 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCenDerNet: Center and Curvature Representations for Render-and-Compare 6D Pose Estimation
Paper and Code
Aug 21, 2022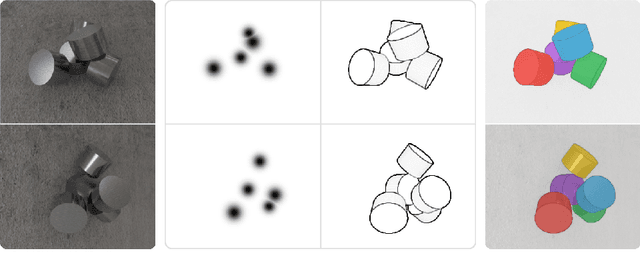
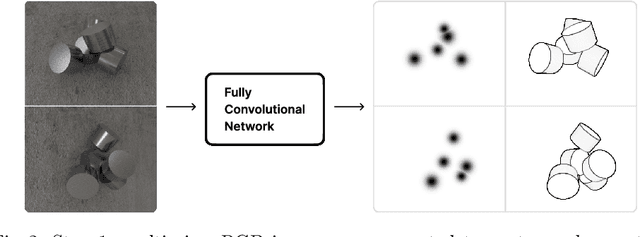
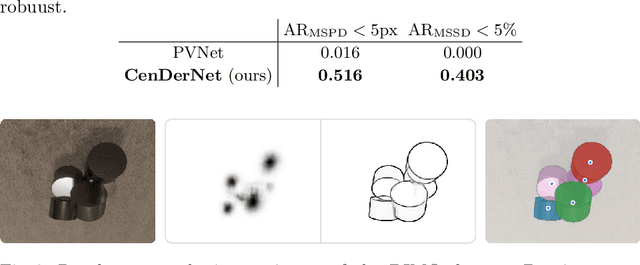
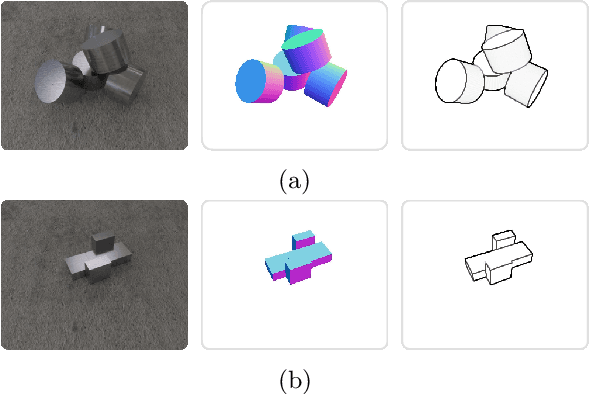
We introduce CenDerNet, a framework for 6D pose estimation from multi-view images based on center and curvature representations. Finding precise poses for reflective, textureless objects is a key challenge for industrial robotics. Our approach consists of three stages: First, a fully convolutional neural network predicts center and curvature heatmaps for each view; Second, center heatmaps are used to detect object instances and find their 3D centers; Third, 6D object poses are estimated using 3D centers and curvature heatmaps. By jointly optimizing poses across views using a render-and-compare approach, our method naturally handles occlusions and object symmetries. We show that CenDerNet outperforms previous methods on two industry-relevant datasets: DIMO and T-LESS.