 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemmFHE: mmWave Sensing with End-to-End Fully Homomorphic Encryption
Mar 23, 2026We present mmFHE, the first system that enables fully homomorphic encryption (FHE) for end-to-end mmWave radar sensing. mmFHE encrypts raw range profiles on a lightweight edge device and executes the entire mmWave signal-processing and ML inference pipeline homomorphically on an untrusted cloud that operates exclusively on ciphertexts. At the core of mmFHE is a library of seven composable, data-oblivious FHE kernels that replace standard DSP routines with fixed arithmetic circuits. These kernels can be flexibly composed into different application-specific pipelines. We demonstrate this approach on two representative tasks: vital-sign monitoring and gesture recognition. We formally prove two cryptographic guarantees for any pipeline assembled from this library: input privacy, the cloud learns nothing about the sensor data; and data obliviousness, the execution trace is identical on the cloud regardless of the data being processed. These guarantees effectively neutralize various supervised and unsupervised privacy attacks on raw data, including re-identification and data-dependent privacy leakage. Evaluation on three public radar datasets (270 vital-sign recordings, 600 gesture trials) shows that encryption introduces negligible error: HR/RR MAE <10^-3 bpm versus plaintext, and 84.5% gesture accuracy (vs. 84.7% plaintext) with end-to-end cloud GPU latency of 103s for a 10s vital-sign window and 37s for a 3s gesture window. These results show that privacy-preserving end-to-end mmWave sensing is feasible on commodity hardware today.
Multilingual Financial Fraud Detection Using Machine Learning and Transformer Models: A Bangla-English Study
Mar 11, 2026Financial fraud detection has emerged as a critical research challenge amid the rapid expansion of digital financial platforms. Although machine learning approaches have demonstrated strong performance in identifying fraudulent activities, most existing research focuses exclusively on English-language data, limiting applicability to multilingual contexts. Bangla (Bengali), despite being spoken by over 250 million people, remains largely unexplored in this domain. In this work, we investigate financial fraud detection in a multilingual Bangla-English setting using a dataset comprising legitimate and fraudulent financial messages. We evaluate classical machine learning models (Logistic Regression, Linear SVM, and Ensemble classifiers) using TF-IDF features alongside transformer-based architectures. Experimental results using 5-fold stratified cross-validation demonstrate that Linear SVM achieves the best performance with 91.59 percent accuracy and 91.30 percent F1 score, outperforming the transformer model (89.49 percent accuracy, 88.88 percent F1) by approximately 2 percentage points. The transformer exhibits higher fraud recall (94.19 percent) but suffers from elevated false positive rates. Exploratory analysis reveals distinctive patterns: scam messages are longer, contain urgency-inducing terms, and frequently include URLs (32 percent) and phone numbers (97 percent), while legitimate messages feature transactional confirmations and specific currency references. Our findings highlight that classical machine learning with well-crafted features remains competitive for multilingual fraud detection, while also underscoring the challenges posed by linguistic diversity, code-mixing, and low-resource language constraints.
Feasibility of Radio Frequency Based Wireless Sensing of Lead Contamination in Soil
Dec 18, 2025



Widespread Pb (lead) contamination of urban soil significantly impacts food safety and public health and hinders city greening efforts. However, most existing technologies for measuring Pb are labor-intensive and costly. In this study, we propose SoilScanner, a radio frequency-based wireless system that can detect Pb in soils. This is based on our discovery that the propagation of different frequency band radio signals is affected differently by different salts such as NaCl and Pb(NO3)2 in the soil. In a controlled experiment, manually adding NaCl and Pb(NO3)2 in clean soil, we demonstrated that different salts reflected signals at different frequencies in distinct patterns. In addition, we confirmed the finding using uncontrolled field samples with a machine learning model. Our experiment results show that SoilScanner can classify soil samples into low-Pb and high-Pb categories (threshold at 200 ppm) with an accuracy of 72%, with no sample with > 500 ppm of Pb being misclassified. The results of this study show that it is feasible to build portable and affordable Pb detection and screening devices based on wireless technology.
Short-Term Electricity Demand Forecasting of Dhaka City Using CNN with Stacked BiLSTM
Jun 10, 2024The precise forecasting of electricity demand also referred to as load forecasting, is essential for both planning and managing a power system. It is crucial for many tasks, including choosing which power units to commit to, making plans for future power generation capacity, enhancing the power network, and controlling electricity consumption. As Bangladesh is a developing country, the electricity infrastructure is critical for economic growth and employment in this country. Accurate forecasting of electricity demand is crucial for ensuring that this country has a reliable and sustainable electricity supply to meet the needs of its growing population and economy. The complex and nonlinear behavior of such energy systems inhibits the creation of precise algorithms. Within this context, this paper aims to propose a hybrid model of Convolutional Neural Network (CNN) and stacked Bidirectional Long-short Term Memory (BiLSTM) architecture to perform an accurate short-term forecast of the electricity demand of Dhaka city. Short-term forecasting is ordinarily done to anticipate load for the following few hours to a few weeks. Normalization techniques have been also investigated because of the sensitivity of these models towards the input range. The proposed approach produced the best prediction results in comparison to the other benchmark models (LSTM, CNN- BiLSTM and CNN-LSTM) used in the study, with MAPE 1.64%, MSE 0.015, RMSE 0.122 and MAE 0.092. The result of the proposed model also outperformed some of the existing works on load-forecasting.
Patients' Severity States Classification based on Electronic Health Record (EHR) Data using Multiple Machine Learning and Deep Learning Approaches
Sep 29, 2022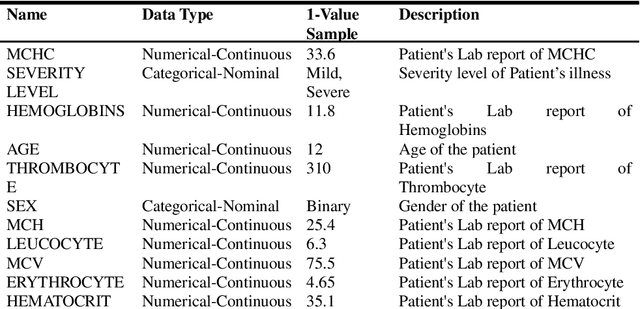
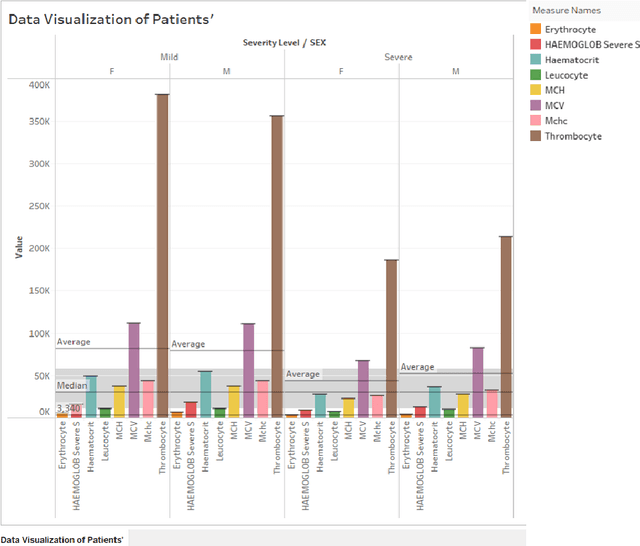
This research presents an examination of categorizing the severity states of patients based on their electronic health records during a certain time range using multiple machine learning and deep learning approaches. The suggested method uses an EHR dataset collected from an open-source platform to categorize severity. Some tools were used in this research, such as openRefine was used to pre-process, RapidMiner was used for implementing three algorithms (Fast Large Margin, Generalized Linear Model, Multi-layer Feed-forward Neural Network) and Tableau was used to visualize the data, for implementation of algorithms we used Google Colab. Here we implemented several supervised and unsupervised algorithms along with semi-supervised and deep learning algorithms. The experimental results reveal that hyperparameter-tuned Random Forest outperformed all the other supervised machine learning algorithms with 76% accuracy as well as Generalized Linear algorithm achieved the highest precision score 78%, whereas the hyperparameter-tuned Hierarchical Clustering with 86% precision score and Gaussian Mixture Model with 61% accuracy outperformed other unsupervised approaches. Dimensionality Reduction improved results a lot for most unsupervised techniques. For implementing Deep Learning we employed a feed-forward neural network (multi-layer) and the Fast Large Margin approach for semi-supervised learning. The Fast Large Margin performed really well with a recall score of 84% and an F1 score of 78%. Finally, the Multi-layer Feed-forward Neural Network performed admirably with 75% accuracy, 75% precision, 87% recall, 81% F1 score.
Adaptive Loss Scaling for Mixed Precision Training
Oct 28, 2019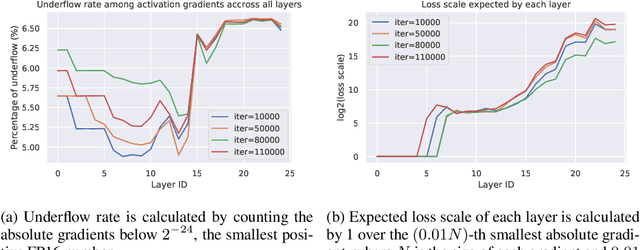



Mixed precision training (MPT) is becoming a practical technique to improve the speed and energy efficiency of training deep neural networks by leveraging the fast hardware support for IEEE half-precision floating point that is available in existing GPUs. MPT is typically used in combination with a technique called loss scaling, that works by scaling up the loss value up before the start of backpropagation in order to minimize the impact of numerical underflow on training. Unfortunately, existing methods make this loss scale value a hyperparameter that needs to be tuned per-model, and a single scale cannot be adapted to different layers at different training stages. We introduce a loss scaling-based training method called adaptive loss scaling that makes MPT easier and more practical to use, by removing the need to tune a model-specific loss scale hyperparameter. We achieve this by introducing layer-wise loss scale values which are automatically computed during training to deal with underflow more effectively than existing methods. We present experimental results on a variety of networks and tasks that show our approach can shorten the time to convergence and improve accuracy compared to the existing state-of-the-art MPT and single-precision floating point
Movie Popularity Classification based on Inherent Movie Attributes using C4.5,PART and Correlation Coefficient
Sep 26, 2012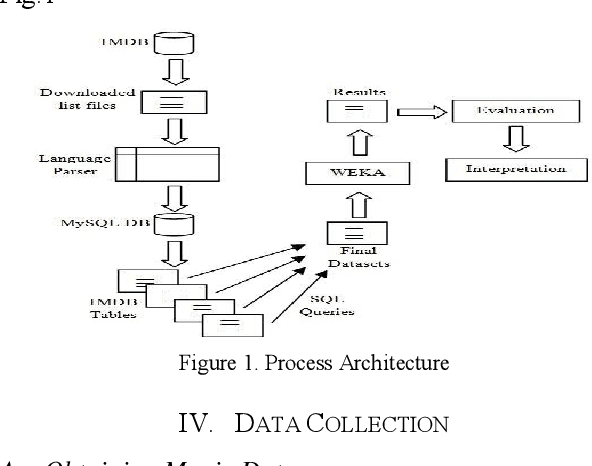
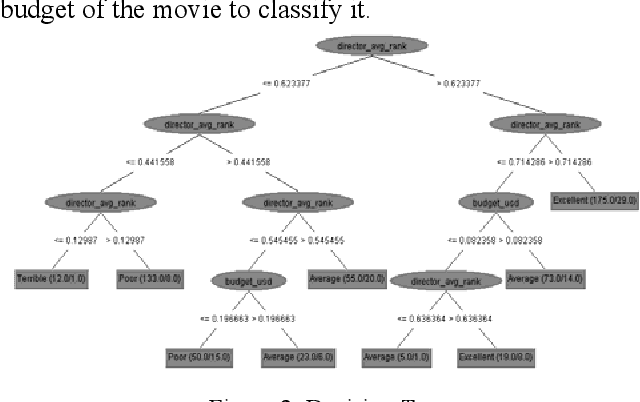
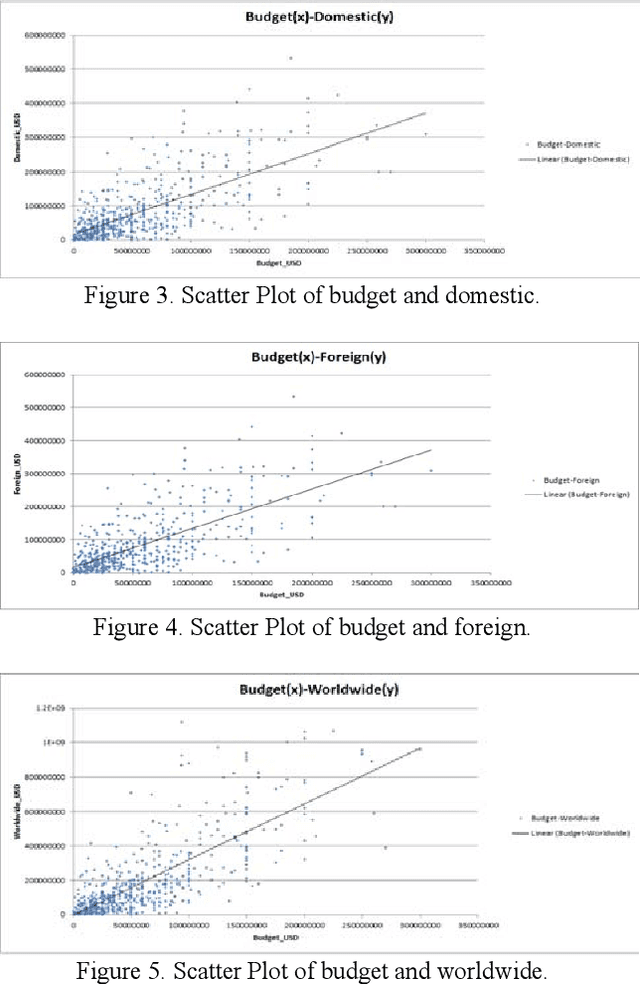
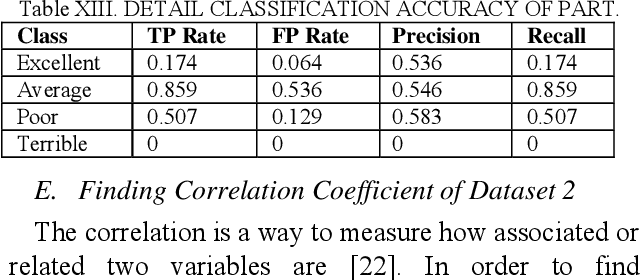
Abundance of movie data across the internet makes it an obvious candidate for machine learning and knowledge discovery. But most researches are directed towards bi-polar classification of movie or generation of a movie recommendation system based on reviews given by viewers on various internet sites. Classification of movie popularity based solely on attributes of a movie i.e. actor, actress, director rating, language, country and budget etc. has been less highlighted due to large number of attributes that are associated with each movie and their differences in dimensions. In this paper, we propose classification scheme of pre-release movie popularity based on inherent attributes using C4.5 and PART classifier algorithm and define the relation between attributes of post release movies using correlation coefficient.
* 6 pages