 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Optimization of Source Weights and Transfer Quantities in Multi-Source Transfer Learning: An Asymptotic Framework
Jan 15, 2026Transfer learning plays a vital role in improving model performance in data-scarce scenarios. However, naive uniform transfer from multiple source tasks may result in negative transfer, highlighting the need to properly balance the contributions of heterogeneous sources. Moreover, existing transfer learning methods typically focus on optimizing either the source weights or the amount of transferred samples, while largely neglecting the joint consideration of the other. In this work, we propose a theoretical framework, Unified Optimization of Weights and Quantities (UOWQ), which formulates multi-source transfer learning as a parameter estimation problem grounded in an asymptotic analysis of a Kullback-Leibler divergence-based generalization error measure. The proposed framework jointly determines the optimal source weights and optimal transfer quantities for each source task. Firstly, we prove that using all available source samples is always optimal once the weights are properly adjusted, and we provide a theoretical explanation for this phenomenon. Moreover, to determine the optimal transfer weights, our analysis yields closed-form solutions in the single-source setting and develops a convex optimization-based numerical procedure for the multi-source case. Building on the theoretical results, we further propose practical algorithms for both multi-source transfer learning and multi-task learning settings. Extensive experiments on real-world benchmarks, including DomainNet and Office-Home, demonstrate that UOWQ consistently outperforms strong baselines. The results validate both the theoretical predictions and the practical effectiveness of our framework.
TreeReview: A Dynamic Tree of Questions Framework for Deep and Efficient LLM-based Scientific Peer Review
Jun 09, 2025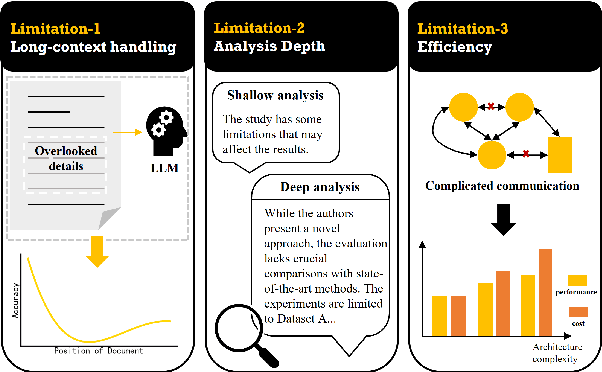
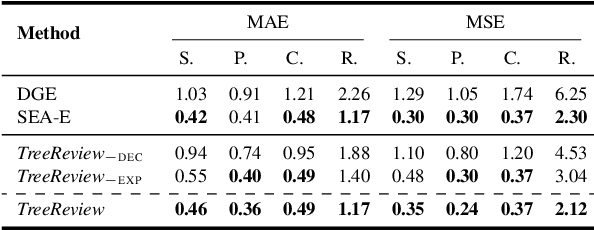
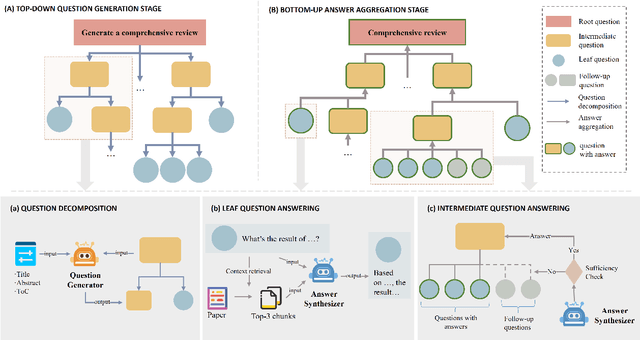
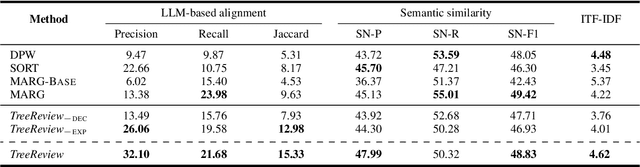
While Large Language Models (LLMs) have shown significant potential in assisting peer review, current methods often struggle to generate thorough and insightful reviews while maintaining efficiency. In this paper, we propose TreeReview, a novel framework that models paper review as a hierarchical and bidirectional question-answering process. TreeReview first constructs a tree of review questions by recursively decomposing high-level questions into fine-grained sub-questions and then resolves the question tree by iteratively aggregating answers from leaf to root to get the final review. Crucially, we incorporate a dynamic question expansion mechanism to enable deeper probing by generating follow-up questions when needed. We construct a benchmark derived from ICLR and NeurIPS venues to evaluate our method on full review generation and actionable feedback comments generation tasks. Experimental results of both LLM-based and human evaluation show that TreeReview outperforms strong baselines in providing comprehensive, in-depth, and expert-aligned review feedback, while reducing LLM token usage by up to 80% compared to computationally intensive approaches. Our code and benchmark dataset are available at https://github.com/YuanChang98/tree-review.
Transferable Mask Transformer: Cross-domain Semantic Segmentation with Region-adaptive Transferability Estimation
Apr 08, 2025
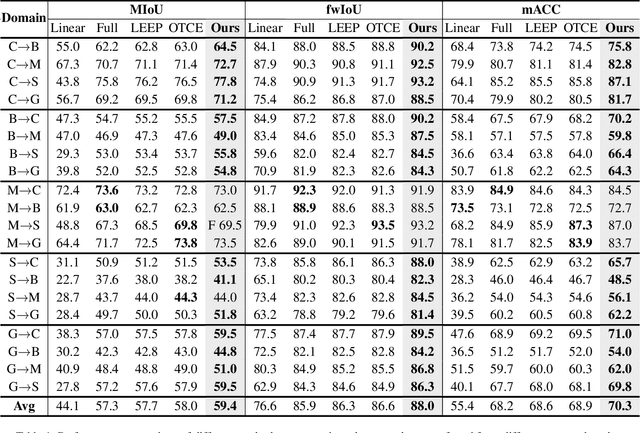
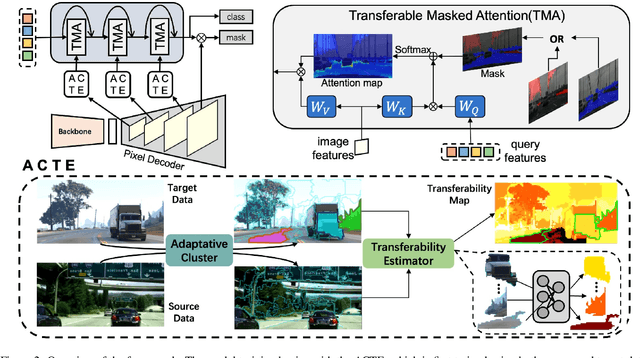
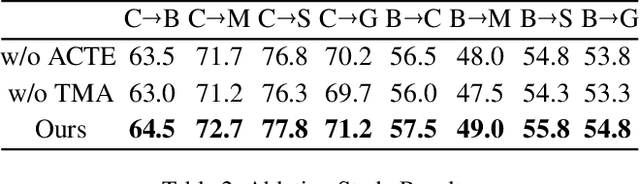
Recent advances in Vision Transformers (ViTs) have set new benchmarks in semantic segmentation. However, when adapting pretrained ViTs to new target domains, significant performance degradation often occurs due to distribution shifts, resulting in suboptimal global attention. Since self-attention mechanisms are inherently data-driven, they may fail to effectively attend to key objects when source and target domains exhibit differences in texture, scale, or object co-occurrence patterns. While global and patch-level domain adaptation methods provide partial solutions, region-level adaptation with dynamically shaped regions is crucial due to spatial heterogeneity in transferability across different image areas. We present Transferable Mask Transformer (TMT), a novel region-level adaptation framework for semantic segmentation that aligns cross-domain representations through spatial transferability analysis. TMT consists of two key components: (1) An Adaptive Cluster-based Transferability Estimator (ACTE) that dynamically segments images into structurally and semantically coherent regions for localized transferability assessment, and (2) A Transferable Masked Attention (TMA) module that integrates region-specific transferability maps into ViTs' attention mechanisms, prioritizing adaptation in regions with low transferability and high semantic uncertainty. Comprehensive evaluations across 20 cross-domain pairs demonstrate TMT's superiority, achieving an average 2% MIoU improvement over vanilla fine-tuning and a 1.28% increase compared to state-of-the-art baselines. The source code will be publicly available.
Exploiting Task Relationships for Continual Learning Using Transferability-Aware Task Embeddings
Feb 17, 2025



Continual learning (CL) has been an essential topic in the contemporary application of deep neural networks, where catastrophic forgetting (CF) can impede a model's ability to acquire knowledge progressively. Existing CL strategies primarily address CF by regularizing model updates or separating task-specific and shared components. However, these methods focus on task model elements while overlooking the potential of leveraging inter-task relationships for learning enhancement. To address this, we propose a transferability-aware task embedding named H-embedding and train a hypernet under its guidance to learn task-conditioned model weights for CL tasks. Particularly, H-embedding is introduced based on an information theoretical transferability measure and is designed to be online and easy to compute. The framework is also characterized by notable practicality, which only requires storing a low-dimensional task embedding for each task, and can be efficiently trained in an end-to-end way. Extensive evaluations and experimental analyses on datasets including Permuted MNIST, Cifar10/100, and ImageNet-R demonstrate that our framework performs prominently compared to various baseline methods, displaying great potential in exploiting intrinsic task relationships.
A Theoretical Framework for Data Efficient Multi-Source Transfer Learning Based on Cramér-Rao Bound
Feb 06, 2025



Multi-source transfer learning provides an effective solution to data scarcity in real-world supervised learning scenarios by leveraging multiple source tasks. In this field, existing works typically use all available samples from sources in training, which constrains their training efficiency and may lead to suboptimal results. To address this, we propose a theoretical framework that answers the question: what is the optimal quantity of source samples needed from each source task to jointly train the target model? Specifically, we introduce a generalization error measure that aligns with cross-entropy loss, and minimize it based on the Cram\'er-Rao Bound to determine the optimal transfer quantity for each source task. Additionally, we develop an architecture-agnostic and data-efficient algorithm OTQMS to implement our theoretical results for training deep multi-source transfer learning models. Experimental studies on diverse architectures and two real-world benchmark datasets show that our proposed algorithm significantly outperforms state-of-the-art approaches in both accuracy and data efficiency. The code and supplementary materials are available in https://anonymous.4open.science/r/Materials.
Interleaved Scene Graph for Interleaved Text-and-Image Generation Assessment
Nov 26, 2024Many real-world user queries (e.g. "How do to make egg fried rice?") could benefit from systems capable of generating responses with both textual steps with accompanying images, similar to a cookbook. Models designed to generate interleaved text and images face challenges in ensuring consistency within and across these modalities. To address these challenges, we present ISG, a comprehensive evaluation framework for interleaved text-and-image generation. ISG leverages a scene graph structure to capture relationships between text and image blocks, evaluating responses on four levels of granularity: holistic, structural, block-level, and image-specific. This multi-tiered evaluation allows for a nuanced assessment of consistency, coherence, and accuracy, and provides interpretable question-answer feedback. In conjunction with ISG, we introduce a benchmark, ISG-Bench, encompassing 1,150 samples across 8 categories and 21 subcategories. This benchmark dataset includes complex language-vision dependencies and golden answers to evaluate models effectively on vision-centric tasks such as style transfer, a challenging area for current models. Using ISG-Bench, we demonstrate that recent unified vision-language models perform poorly on generating interleaved content. While compositional approaches that combine separate language and image models show a 111% improvement over unified models at the holistic level, their performance remains suboptimal at both block and image levels. To facilitate future work, we develop ISG-Agent, a baseline agent employing a "plan-execute-refine" pipeline to invoke tools, achieving a 122% performance improvement.
The Impact of Large Language Models in Academia: from Writing to Speaking
Sep 20, 2024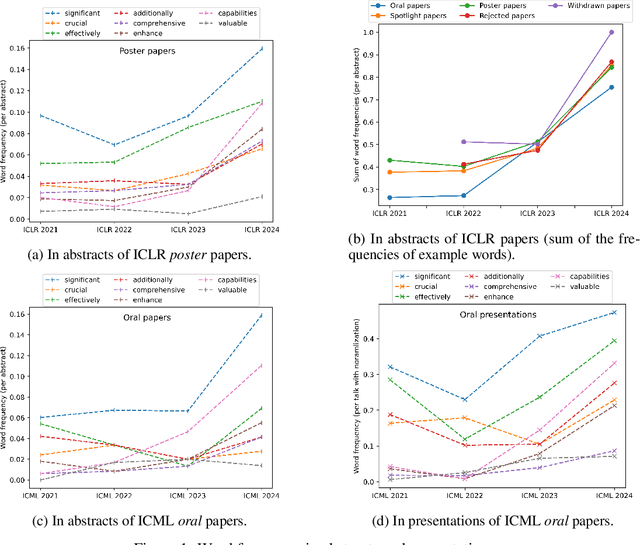

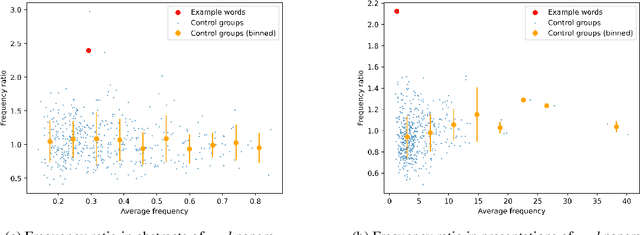

Large language models (LLMs) are increasingly impacting human society, particularly in textual information. Based on more than 30,000 papers and 1,000 presentations from machine learning conferences, we examined and compared the words used in writing and speaking, representing the first large-scale investigating study of how LLMs influence the two main modes of verbal communication and expression within the same group of people. Our empirical results show that LLM-style words such as "significant" have been used more frequently in abstracts and oral presentations. The impact on speaking is beginning to emerge and is likely to grow in the future, calling attention to the implicit influence and ripple effect of LLMs on human society.
Exploring Differences between Human Perception and Model Inference in Audio Event Recognition
Sep 10, 2024



Audio Event Recognition (AER) traditionally focuses on detecting and identifying audio events. Most existing AER models tend to detect all potential events without considering their varying significance across different contexts. This makes the AER results detected by existing models often have a large discrepancy with human auditory perception. Although this is a critical and significant issue, it has not been extensively studied by the Detection and Classification of Sound Scenes and Events (DCASE) community because solving it is time-consuming and labour-intensive. To address this issue, this paper introduces the concept of semantic importance in AER, focusing on exploring the differences between human perception and model inference. This paper constructs a Multi-Annotated Foreground Audio Event Recognition (MAFAR) dataset, which comprises audio recordings labelled by 10 professional annotators. Through labelling frequency and variance, the MAFAR dataset facilitates the quantification of semantic importance and analysis of human perception. By comparing human annotations with the predictions of ensemble pre-trained models, this paper uncovers a significant gap between human perception and model inference in both semantic identification and existence detection of audio events. Experimental results reveal that human perception tends to ignore subtle or trivial events in the event semantic identification, while model inference is easily affected by events with noises. Meanwhile, in event existence detection, models are usually more sensitive than humans.
pFedGPA: Diffusion-based Generative Parameter Aggregation for Personalized Federated Learning
Sep 09, 2024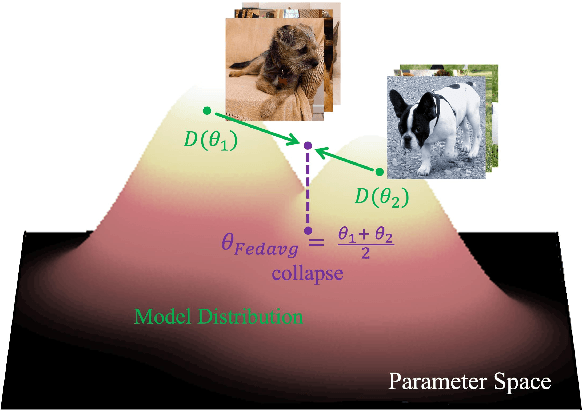
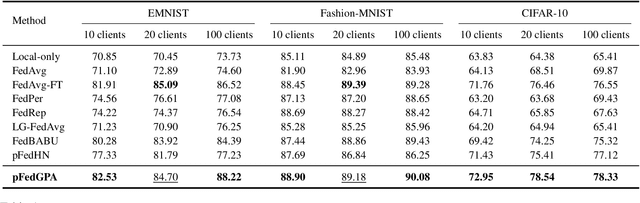
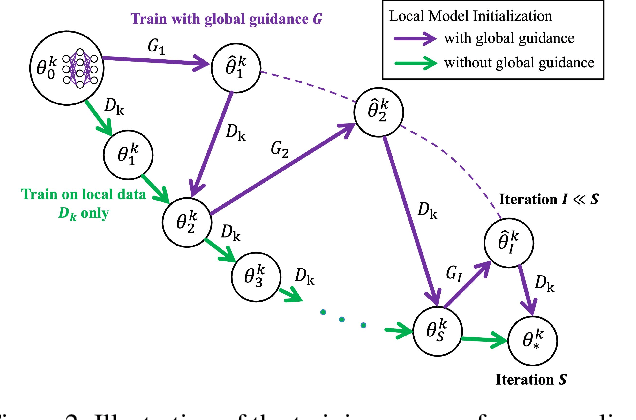
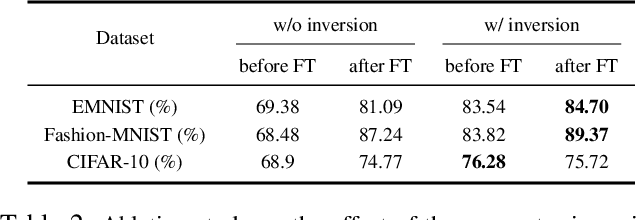
Federated Learning (FL) offers a decentralized approach to model training, where data remains local and only model parameters are shared between the clients and the central server. Traditional methods, such as Federated Averaging (FedAvg), linearly aggregate these parameters which are usually trained on heterogeneous data distributions, potentially overlooking the complex, high-dimensional nature of the parameter space. This can result in degraded performance of the aggregated model. While personalized FL approaches can mitigate the heterogeneous data issue to some extent, the limitation of linear aggregation remains unresolved. To alleviate this issue, we investigate the generative approach of diffusion model and propose a novel generative parameter aggregation framework for personalized FL, \texttt{pFedGPA}. In this framework, we deploy a diffusion model on the server to integrate the diverse parameter distributions and propose a parameter inversion method to efficiently generate a set of personalized parameters for each client. This inversion method transforms the uploaded parameters into a latent code, which is then aggregated through denoising sampling to produce the final personalized parameters. By encoding the dependence of a client's model parameters on the specific data distribution using the high-capacity diffusion model, \texttt{pFedGPA} can effectively decouple the complexity of the overall distribution of all clients' model parameters from the complexity of each individual client's parameter distribution. Our experimental results consistently demonstrate the superior performance of the proposed method across multiple datasets, surpassing baseline approaches.
Balancing Speciality and Versatility: a Coarse to Fine Framework for Supervised Fine-tuning Large Language Model
Apr 16, 2024
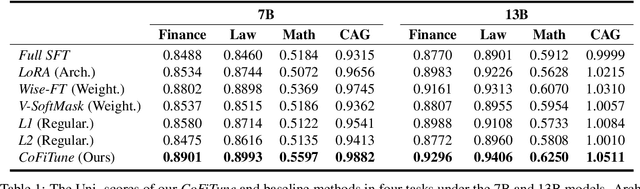
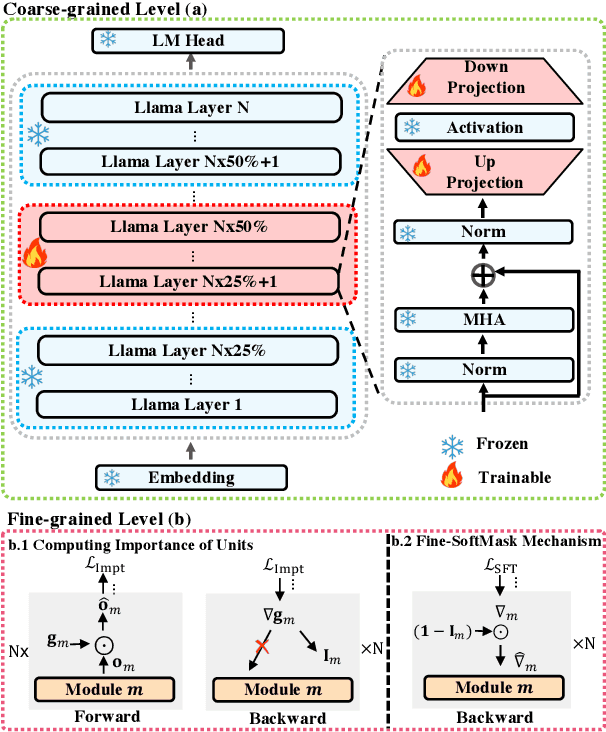
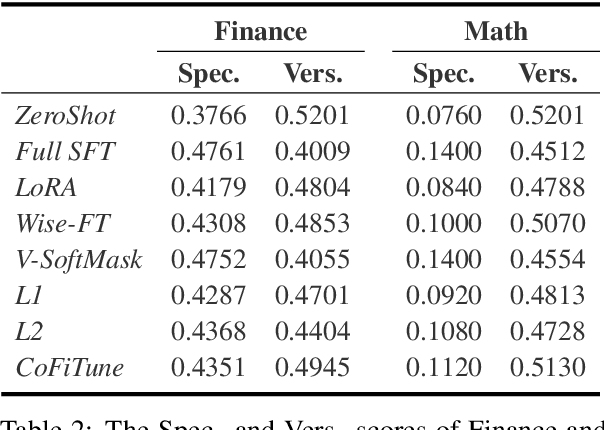
Aligned Large Language Models (LLMs) showcase remarkable versatility, capable of handling diverse real-world tasks. Meanwhile, aligned LLMs are also expected to exhibit speciality, excelling in specific applications. However, fine-tuning with extra data, a common practice to gain speciality, often leads to catastrophic forgetting (CF) of previously acquired versatility, hindering the model's performance across diverse tasks. In response to this challenge, we propose CoFiTune, a coarse to fine framework in an attempt to strike the balance between speciality and versatility. At the coarse-grained level, an empirical tree-search algorithm is utilized to pinpoint and update specific modules that are crucial for speciality, while keeping other parameters frozen; at the fine-grained level, a soft-masking mechanism regulates the update to the LLMs, mitigating the CF issue without harming speciality. In an overall evaluation of both speciality and versatility, CoFiTune consistently outperforms baseline methods across diverse tasks and model scales. Compared to the full-parameter SFT, CoFiTune leads to about 14% versatility improvement and marginal speciality loss on a 13B model. Lastly, based on further analysis, we provide a speculative insight into the information forwarding process in LLMs, which helps explain the effectiveness of the proposed method. The code is available at https://github.com/rattlesnakey/CoFiTune.