPGA becomes a popular technology for implementing Convolutional Neural Network (CNN) in recent years. Most CNN applications on FPGA are domain-specific, e.g., detecting objects from specific categories, in which commonly-used CNN models pre-trained on general datasets may not be efficient enough. This paper presents TuRF, an end-to-end CNN acceleration framework to efficiently deploy domain-specific applications on FPGA by transfer learning that adapts pre-trained models to specific domains, replacing standard convolution layers with efficient convolution blocks, and applying layer fusion to enhance hardware design performance. We evaluate TuRF by deploying a pre-trained VGG-16 model for a domain-specific image recognition task onto a Stratix V FPGA. Results show that designs generated by TuRF achieve better performance than prior methods for the original VGG-16 and ResNet-50 models, while for the optimised VGG-16 model TuRF designs are more accurate and easier to process.