 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Differences between Human Perception and Model Inference in Audio Event Recognition
Sep 10, 2024



Audio Event Recognition (AER) traditionally focuses on detecting and identifying audio events. Most existing AER models tend to detect all potential events without considering their varying significance across different contexts. This makes the AER results detected by existing models often have a large discrepancy with human auditory perception. Although this is a critical and significant issue, it has not been extensively studied by the Detection and Classification of Sound Scenes and Events (DCASE) community because solving it is time-consuming and labour-intensive. To address this issue, this paper introduces the concept of semantic importance in AER, focusing on exploring the differences between human perception and model inference. This paper constructs a Multi-Annotated Foreground Audio Event Recognition (MAFAR) dataset, which comprises audio recordings labelled by 10 professional annotators. Through labelling frequency and variance, the MAFAR dataset facilitates the quantification of semantic importance and analysis of human perception. By comparing human annotations with the predictions of ensemble pre-trained models, this paper uncovers a significant gap between human perception and model inference in both semantic identification and existence detection of audio events. Experimental results reveal that human perception tends to ignore subtle or trivial events in the event semantic identification, while model inference is easily affected by events with noises. Meanwhile, in event existence detection, models are usually more sensitive than humans.
Soundscape Captioning using Sound Affective Quality Network and Large Language Model
Jun 09, 2024



We live in a rich and varied acoustic world, which is experienced by individuals or communities as a soundscape. Computational auditory scene analysis, disentangling acoustic scenes by detecting and classifying events, focuses on objective attributes of sounds, such as their category and temporal characteristics, ignoring the effect of sounds on people and failing to explore the relationship between sounds and the emotions they evoke within a context. To fill this gap and to automate soundscape analysis, which traditionally relies on labour-intensive subjective ratings and surveys, we propose the soundscape captioning (SoundSCap) task. SoundSCap generates context-aware soundscape descriptions by capturing the acoustic scene, event information, and the corresponding human affective qualities. To this end, we propose an automatic soundscape captioner (SoundSCaper) composed of an acoustic model, SoundAQnet, and a general large language model (LLM). SoundAQnet simultaneously models multi-scale information about acoustic scenes, events, and perceived affective qualities, while LLM generates soundscape captions by parsing the information captured by SoundAQnet to a common language. The soundscape caption's quality is assessed by a jury of 16 audio/soundscape experts. The average score (out of 5) of SoundSCaper-generated captions is lower than the score of captions generated by two soundscape experts by 0.21 and 0.25, respectively, on the evaluation set and the model-unknown mixed external dataset with varying lengths and acoustic properties, but the differences are not statistically significant. Overall, SoundSCaper-generated captions show promising performance compared to captions annotated by soundscape experts. The models' code, LLM scripts, human assessment data and instructions, and expert evaluation statistics are all publicly available.
No More Mumbles: Enhancing Robot Intelligibility through Speech Adaptation
May 15, 2024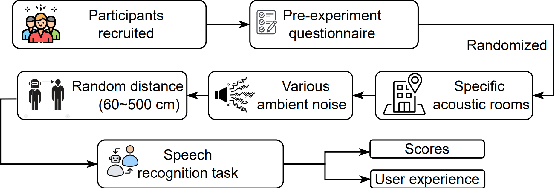


Spoken language interaction is at the heart of interpersonal communication, and people flexibly adapt their speech to different individuals and environments. It is surprising that robots, and by extension other digital devices, are not equipped to adapt their speech and instead rely on fixed speech parameters, which often hinder comprehension by the user. We conducted a speech comprehension study involving 39 participants who were exposed to different environmental and contextual conditions. During the experiment, the robot articulated words using different vocal parameters, and the participants were tasked with both recognising the spoken words and rating their subjective impression of the robot's speech. The experiment's primary outcome shows that spaces with good acoustic quality positively correlate with intelligibility and user experience. However, increasing the distance between the user and the robot exacerbated the user experience, while distracting background sounds significantly reduced speech recognition accuracy and user satisfaction. We next built an adaptive voice for the robot. For this, the robot needs to know how difficult it is for a user to understand spoken language in a particular setting. We present a prediction model that rates how annoying the ambient acoustic environment is and, consequentially, how hard it is to understand someone in this setting. Then, we develop a convolutional neural network model to adapt the robot's speech parameters to different users and spaces, while taking into account the influence of ambient acoustics on intelligibility. Finally, we present an evaluation with 27 users, demonstrating superior intelligibility and user experience with adaptive voice parameters compared to fixed voice.
Boosting Adversarial Transferability across Model Genus by Deformation-Constrained Warping
Feb 06, 2024Adversarial examples generated by a surrogate model typically exhibit limited transferability to unknown target systems. To address this problem, many transferability enhancement approaches (e.g., input transformation and model augmentation) have been proposed. However, they show poor performances in attacking systems having different model genera from the surrogate model. In this paper, we propose a novel and generic attacking strategy, called Deformation-Constrained Warping Attack (DeCoWA), that can be effectively applied to cross model genus attack. Specifically, DeCoWA firstly augments input examples via an elastic deformation, namely Deformation-Constrained Warping (DeCoW), to obtain rich local details of the augmented input. To avoid severe distortion of global semantics led by random deformation, DeCoW further constrains the strength and direction of the warping transformation by a novel adaptive control strategy. Extensive experiments demonstrate that the transferable examples crafted by our DeCoWA on CNN surrogates can significantly hinder the performance of Transformers (and vice versa) on various tasks, including image classification, video action recognition, and audio recognition. Code is made available at https://github.com/LinQinLiang/DeCoWA.
Multi-level graph learning for audio event classification and human-perceived annoyance rating prediction
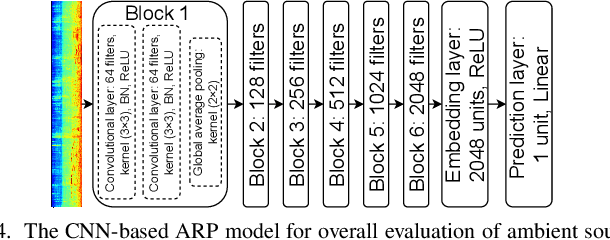
Dec 15, 2023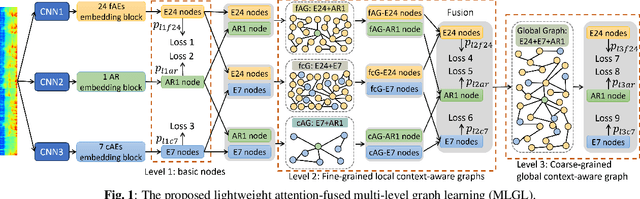
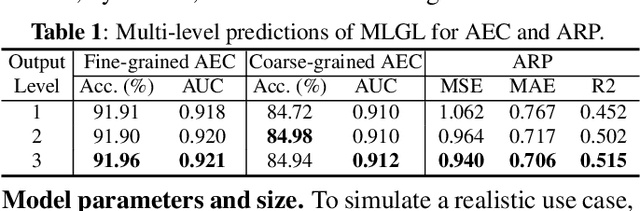
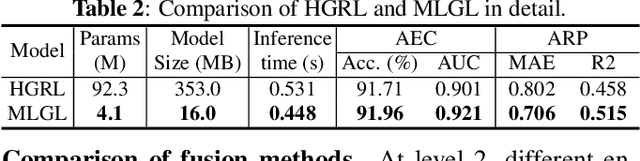
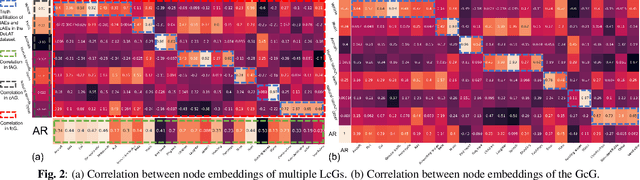
WHO's report on environmental noise estimates that 22 M people suffer from chronic annoyance related to noise caused by audio events (AEs) from various sources. Annoyance may lead to health issues and adverse effects on metabolic and cognitive systems. In cities, monitoring noise levels does not provide insights into noticeable AEs, let alone their relations to annoyance. To create annoyance-related monitoring, this paper proposes a graph-based model to identify AEs in a soundscape, and explore relations between diverse AEs and human-perceived annoyance rating (AR). Specifically, this paper proposes a lightweight multi-level graph learning (MLGL) based on local and global semantic graphs to simultaneously perform audio event classification (AEC) and human annoyance rating prediction (ARP). Experiments show that: 1) MLGL with 4.1 M parameters improves AEC and ARP results by using semantic node information in local and global context aware graphs; 2) MLGL captures relations between coarse and fine-grained AEs and AR well; 3) Statistical analysis of MLGL results shows that some AEs from different sources significantly correlate with AR, which is consistent with previous research on human perception of these sound sources.
AI-based soundscape analysis: Jointly identifying sound sources and predicting annoyance
Nov 15, 2023



Soundscape studies typically attempt to capture the perception and understanding of sonic environments by surveying users. However, for long-term monitoring or assessing interventions, sound-signal-based approaches are required. To this end, most previous research focused on psycho-acoustic quantities or automatic sound recognition. Few attempts were made to include appraisal (e.g., in circumplex frameworks). This paper proposes an artificial intelligence (AI)-based dual-branch convolutional neural network with cross-attention-based fusion (DCNN-CaF) to analyze automatic soundscape characterization, including sound recognition and appraisal. Using the DeLTA dataset containing human-annotated sound source labels and perceived annoyance, the DCNN-CaF is proposed to perform sound source classification (SSC) and human-perceived annoyance rating prediction (ARP). Experimental findings indicate that (1) the proposed DCNN-CaF using loudness and Mel features outperforms the DCNN-CaF using only one of them. (2) The proposed DCNN-CaF with cross-attention fusion outperforms other typical AI-based models and soundscape-related traditional machine learning methods on the SSC and ARP tasks. (3) Correlation analysis reveals that the relationship between sound sources and annoyance is similar for humans and the proposed AI-based DCNN-CaF model. (4) Generalization tests show that the proposed model's ARP in the presence of model-unknown sound sources is consistent with expert expectations and can explain previous findings from the literature on sound-scape augmentation.
* The Journal of the Acoustical Society of America, 154 (5), 3145
Audio Event-Relational Graph Representation Learning for Acoustic Scene Classification
Oct 05, 2023



Most deep learning-based acoustic scene classification (ASC) approaches identify scenes based on acoustic features converted from audio clips containing mixed information entangled by polyphonic audio events (AEs). However, these approaches have difficulties in explaining what cues they use to identify scenes. This paper conducts the first study on disclosing the relationship between real-life acoustic scenes and semantic embeddings from the most relevant AEs. Specifically, we propose an event-relational graph representation learning (ERGL) framework for ASC to classify scenes, and simultaneously answer clearly and straightly which cues are used in classifying. In the event-relational graph, embeddings of each event are treated as nodes, while relationship cues derived from each pair of nodes are described by multi-dimensional edge features. Experiments on a real-life ASC dataset show that the proposed ERGL achieves competitive performance on ASC by learning embeddings of only a limited number of AEs. The results show the feasibility of recognizing diverse acoustic scenes based on the audio event-relational graph. Visualizations of graph representations learned by ERGL are available here (https://github.com/Yuanbo2020/ERGL).
Joint Prediction of Audio Event and Annoyance Rating in an Urban Soundscape by Hierarchical Graph Representation Learning
Aug 23, 2023



Sound events in daily life carry rich information about the objective world. The composition of these sounds affects the mood of people in a soundscape. Most previous approaches only focus on classifying and detecting audio events and scenes, but may ignore their perceptual quality that may impact humans' listening mood for the environment, e.g. annoyance. To this end, this paper proposes a novel hierarchical graph representation learning (HGRL) approach which links objective audio events (AE) with subjective annoyance ratings (AR) of the soundscape perceived by humans. The hierarchical graph consists of fine-grained event (fAE) embeddings with single-class event semantics, coarse-grained event (cAE) embeddings with multi-class event semantics, and AR embeddings. Experiments show the proposed HGRL successfully integrates AE with AR for AEC and ARP tasks, while coordinating the relations between cAE and fAE and further aligning the two different grains of AE information with the AR.
Multi-dimensional Edge-based Audio Event Relational Graph Representation Learning for Acoustic Scene Classification
Nov 01, 2022Most existing deep learning-based acoustic scene classification (ASC) approaches directly utilize representations extracted from spectrograms to identify target scenes. However, these approaches pay little attention to the audio events occurring in the scene despite they provide crucial semantic information. This paper conducts the first study that investigates whether real-life acoustic scenes can be reliably recognized based only on the features that describe a limited number of audio events. To model the task-specific relationships between coarse-grained acoustic scenes and fine-grained audio events, we propose an event relational graph representation learning (ERGL) framework for ASC. Specifically, ERGL learns a graph representation of an acoustic scene from the input audio, where the embedding of each event is treated as a node, while the relationship cues derived from each pair of event embeddings are described by a learned multidimensional edge feature. Experiments on a polyphonic acoustic scene dataset show that the proposed ERGL achieves competitive performance on ASC by using only a limited number of embeddings of audio events without any data augmentations. The validity of the proposed ERGL framework proves the feasibility of recognizing diverse acoustic scenes based on the event relational graph. Our code is available on our homepage (https://github.com/Yuanbo2020/ERGL).
GCT: Gated Contextual Transformer for Sequential Audio Tagging
Oct 22, 2022



Audio tagging aims to assign predefined tags to audio clips to indicate the class information of audio events. Sequential audio tagging (SAT) means detecting both the class information of audio events, and the order in which they occur within the audio clip. Most existing methods for SAT are based on connectionist temporal classification (CTC). However, CTC cannot effectively capture connections between events due to the conditional independence assumption between outputs at different times. The contextual Transformer (cTransformer) addresses this issue by exploiting contextual information in SAT. Nevertheless, cTransformer is also limited in exploiting contextual information as it only uses forward information in inference. This paper proposes a gated contextual Transformer (GCT) with forward-backward inference (FBI). In addition, a gated contextual multi-layer perceptron (GCMLP) block is proposed in GCT to improve the performance of cTransformer structurally. Experiments on two real-life audio datasets show that the proposed GCT with GCMLP and FBI performs better than the CTC-based methods and cTransformer. To promote research on SAT, the manually annotated sequential labels for the two datasets are released.