 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConveying Emotions to Robots through Touch and Sound
Dec 04, 2024



Human emotions can be conveyed through nuanced touch gestures. However, there is a lack of understanding of how consistently emotions can be conveyed to robots through touch. This study explores the consistency of touch-based emotional expression toward a robot by integrating tactile and auditory sensory reading of affective haptic expressions. We developed a piezoresistive pressure sensor and used a microphone to mimic touch and sound channels, respectively. In a study with 28 participants, each conveyed 10 emotions to a robot using spontaneous touch gestures. Our findings reveal a statistically significant consistency in emotion expression among participants. However, some emotions obtained low intraclass correlation values. Additionally, certain emotions with similar levels of arousal or valence did not exhibit significant differences in the way they were conveyed. We subsequently constructed a multi-modal integrating touch and audio features to decode the 10 emotions. A support vector machine (SVM) model demonstrated the highest accuracy, achieving 40% for 10 classes, with "Attention" being the most accurately conveyed emotion at a balanced accuracy of 87.65%.
CenDerNet: Center and Curvature Representations for Render-and-Compare 6D Pose Estimation
Aug 21, 2022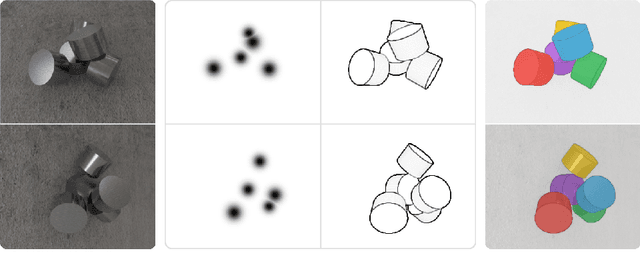
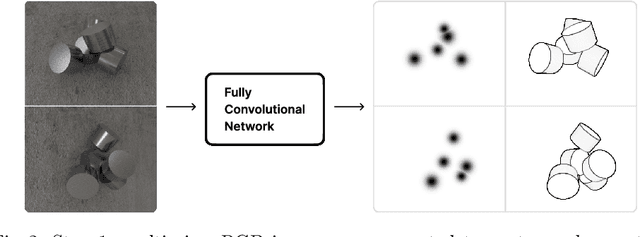
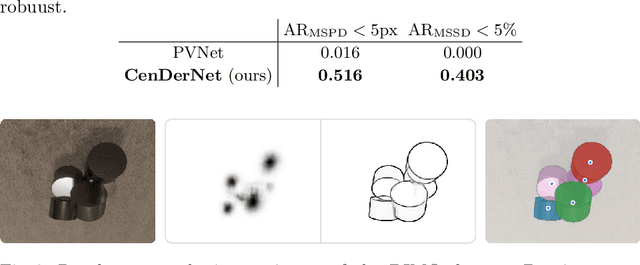
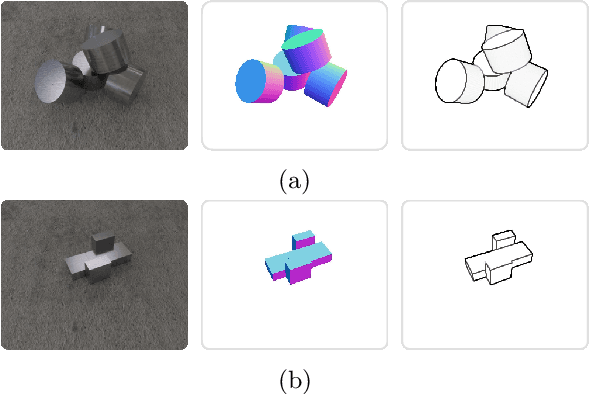
We introduce CenDerNet, a framework for 6D pose estimation from multi-view images based on center and curvature representations. Finding precise poses for reflective, textureless objects is a key challenge for industrial robotics. Our approach consists of three stages: First, a fully convolutional neural network predicts center and curvature heatmaps for each view; Second, center heatmaps are used to detect object instances and find their 3D centers; Third, 6D object poses are estimated using 3D centers and curvature heatmaps. By jointly optimizing poses across views using a render-and-compare approach, our method naturally handles occlusions and object symmetries. We show that CenDerNet outperforms previous methods on two industry-relevant datasets: DIMO and T-LESS.