 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo More Mumbles: Enhancing Robot Intelligibility through Speech Adaptation
Paper and Code
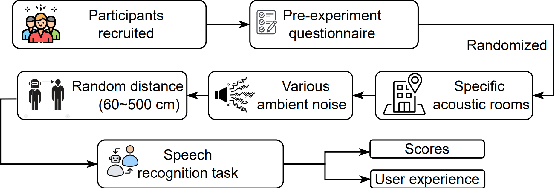


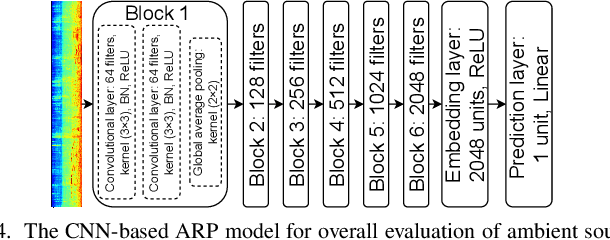
Spoken language interaction is at the heart of interpersonal communication, and people flexibly adapt their speech to different individuals and environments. It is surprising that robots, and by extension other digital devices, are not equipped to adapt their speech and instead rely on fixed speech parameters, which often hinder comprehension by the user. We conducted a speech comprehension study involving 39 participants who were exposed to different environmental and contextual conditions. During the experiment, the robot articulated words using different vocal parameters, and the participants were tasked with both recognising the spoken words and rating their subjective impression of the robot's speech. The experiment's primary outcome shows that spaces with good acoustic quality positively correlate with intelligibility and user experience. However, increasing the distance between the user and the robot exacerbated the user experience, while distracting background sounds significantly reduced speech recognition accuracy and user satisfaction. We next built an adaptive voice for the robot. For this, the robot needs to know how difficult it is for a user to understand spoken language in a particular setting. We present a prediction model that rates how annoying the ambient acoustic environment is and, consequentially, how hard it is to understand someone in this setting. Then, we develop a convolutional neural network model to adapt the robot's speech parameters to different users and spaces, while taking into account the influence of ambient acoustics on intelligibility. Finally, we present an evaluation with 27 users, demonstrating superior intelligibility and user experience with adaptive voice parameters compared to fixed voice.