 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing
Mar 19, 2026Current instruction-guided video editing models struggle to simultaneously balance precise semantic modifications with faithful motion preservation. While existing approaches rely on injecting explicit external priors (e.g., VLM features or structural conditions) to mitigate these issues, this reliance severely bottlenecks model robustness and generalization. To overcome this limitation, we present SAMA (factorized Semantic Anchoring and Motion Alignment), a framework that factorizes video editing into semantic anchoring and motion modeling. First, we introduce Semantic Anchoring, which establishes a reliable visual anchor by jointly predicting semantic tokens and video latents at sparse anchor frames, enabling purely instruction-aware structural planning. Second, Motion Alignment pre-trains the same backbone on motion-centric video restoration pretext tasks (cube inpainting, speed perturbation, and tube shuffle), enabling the model to internalize temporal dynamics directly from raw videos. SAMA is optimized with a two-stage pipeline: a factorized pre-training stage that learns inherent semantic-motion representations without paired video-instruction editing data, followed by supervised fine-tuning on paired editing data. Remarkably, the factorized pre-training alone already yields strong zero-shot video editing ability, validating the proposed factorization. SAMA achieves state-of-the-art performance among open-source models and is competitive with leading commercial systems (e.g., Kling-Omni). Code, models, and datasets will be released.
ViSS-R1: Self-Supervised Reinforcement Video Reasoning
Nov 17, 2025Complex video reasoning remains a significant challenge for Multimodal Large Language Models (MLLMs), as current R1-based methodologies often prioritize text-centric reasoning derived from text-based and image-based developments. In video tasks, such strategies frequently underutilize rich visual information, leading to potential shortcut learning and increased susceptibility to hallucination. To foster a more robust, visual-centric video understanding, we start by introducing a novel self-supervised reinforcement learning GRPO algorithm (Pretext-GRPO) within the standard R1 pipeline, in which positive rewards are assigned for correctly solving pretext tasks on transformed visual inputs, which makes the model to non-trivially process the visual information. Building on the effectiveness of Pretext-GRPO, we further propose the ViSS-R1 framework, which streamlines and integrates pretext-task-based self-supervised learning directly into the MLLM's R1 post-training paradigm. Instead of relying solely on sparse visual cues, our framework compels models to reason about transformed visual input by simultaneously processing both pretext questions (concerning transformations) and true user queries. This necessitates identifying the applied transformation and reconstructing the original video to formulate accurate final answers. Comprehensive evaluations on six widely-used video reasoning and understanding benchmarks demonstrate the effectiveness and superiority of our Pretext-GRPO and ViSS-R1 for complex video reasoning. Our codes and models will be publicly available.
Query-Kontext: An Unified Multimodal Model for Image Generation and Editing
Sep 30, 2025
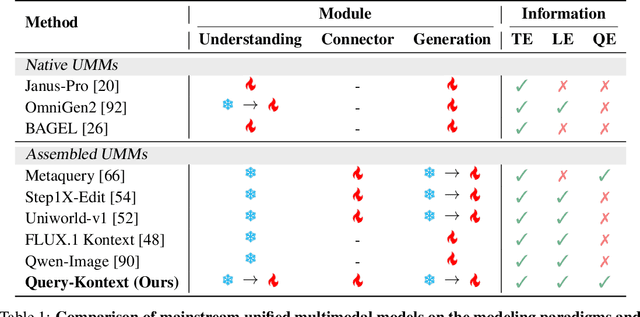
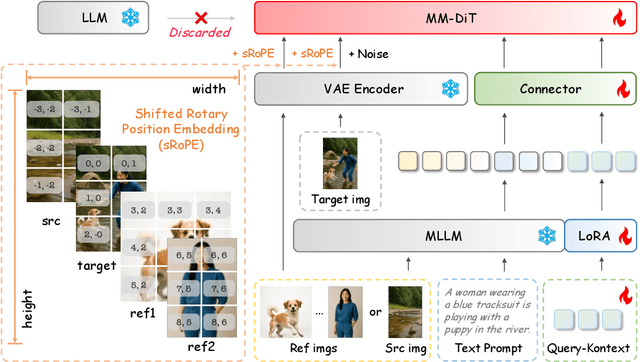
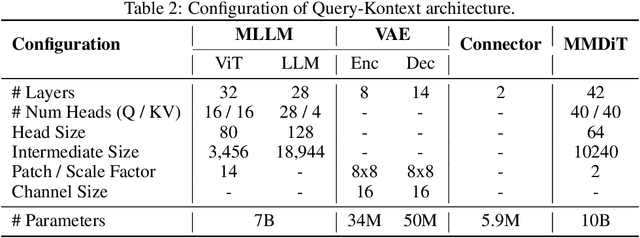
Unified Multimodal Models (UMMs) have demonstrated remarkable performance in text-to-image generation (T2I) and editing (TI2I), whether instantiated as assembled unified frameworks which couple powerful vision-language model (VLM) with diffusion-based generator, or as naive Unified Multimodal Models with an early fusion of understanding and generation modalities. We contend that in current unified frameworks, the crucial capability of multimodal generative reasoning which encompasses instruction understanding, grounding, and image referring for identity preservation and faithful reconstruction, is intrinsically entangled with high-fidelity synthesis. In this work, we introduce Query-Kontext, a novel approach that bridges the VLM and diffusion model via a multimodal ``kontext'' composed of semantic cues and coarse-grained image conditions encoded from multimodal inputs. This design delegates the complex ability of multimodal generative reasoning to powerful VLM while reserving diffusion model's role for high-quality visual synthesis. To achieve this, we propose a three-stage progressive training strategy. First, we connect the VLM to a lightweight diffusion head via multimodal kontext tokens to unleash the VLM's generative reasoning ability. Second, we scale this head to a large, pre-trained diffusion model to enhance visual detail and realism. Finally, we introduce a low-level image encoder to improve image fidelity and perform instruction tuning on downstream tasks. Furthermore, we build a comprehensive data pipeline integrating real, synthetic, and open-source datasets, covering diverse multimodal reference-to-image scenarios, including image generation, instruction-driven editing, customized generation, and multi-subject composition. Experiments show that our approach matches strong unified baselines and even outperforms task-specific state-of-the-art methods in several cases.
Threading Keyframe with Narratives: MLLMs as Strong Long Video Comprehenders
May 30, 2025Employing Multimodal Large Language Models (MLLMs) for long video understanding remains a challenging problem due to the dilemma between the substantial number of video frames (i.e., visual tokens) versus the limited context length of language models. Traditional uniform sampling often leads to selection of irrelevant content, while post-training MLLMs on thousands of frames imposes a substantial computational burden. In this paper, we propose threading keyframes with narratives (Nar-KFC), a plug-and-play module to facilitate effective and efficient long video perception. Nar-KFC generally involves two collaborative steps. First, we formulate the keyframe selection process as an integer quadratic programming problem, jointly optimizing query-relevance and frame-diversity. To avoid its computational complexity, a customized greedy search strategy is designed as an efficient alternative. Second, to mitigate the temporal discontinuity caused by sparse keyframe sampling, we further introduce interleaved textual narratives generated from non-keyframes using off-the-shelf captioners. These narratives are inserted between keyframes based on their true temporal order, forming a coherent and compact representation. Nar-KFC thus serves as a temporal- and content-aware compression strategy that complements visual and textual modalities. Experimental results on multiple long-video benchmarks demonstrate that Nar-KFC significantly improves the performance of popular MLLMs. Code will be made publicly available.
Explanatory Instructions: Towards Unified Vision Tasks Understanding and Zero-shot Generalization
Dec 25, 2024


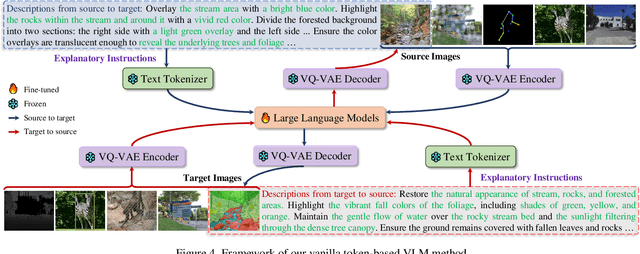
Computer Vision (CV) has yet to fully achieve the zero-shot task generalization observed in Natural Language Processing (NLP), despite following many of the milestones established in NLP, such as large transformer models, extensive pre-training, and the auto-regression paradigm, among others. In this paper, we explore the idea that CV adopts discrete and terminological task definitions (\eg, ``image segmentation''), which may be a key barrier to zero-shot task generalization. Our hypothesis is that without truly understanding previously-seen tasks--due to these terminological definitions--deep models struggle to generalize to novel tasks. To verify this, we introduce Explanatory Instructions, which provide an intuitive way to define CV task objectives through detailed linguistic transformations from input images to outputs. We create a large-scale dataset comprising 12 million ``image input $\to$ explanatory instruction $\to$ output'' triplets, and train an auto-regressive-based vision-language model (AR-based VLM) that takes both images and explanatory instructions as input. By learning to follow these instructions, the AR-based VLM achieves instruction-level zero-shot capabilities for previously-seen tasks and demonstrates strong zero-shot generalization for unseen CV tasks. Code and dataset will be openly available on our GitHub repository.
The Key of Understanding Vision Tasks: Explanatory Instructions
Dec 24, 2024Computer Vision (CV) has yet to fully achieve the zero-shot task generalization observed in Natural Language Processing (NLP), despite following many of the milestones established in NLP, such as large transformer models, extensive pre-training, and the auto-regression paradigm, among others. In this paper, we explore the idea that CV adopts discrete and terminological task definitions (\eg, ``image segmentation''), which may be a key barrier to zero-shot task generalization. Our hypothesis is that without truly understanding previously-seen tasks--due to these terminological definitions--deep models struggle to generalize to novel tasks. To verify this, we introduce Explanatory Instructions, which provide an intuitive way to define CV task objectives through detailed linguistic transformations from input images to outputs. We create a large-scale dataset comprising 12 million ``image input $\to$ explanatory instruction $\to$ output'' triplets, and train an auto-regressive-based vision-language model (AR-based VLM) that takes both images and explanatory instructions as input. By learning to follow these instructions, the AR-based VLM achieves instruction-level zero-shot capabilities for previously-seen tasks and demonstrates strong zero-shot generalization for unseen CV tasks. Code and dataset will be openly available on our GitHub repository.
Mulberry: Empowering MLLM with o1-like Reasoning and Reflection via Collective Monte Carlo Tree Search
Dec 24, 2024



In this work, we aim to develop an MLLM that understands and solves questions by learning to create each intermediate step of the reasoning involved till the final answer. To this end, we propose Collective Monte Carlo Tree Search (CoMCTS), a new learning-to-reason method for MLLMs, which introduces the concept of collective learning into ``tree search'' for effective and efficient reasoning-path searching and learning. The core idea of CoMCTS is to leverage collective knowledge from multiple models to collaboratively conjecture, search and identify effective reasoning paths toward correct answers via four iterative operations including Expansion, Simulation and Error Positioning, Backpropagation, and Selection. Using CoMCTS, we construct Mulberry-260k, a multimodal dataset with a tree of rich, explicit and well-defined reasoning nodes for each question. With Mulberry-260k, we perform collective SFT to train our model, Mulberry, a series of MLLMs with o1-like step-by-step Reasoning and Reflection capabilities. Extensive experiments demonstrate the superiority of our proposed methods on various benchmarks. Code will be available at https://github.com/HJYao00/Mulberry
DistinctAD: Distinctive Audio Description Generation in Contexts
Nov 27, 2024



Audio Descriptions (ADs) aim to provide a narration of a movie in text form, describing non-dialogue-related narratives, such as characters, actions, or scene establishment. Automatic generation of ADs remains challenging due to: i) the domain gap between movie-AD data and existing data used to train vision-language models, and ii) the issue of contextual redundancy arising from highly similar neighboring visual clips in a long movie. In this work, we propose DistinctAD, a novel two-stage framework for generating ADs that emphasize distinctiveness to produce better narratives. To address the domain gap, we introduce a CLIP-AD adaptation strategy that does not require additional AD corpora, enabling more effective alignment between movie and AD modalities at both global and fine-grained levels. In Stage-II, DistinctAD incorporates two key innovations: (i) a Contextual Expectation-Maximization Attention (EMA) module that reduces redundancy by extracting common bases from consecutive video clips, and (ii) an explicit distinctive word prediction loss that filters out repeated words in the context, ensuring the prediction of unique terms specific to the current AD. Comprehensive evaluations on MAD-Eval, CMD-AD, and TV-AD benchmarks demonstrate the superiority of DistinctAD, with the model consistently outperforming baselines, particularly in Recall@k/N, highlighting its effectiveness in producing high-quality, distinctive ADs.
A Survey on Consumer IoT Traffic: Security and Privacy
Mar 24, 2024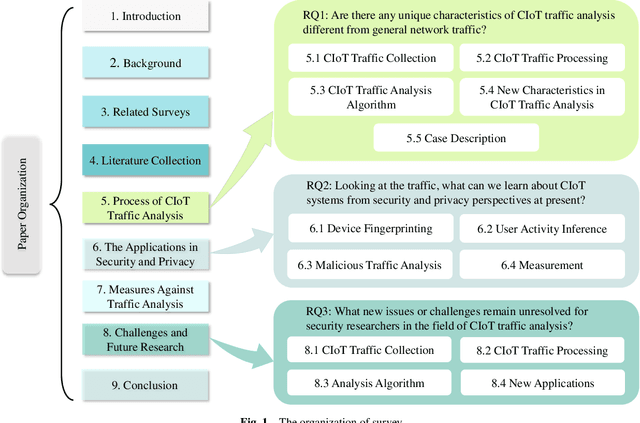
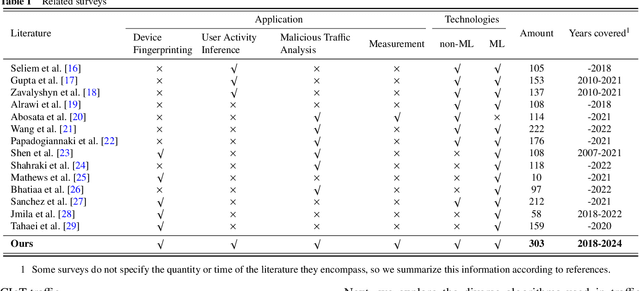
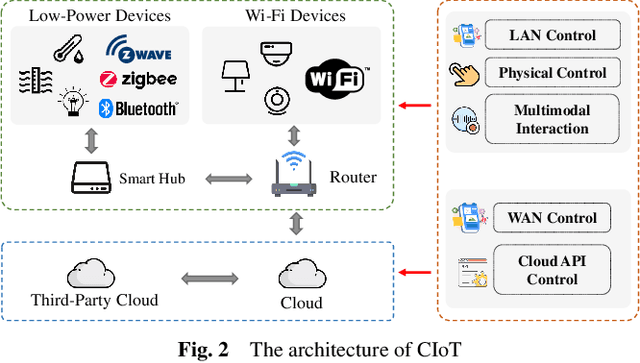

For the past few years, the Consumer Internet of Things (CIoT) has entered public lives. While CIoT has improved the convenience of people's daily lives, it has also brought new security and privacy concerns. In this survey, we try to figure out what researchers can learn about the security and privacy of CIoT by traffic analysis, a popular method in the security community. From the security and privacy perspective, this survey seeks out the new characteristics in CIoT traffic analysis, the state-of-the-art progress in CIoT traffic analysis, and the challenges yet to be solved. We collected 310 papers from January 2018 to December 2023 related to CIoT traffic analysis from the security and privacy perspective and summarized the process of CIoT traffic analysis in which the new characteristics of CIoT are identified. Then, we detail existing works based on five application goals: device fingerprinting, user activity inference, malicious traffic analysis, security analysis, and measurement. At last, we discuss the new challenges and future research directions.
Multi-level graph learning for audio event classification and human-perceived annoyance rating prediction
Dec 15, 2023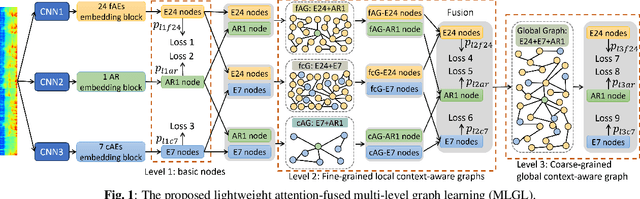
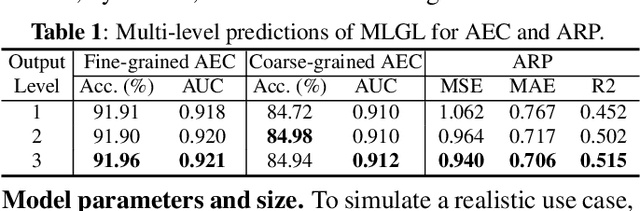
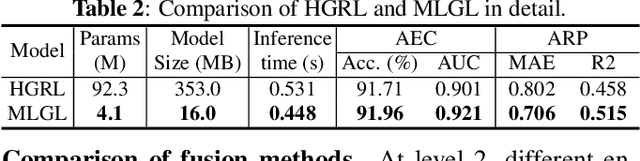
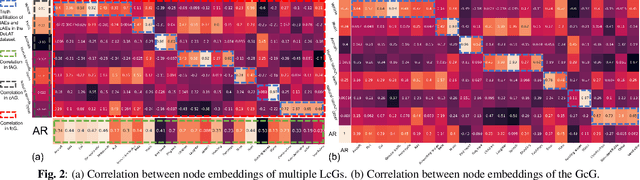
WHO's report on environmental noise estimates that 22 M people suffer from chronic annoyance related to noise caused by audio events (AEs) from various sources. Annoyance may lead to health issues and adverse effects on metabolic and cognitive systems. In cities, monitoring noise levels does not provide insights into noticeable AEs, let alone their relations to annoyance. To create annoyance-related monitoring, this paper proposes a graph-based model to identify AEs in a soundscape, and explore relations between diverse AEs and human-perceived annoyance rating (AR). Specifically, this paper proposes a lightweight multi-level graph learning (MLGL) based on local and global semantic graphs to simultaneously perform audio event classification (AEC) and human annoyance rating prediction (ARP). Experiments show that: 1) MLGL with 4.1 M parameters improves AEC and ARP results by using semantic node information in local and global context aware graphs; 2) MLGL captures relations between coarse and fine-grained AEs and AR well; 3) Statistical analysis of MLGL results shows that some AEs from different sources significantly correlate with AR, which is consistent with previous research on human perception of these sound sources.