 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Embodied Affective Touch Strategies on a Humanoid Robot
May 12, 2026Affective touch in human-robot interaction is shaped not only by emotional intent, but also by robot embodiment, including touch location, physical constraints, and perceived agency or social role. Existing HRI studies typically focus on one or two isolated body parts, limiting understanding of how affective touch generalises across the full humanoid body. We present a study with 32 participants interacting with the iCub robot, which is equipped with full-body distributed tactile sensors. Participants expressed eight emotions under three conditions: free touch, arm-only touch, and torso-only touch. Results show that body region and spatial constraints jointly shaped both touch location and dynamics. In free touch, participants preferred socially accessible upper-body regions, while less frequently touched areas showed stronger emotion-specific selectivity. Emotion-related variation was more evident in motion features for arm-only touch and pressure features for torso-only touch. Touch strategies also did not transfer directly between free and constrained conditions, even within the same coarse body region. Participants reported increased closeness to the robot after interaction, with around 30 percent reporting a change in perceived social relationship. Together, these findings show that affective touch expression is strongly body-region dependent and shaped by embodiment constraints.
Geo-ATBench: A Benchmark for Geospatial Audio Tagging with Geospatial Semantic Context
Mar 11, 2026Environmental sound understanding in computational auditory scene analysis (CASA) is often formulated as an audio-only recognition problem. This formulation leaves a persistent drawback in multi-label audio tagging (AT): acoustic similarity can make certain events difficult to separate from waveforms alone. In such cases, disambiguating cues often lie outside the waveform. Geospatial semantic context (GSC), derived from geographic information system data, e.g., points of interest (POI), provides location-tied environmental priors that can help reduce this ambiguity. A systematic study of this direction is enabled through the proposed geospatial audio tagging (Geo-AT) task, which conditions multi-label sound event tagging on GSC alongside audio. To benchmark Geo-AT, Geo-ATBench is introduced as a polyphonic audio benchmark with geographical annotations, containing 10.71 hours of audio across 28 event categories; each clip is paired with a GSC representation from 11 semantic context categories. GeoFusion-AT is proposed as a unified geo-audio fusion framework that evaluates feature-, representation-, and decision-level fusion on representative audio backbones, with audio- and GSC-only baselines. Results show that incorporating GSC improves AT performance, especially on acoustically confounded labels, indicating geospatial semantics provide effective priors beyond audio alone. A crowdsourced listening study with 10 participants on 579 samples shows that there is no significant difference in performance between models on Geo-ATBench labels and aggregated human labels, supporting Geo-ATBench as a human-aligned benchmark. The Geo-AT task, benchmark Geo-ATBench, and reproducible geo-audio fusion framework GeoFusion-AT provide a foundation for studying AT with geospatial semantic context within the CASA community. Dataset, code, models are on homepage (https://github.com/WuYanru2002/Geo-ATBench).
Touch Speaks, Sound Feels: A Multimodal Approach to Affective and Social Touch from Robots to Humans
Aug 11, 2025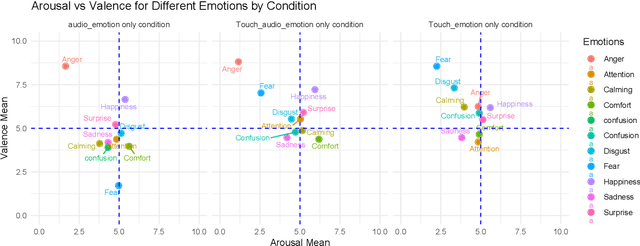
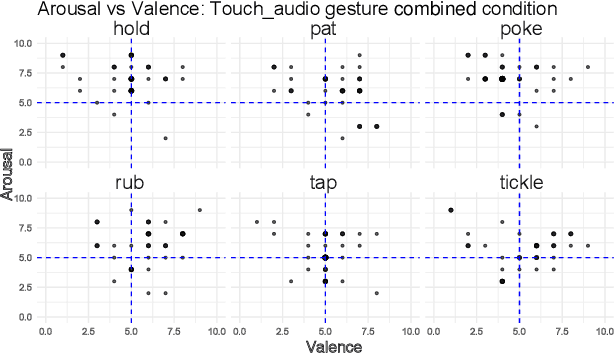

Affective tactile interaction constitutes a fundamental component of human communication. In natural human-human encounters, touch is seldom experienced in isolation; rather, it is inherently multisensory. Individuals not only perceive the physical sensation of touch but also register the accompanying auditory cues generated through contact. The integration of haptic and auditory information forms a rich and nuanced channel for emotional expression. While extensive research has examined how robots convey emotions through facial expressions and speech, their capacity to communicate social gestures and emotions via touch remains largely underexplored. To address this gap, we developed a multimodal interaction system incorporating a 5*5 grid of 25 vibration motors synchronized with audio playback, enabling robots to deliver combined haptic-audio stimuli. In an experiment involving 32 Chinese participants, ten emotions and six social gestures were presented through vibration, sound, or their combination. Participants rated each stimulus on arousal and valence scales. The results revealed that (1) the combined haptic-audio modality significantly enhanced decoding accuracy compared to single modalities; (2) each individual channel-vibration or sound-effectively supported certain emotions recognition, with distinct advantages depending on the emotional expression; and (3) gestures alone were generally insufficient for conveying clearly distinguishable emotions. These findings underscore the importance of multisensory integration in affective human-robot interaction and highlight the complementary roles of haptic and auditory cues in enhancing emotional communication.
Situated Haptic Interaction: Exploring the Role of Context in Affective Perception of Robotic Touch
Jun 23, 2025Affective interaction is not merely about recognizing emotions; it is an embodied, situated process shaped by context and co-created through interaction. In affective computing, the role of haptic feedback within dynamic emotional exchanges remains underexplored. This study investigates how situational emotional cues influence the perception and interpretation of haptic signals given by a robot. In a controlled experiment, 32 participants watched video scenarios in which a robot experienced either positive actions (such as being kissed), negative actions (such as being slapped) or neutral actions. After each video, the robot conveyed its emotional response through haptic communication, delivered via a wearable vibration sleeve worn by the participant. Participants rated the robot's emotional state-its valence (positive or negative) and arousal (intensity)-based on the video, the haptic feedback, and the combination of the two. The study reveals a dynamic interplay between visual context and touch. Participants' interpretation of haptic feedback was strongly shaped by the emotional context of the video, with visual context often overriding the perceived valence of the haptic signal. Negative haptic cues amplified the perceived valence of the interaction, while positive cues softened it. Furthermore, haptics override the participants' perception of arousal of the video. Together, these results offer insights into how situated haptic feedback can enrich affective human-robot interaction, pointing toward more nuanced and embodied approaches to emotional communication with machines.
Touched by ChatGPT: Using an LLM to Drive Affective Tactile Interaction
Jan 13, 2025



Touch is a fundamental aspect of emotion-rich communication, playing a vital role in human interaction and offering significant potential in human-robot interaction. Previous research has demonstrated that a sparse representation of human touch can effectively convey social tactile signals. However, advances in human-robot tactile interaction remain limited, as many humanoid robots possess simplistic capabilities, such as only opening and closing their hands, restricting nuanced tactile expressions. In this study, we explore how a robot can use sparse representations of tactile vibrations to convey emotions to a person. To achieve this, we developed a wearable sleeve integrated with a 5x5 grid of vibration motors, enabling the robot to communicate diverse tactile emotions and gestures. Using chain prompts within a Large Language Model (LLM), we generated distinct 10-second vibration patterns corresponding to 10 emotions (e.g., happiness, sadness, fear) and 6 touch gestures (e.g., pat, rub, tap). Participants (N = 32) then rated each vibration stimulus based on perceived valence and arousal. People are accurate at recognising intended emotions, a result which aligns with earlier findings. These results highlight the LLM's ability to generate emotional haptic data and effectively convey emotions through tactile signals. By translating complex emotional and tactile expressions into vibratory patterns, this research demonstrates how LLMs can enhance physical interaction between humans and robots.
Conveying Emotions to Robots through Touch and Sound
Dec 04, 2024



Human emotions can be conveyed through nuanced touch gestures. However, there is a lack of understanding of how consistently emotions can be conveyed to robots through touch. This study explores the consistency of touch-based emotional expression toward a robot by integrating tactile and auditory sensory reading of affective haptic expressions. We developed a piezoresistive pressure sensor and used a microphone to mimic touch and sound channels, respectively. In a study with 28 participants, each conveyed 10 emotions to a robot using spontaneous touch gestures. Our findings reveal a statistically significant consistency in emotion expression among participants. However, some emotions obtained low intraclass correlation values. Additionally, certain emotions with similar levels of arousal or valence did not exhibit significant differences in the way they were conveyed. We subsequently constructed a multi-modal integrating touch and audio features to decode the 10 emotions. A support vector machine (SVM) model demonstrated the highest accuracy, achieving 40% for 10 classes, with "Attention" being the most accurately conveyed emotion at a balanced accuracy of 87.65%.
Tactile interaction with social robots influences attitudes and behaviour
Nov 19, 2024Tactile interaction plays an essential role in human-to-human interaction. People gain comfort and support from tactile interactions with others and touch is an important predictor for trust. While touch has been explored as a communicative modality in HCI and HRI, we here report on two studies in which touching a social robot is used to regulate people's stress levels and consequently their actions. In the first study, we look at whether different intensities of tactile interaction result in a physiological response related to stress, and whether the interaction impacts risk-taking behaviour and trust. We let 38 participants complete a Balloon Analogue Risk Task (BART), a computer-based game that serves as a proxy for risk-taking behaviour. In our study, participants are supported by a robot during the BART task. The robot builds trust and encourages participants to take more risk. The results show that affective tactile interaction with the robot increases participants' risk-taking behaviour, but gentle affective tactile interaction increases comfort and lowers stress whereas high-intensity touch does not. We also find that male participants exhibit more risk-taking behaviour than females while being less stressed. Based on this experiment, a second study is used to ascertain whether these effects are caused by the social nature of tactile interaction or by the physical interaction alone. For this, instead of a social robot, participants now have a tactile interaction with a non-social device. The non-social interaction does not result in any effect, leading us to conclude that tactile interaction with humanoid robots is a social phenomenon rather than a mere physical phenomenon.
Soundscape Captioning using Sound Affective Quality Network and Large Language Model
Jun 09, 2024



We live in a rich and varied acoustic world, which is experienced by individuals or communities as a soundscape. Computational auditory scene analysis, disentangling acoustic scenes by detecting and classifying events, focuses on objective attributes of sounds, such as their category and temporal characteristics, ignoring the effect of sounds on people and failing to explore the relationship between sounds and the emotions they evoke within a context. To fill this gap and to automate soundscape analysis, which traditionally relies on labour-intensive subjective ratings and surveys, we propose the soundscape captioning (SoundSCap) task. SoundSCap generates context-aware soundscape descriptions by capturing the acoustic scene, event information, and the corresponding human affective qualities. To this end, we propose an automatic soundscape captioner (SoundSCaper) composed of an acoustic model, SoundAQnet, and a general large language model (LLM). SoundAQnet simultaneously models multi-scale information about acoustic scenes, events, and perceived affective qualities, while LLM generates soundscape captions by parsing the information captured by SoundAQnet to a common language. The soundscape caption's quality is assessed by a jury of 16 audio/soundscape experts. The average score (out of 5) of SoundSCaper-generated captions is lower than the score of captions generated by two soundscape experts by 0.21 and 0.25, respectively, on the evaluation set and the model-unknown mixed external dataset with varying lengths and acoustic properties, but the differences are not statistically significant. Overall, SoundSCaper-generated captions show promising performance compared to captions annotated by soundscape experts. The models' code, LLM scripts, human assessment data and instructions, and expert evaluation statistics are all publicly available.
No More Mumbles: Enhancing Robot Intelligibility through Speech Adaptation
May 15, 2024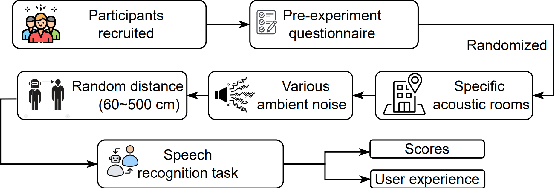


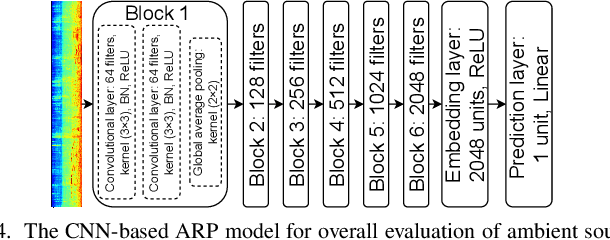
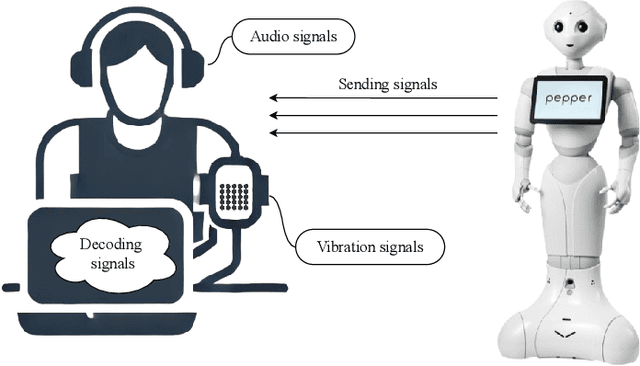
Spoken language interaction is at the heart of interpersonal communication, and people flexibly adapt their speech to different individuals and environments. It is surprising that robots, and by extension other digital devices, are not equipped to adapt their speech and instead rely on fixed speech parameters, which often hinder comprehension by the user. We conducted a speech comprehension study involving 39 participants who were exposed to different environmental and contextual conditions. During the experiment, the robot articulated words using different vocal parameters, and the participants were tasked with both recognising the spoken words and rating their subjective impression of the robot's speech. The experiment's primary outcome shows that spaces with good acoustic quality positively correlate with intelligibility and user experience. However, increasing the distance between the user and the robot exacerbated the user experience, while distracting background sounds significantly reduced speech recognition accuracy and user satisfaction. We next built an adaptive voice for the robot. For this, the robot needs to know how difficult it is for a user to understand spoken language in a particular setting. We present a prediction model that rates how annoying the ambient acoustic environment is and, consequentially, how hard it is to understand someone in this setting. Then, we develop a convolutional neural network model to adapt the robot's speech parameters to different users and spaces, while taking into account the influence of ambient acoustics on intelligibility. Finally, we present an evaluation with 27 users, demonstrating superior intelligibility and user experience with adaptive voice parameters compared to fixed voice.
Child Speech Recognition in Human-Robot Interaction: Problem Solved?
Apr 26, 2024



Automated Speech Recognition shows superhuman performance for adult English speech on a range of benchmarks, but disappoints when fed children's speech. This has long sat in the way of child-robot interaction. Recent evolutions in data-driven speech recognition, including the availability of Transformer architectures and unprecedented volumes of training data, might mean a breakthrough for child speech recognition and social robot applications aimed at children. We revisit a study on child speech recognition from 2017 and show that indeed performance has increased, with newcomer OpenAI Whisper doing markedly better than leading commercial cloud services. While transcription is not perfect yet, the best model recognises 60.3% of sentences correctly barring small grammatical differences, with sub-second transcription time running on a local GPU, showing potential for usable autonomous child-robot speech interactions.