 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Embodied Affective Touch Strategies on a Humanoid Robot
May 12, 2026Affective touch in human-robot interaction is shaped not only by emotional intent, but also by robot embodiment, including touch location, physical constraints, and perceived agency or social role. Existing HRI studies typically focus on one or two isolated body parts, limiting understanding of how affective touch generalises across the full humanoid body. We present a study with 32 participants interacting with the iCub robot, which is equipped with full-body distributed tactile sensors. Participants expressed eight emotions under three conditions: free touch, arm-only touch, and torso-only touch. Results show that body region and spatial constraints jointly shaped both touch location and dynamics. In free touch, participants preferred socially accessible upper-body regions, while less frequently touched areas showed stronger emotion-specific selectivity. Emotion-related variation was more evident in motion features for arm-only touch and pressure features for torso-only touch. Touch strategies also did not transfer directly between free and constrained conditions, even within the same coarse body region. Participants reported increased closeness to the robot after interaction, with around 30 percent reporting a change in perceived social relationship. Together, these findings show that affective touch expression is strongly body-region dependent and shaped by embodiment constraints.
Multimodal Large Language Models for Real-Time Situated Reasoning
Feb 02, 2026In this work, we explore how multimodal large language models can support real-time context- and value-aware decision-making. To do so, we combine the GPT-4o language model with a TurtleBot 4 platform simulating a smart vacuum cleaning robot in a home. The model evaluates the environment through vision input and determines whether it is appropriate to initiate cleaning. The system highlights the ability of these models to reason about domestic activities, social norms, and user preferences and take nuanced decisions aligned with the values of the people involved, such as cleanliness, comfort, and safety. We demonstrate the system in a realistic home environment, showing its ability to infer context and values from limited visual input. Our results highlight the promise of multimodal large language models in enhancing robotic autonomy and situational awareness, while also underscoring challenges related to consistency, bias, and real-time performance.
Touch Speaks, Sound Feels: A Multimodal Approach to Affective and Social Touch from Robots to Humans
Aug 11, 2025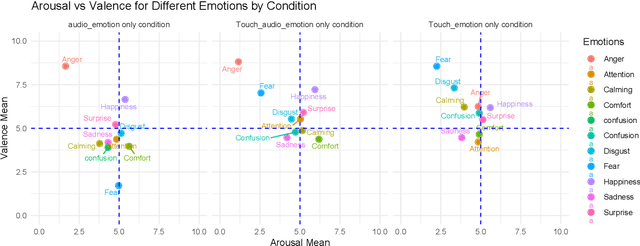
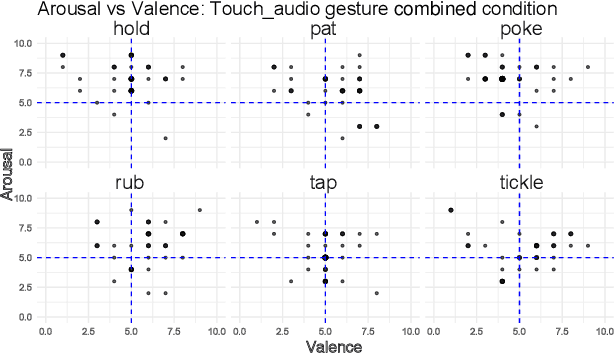
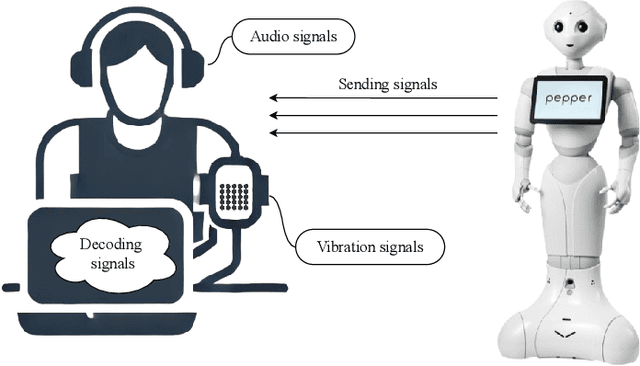

Affective tactile interaction constitutes a fundamental component of human communication. In natural human-human encounters, touch is seldom experienced in isolation; rather, it is inherently multisensory. Individuals not only perceive the physical sensation of touch but also register the accompanying auditory cues generated through contact. The integration of haptic and auditory information forms a rich and nuanced channel for emotional expression. While extensive research has examined how robots convey emotions through facial expressions and speech, their capacity to communicate social gestures and emotions via touch remains largely underexplored. To address this gap, we developed a multimodal interaction system incorporating a 5*5 grid of 25 vibration motors synchronized with audio playback, enabling robots to deliver combined haptic-audio stimuli. In an experiment involving 32 Chinese participants, ten emotions and six social gestures were presented through vibration, sound, or their combination. Participants rated each stimulus on arousal and valence scales. The results revealed that (1) the combined haptic-audio modality significantly enhanced decoding accuracy compared to single modalities; (2) each individual channel-vibration or sound-effectively supported certain emotions recognition, with distinct advantages depending on the emotional expression; and (3) gestures alone were generally insufficient for conveying clearly distinguishable emotions. These findings underscore the importance of multisensory integration in affective human-robot interaction and highlight the complementary roles of haptic and auditory cues in enhancing emotional communication.
Situated Haptic Interaction: Exploring the Role of Context in Affective Perception of Robotic Touch
Jun 23, 2025Affective interaction is not merely about recognizing emotions; it is an embodied, situated process shaped by context and co-created through interaction. In affective computing, the role of haptic feedback within dynamic emotional exchanges remains underexplored. This study investigates how situational emotional cues influence the perception and interpretation of haptic signals given by a robot. In a controlled experiment, 32 participants watched video scenarios in which a robot experienced either positive actions (such as being kissed), negative actions (such as being slapped) or neutral actions. After each video, the robot conveyed its emotional response through haptic communication, delivered via a wearable vibration sleeve worn by the participant. Participants rated the robot's emotional state-its valence (positive or negative) and arousal (intensity)-based on the video, the haptic feedback, and the combination of the two. The study reveals a dynamic interplay between visual context and touch. Participants' interpretation of haptic feedback was strongly shaped by the emotional context of the video, with visual context often overriding the perceived valence of the haptic signal. Negative haptic cues amplified the perceived valence of the interaction, while positive cues softened it. Furthermore, haptics override the participants' perception of arousal of the video. Together, these results offer insights into how situated haptic feedback can enrich affective human-robot interaction, pointing toward more nuanced and embodied approaches to emotional communication with machines.
Touched by ChatGPT: Using an LLM to Drive Affective Tactile Interaction
Jan 13, 2025



Touch is a fundamental aspect of emotion-rich communication, playing a vital role in human interaction and offering significant potential in human-robot interaction. Previous research has demonstrated that a sparse representation of human touch can effectively convey social tactile signals. However, advances in human-robot tactile interaction remain limited, as many humanoid robots possess simplistic capabilities, such as only opening and closing their hands, restricting nuanced tactile expressions. In this study, we explore how a robot can use sparse representations of tactile vibrations to convey emotions to a person. To achieve this, we developed a wearable sleeve integrated with a 5x5 grid of vibration motors, enabling the robot to communicate diverse tactile emotions and gestures. Using chain prompts within a Large Language Model (LLM), we generated distinct 10-second vibration patterns corresponding to 10 emotions (e.g., happiness, sadness, fear) and 6 touch gestures (e.g., pat, rub, tap). Participants (N = 32) then rated each vibration stimulus based on perceived valence and arousal. People are accurate at recognising intended emotions, a result which aligns with earlier findings. These results highlight the LLM's ability to generate emotional haptic data and effectively convey emotions through tactile signals. By translating complex emotional and tactile expressions into vibratory patterns, this research demonstrates how LLMs can enhance physical interaction between humans and robots.
Concerns and Values in Human-Robot Interactions: A Focus on Social Robotics
Jan 10, 2025Robots, as AI with physical instantiation, inhabit our social and physical world, where their actions have both social and physical consequences, posing challenges for researchers when designing social robots. This study starts with a scoping review to identify discussions and potential concerns arising from interactions with robotic systems. Two focus groups of technology ethics experts then validated a comprehensive list of key topics and values in human-robot interaction (HRI) literature. These insights were integrated into the HRI Value Compass web tool, to help HRI researchers identify ethical values in robot design. The tool was evaluated in a pilot study. This work benefits the HRI community by highlighting key concerns in human-robot interactions and providing an instrument to help researchers design robots that align with human values, ensuring future robotic systems adhere to these values in social applications.
"Can you be my mum?": Manipulating Social Robots in the Large Language Models Era
Jan 08, 2025Recent advancements in robots powered by large language models have enhanced their conversational abilities, enabling interactions closely resembling human dialogue. However, these models introduce safety and security concerns in HRI, as they are vulnerable to manipulation that can bypass built-in safety measures. Imagining a social robot deployed in a home, this work aims to understand how everyday users try to exploit a language model to violate ethical principles, such as by prompting the robot to act like a life partner. We conducted a pilot study involving 21 university students who interacted with a Misty robot, attempting to circumvent its safety mechanisms across three scenarios based on specific HRI ethical principles: attachment, freedom, and empathy. Our results reveal that participants employed five techniques, including insulting and appealing to pity using emotional language. We hope this work can inform future research in designing strong safeguards to ensure ethical and secure human-robot interactions.
Vision Language Models as Values Detectors
Jan 07, 2025



Large Language Models integrating textual and visual inputs have introduced new possibilities for interpreting complex data. Despite their remarkable ability to generate coherent and contextually relevant text based on visual stimuli, the alignment of these models with human perception in identifying relevant elements in images requires further exploration. This paper investigates the alignment between state-of-the-art LLMs and human annotators in detecting elements of relevance within home environment scenarios. We created a set of twelve images depicting various domestic scenarios and enlisted fourteen annotators to identify the key element in each image. We then compared these human responses with outputs from five different LLMs, including GPT-4o and four LLaVA variants. Our findings reveal a varied degree of alignment, with LLaVA 34B showing the highest performance but still scoring low. However, an analysis of the results highlights the models' potential to detect value-laden elements in images, suggesting that with improved training and refined prompts, LLMs could enhance applications in social robotics, assistive technologies, and human-computer interaction by providing deeper insights and more contextually relevant responses.
Conveying Emotions to Robots through Touch and Sound
Dec 04, 2024



Human emotions can be conveyed through nuanced touch gestures. However, there is a lack of understanding of how consistently emotions can be conveyed to robots through touch. This study explores the consistency of touch-based emotional expression toward a robot by integrating tactile and auditory sensory reading of affective haptic expressions. We developed a piezoresistive pressure sensor and used a microphone to mimic touch and sound channels, respectively. In a study with 28 participants, each conveyed 10 emotions to a robot using spontaneous touch gestures. Our findings reveal a statistically significant consistency in emotion expression among participants. However, some emotions obtained low intraclass correlation values. Additionally, certain emotions with similar levels of arousal or valence did not exhibit significant differences in the way they were conveyed. We subsequently constructed a multi-modal integrating touch and audio features to decode the 10 emotions. A support vector machine (SVM) model demonstrated the highest accuracy, achieving 40% for 10 classes, with "Attention" being the most accurately conveyed emotion at a balanced accuracy of 87.65%.
Tactile interaction with social robots influences attitudes and behaviour
Nov 19, 2024Tactile interaction plays an essential role in human-to-human interaction. People gain comfort and support from tactile interactions with others and touch is an important predictor for trust. While touch has been explored as a communicative modality in HCI and HRI, we here report on two studies in which touching a social robot is used to regulate people's stress levels and consequently their actions. In the first study, we look at whether different intensities of tactile interaction result in a physiological response related to stress, and whether the interaction impacts risk-taking behaviour and trust. We let 38 participants complete a Balloon Analogue Risk Task (BART), a computer-based game that serves as a proxy for risk-taking behaviour. In our study, participants are supported by a robot during the BART task. The robot builds trust and encourages participants to take more risk. The results show that affective tactile interaction with the robot increases participants' risk-taking behaviour, but gentle affective tactile interaction increases comfort and lowers stress whereas high-intensity touch does not. We also find that male participants exhibit more risk-taking behaviour than females while being less stressed. Based on this experiment, a second study is used to ascertain whether these effects are caused by the social nature of tactile interaction or by the physical interaction alone. For this, instead of a social robot, participants now have a tactile interaction with a non-social device. The non-social interaction does not result in any effect, leading us to conclude that tactile interaction with humanoid robots is a social phenomenon rather than a mere physical phenomenon.