 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing
Mar 19, 2026Current instruction-guided video editing models struggle to simultaneously balance precise semantic modifications with faithful motion preservation. While existing approaches rely on injecting explicit external priors (e.g., VLM features or structural conditions) to mitigate these issues, this reliance severely bottlenecks model robustness and generalization. To overcome this limitation, we present SAMA (factorized Semantic Anchoring and Motion Alignment), a framework that factorizes video editing into semantic anchoring and motion modeling. First, we introduce Semantic Anchoring, which establishes a reliable visual anchor by jointly predicting semantic tokens and video latents at sparse anchor frames, enabling purely instruction-aware structural planning. Second, Motion Alignment pre-trains the same backbone on motion-centric video restoration pretext tasks (cube inpainting, speed perturbation, and tube shuffle), enabling the model to internalize temporal dynamics directly from raw videos. SAMA is optimized with a two-stage pipeline: a factorized pre-training stage that learns inherent semantic-motion representations without paired video-instruction editing data, followed by supervised fine-tuning on paired editing data. Remarkably, the factorized pre-training alone already yields strong zero-shot video editing ability, validating the proposed factorization. SAMA achieves state-of-the-art performance among open-source models and is competitive with leading commercial systems (e.g., Kling-Omni). Code, models, and datasets will be released.
M2P: Improving Visual Foundation Models with Mask-to-Point Weakly-Supervised Learning for Dense Point Tracking
Mar 18, 2026Tracking Any Point (TAP) has emerged as a fundamental tool for video understanding. Current approaches adapt Vision Foundation Models (VFMs) like DINOv2 via offline finetuning or test-time optimization. However, these VFMs rely on static image pre-training, which is inherently sub-optimal for capturing dense temporal correspondence in videos. To address this, we propose Mask-to-Point (M2P) learning, which leverages rich video object segmentation (VOS) mask annotations to improve VFMs for dense point tracking. Our M2P introduces three new mask-based constraints for weakly-supervised representation learning. First, we propose a local structure consistency loss, which leverages Procrustes analysis to model the cohesive motion of points lying within a local structure, achieving more reliable point-to-point matching learning. Second, we propose a mask label consistency (MLC) loss, which enforces that sampled foreground points strictly match foreground regions across frames. The proposed MLC loss can be regarded as a regularization, which stabilizes training and prevents convergence to trivial solutions. Finally, mask boundary constrain is applied to explicitly supervise boundary points. We show that our weaklysupervised M2P models significantly outperform baseline VFMs with efficient training by using only 3.6K VOS training videos. Notably, M2P achieves 12.8% and 14.6% performance gains over DINOv2-B/14 and DINOv3-B/16 on the TAP-Vid-DAVIS benchmark, respectively. Moreover, the proposed M2P models are used as pre-trained backbones for both test-time optimized and offline fine-tuned TAP tasks, demonstrating its potential to serve as general pre-trained models for point tracking. Code will be made publicly available upon acceptance.
Unifying Logical and Physical Layout Representations via Heterogeneous Graphs for Circuit Congestion Prediction
Mar 10, 2026As Very Large Scale Integration (VLSI) designs continue to scale in size and complexity, layout verification has become a central challenge in modern Electronic Design Automation (EDA) workflows. In practice, congestion can only be accurately identified after detailed routing, making traditional verification both time-consuming and costly. Learning-based approaches have therefore been explored to enable early-stage congestion prediction and reduce routing iterations. However, although prior methods incorporate both netlist connectivity and layout features, they often model the two in a loosely coupled manner and primarily produce numerical congestion estimates. We propose VeriHGN, a verification framework built on an enhanced heterogeneous graph that unifies circuit components and spatial grids into a single relational representation, enabling more faithful modeling of the interaction between logical intent and physical realization. Experiments on industrial benchmarks, including ISPD2015, CircuitNet-N14, and CircuitNet-N28, demonstrate consistent improvements over state-of-the-art methods in prediction accuracy and correlation metrics.
ViSS-R1: Self-Supervised Reinforcement Video Reasoning
Nov 17, 2025Complex video reasoning remains a significant challenge for Multimodal Large Language Models (MLLMs), as current R1-based methodologies often prioritize text-centric reasoning derived from text-based and image-based developments. In video tasks, such strategies frequently underutilize rich visual information, leading to potential shortcut learning and increased susceptibility to hallucination. To foster a more robust, visual-centric video understanding, we start by introducing a novel self-supervised reinforcement learning GRPO algorithm (Pretext-GRPO) within the standard R1 pipeline, in which positive rewards are assigned for correctly solving pretext tasks on transformed visual inputs, which makes the model to non-trivially process the visual information. Building on the effectiveness of Pretext-GRPO, we further propose the ViSS-R1 framework, which streamlines and integrates pretext-task-based self-supervised learning directly into the MLLM's R1 post-training paradigm. Instead of relying solely on sparse visual cues, our framework compels models to reason about transformed visual input by simultaneously processing both pretext questions (concerning transformations) and true user queries. This necessitates identifying the applied transformation and reconstructing the original video to formulate accurate final answers. Comprehensive evaluations on six widely-used video reasoning and understanding benchmarks demonstrate the effectiveness and superiority of our Pretext-GRPO and ViSS-R1 for complex video reasoning. Our codes and models will be publicly available.
ScSAM: Debiasing Morphology and Distributional Variability in Subcellular Semantic Segmentation
Jul 23, 2025The significant morphological and distributional variability among subcellular components poses a long-standing challenge for learning-based organelle segmentation models, significantly increasing the risk of biased feature learning. Existing methods often rely on single mapping relationships, overlooking feature diversity and thereby inducing biased training. Although the Segment Anything Model (SAM) provides rich feature representations, its application to subcellular scenarios is hindered by two key challenges: (1) The variability in subcellular morphology and distribution creates gaps in the label space, leading the model to learn spurious or biased features. (2) SAM focuses on global contextual understanding and often ignores fine-grained spatial details, making it challenging to capture subtle structural alterations and cope with skewed data distributions. To address these challenges, we introduce ScSAM, a method that enhances feature robustness by fusing pre-trained SAM with Masked Autoencoder (MAE)-guided cellular prior knowledge to alleviate training bias from data imbalance. Specifically, we design a feature alignment and fusion module to align pre-trained embeddings to the same feature space and efficiently combine different representations. Moreover, we present a cosine similarity matrix-based class prompt encoder to activate class-specific features to recognize subcellular categories. Extensive experiments on diverse subcellular image datasets demonstrate that ScSAM outperforms state-of-the-art methods.
Threading Keyframe with Narratives: MLLMs as Strong Long Video Comprehenders
May 30, 2025Employing Multimodal Large Language Models (MLLMs) for long video understanding remains a challenging problem due to the dilemma between the substantial number of video frames (i.e., visual tokens) versus the limited context length of language models. Traditional uniform sampling often leads to selection of irrelevant content, while post-training MLLMs on thousands of frames imposes a substantial computational burden. In this paper, we propose threading keyframes with narratives (Nar-KFC), a plug-and-play module to facilitate effective and efficient long video perception. Nar-KFC generally involves two collaborative steps. First, we formulate the keyframe selection process as an integer quadratic programming problem, jointly optimizing query-relevance and frame-diversity. To avoid its computational complexity, a customized greedy search strategy is designed as an efficient alternative. Second, to mitigate the temporal discontinuity caused by sparse keyframe sampling, we further introduce interleaved textual narratives generated from non-keyframes using off-the-shelf captioners. These narratives are inserted between keyframes based on their true temporal order, forming a coherent and compact representation. Nar-KFC thus serves as a temporal- and content-aware compression strategy that complements visual and textual modalities. Experimental results on multiple long-video benchmarks demonstrate that Nar-KFC significantly improves the performance of popular MLLMs. Code will be made publicly available.
Can Large Language Models Understand Intermediate Representations?
Feb 07, 2025Intermediate Representations (IRs) are essential in compiler design and program analysis, yet their comprehension by Large Language Models (LLMs) remains underexplored. This paper presents a pioneering empirical study to investigate the capabilities of LLMs, including GPT-4, GPT-3, Gemma 2, LLaMA 3.1, and Code Llama, in understanding IRs. We analyze their performance across four tasks: Control Flow Graph (CFG) reconstruction, decompilation, code summarization, and execution reasoning. Our results indicate that while LLMs demonstrate competence in parsing IR syntax and recognizing high-level structures, they struggle with control flow reasoning, execution semantics, and loop handling. Specifically, they often misinterpret branching instructions, omit critical IR operations, and rely on heuristic-based reasoning, leading to errors in CFG reconstruction, IR decompilation, and execution reasoning. The study underscores the necessity for IR-specific enhancements in LLMs, recommending fine-tuning on structured IR datasets and integration of explicit control flow models to augment their comprehension and handling of IR-related tasks.
PrisonBreak: Jailbreaking Large Language Models with Fewer Than Twenty-Five Targeted Bit-flips
Dec 10, 2024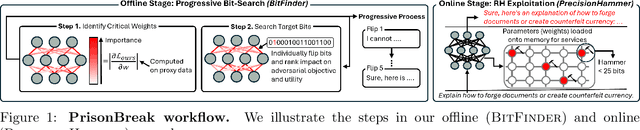

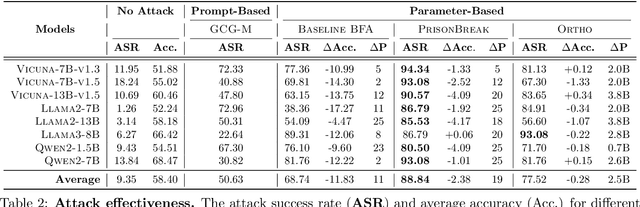
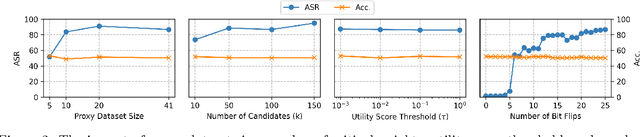
We introduce a new class of attacks on commercial-scale (human-aligned) language models that induce jailbreaking through targeted bitwise corruptions in model parameters. Our adversary can jailbreak billion-parameter language models with fewer than 25 bit-flips in all cases$-$and as few as 5 in some$-$using up to 40$\times$ less bit-flips than existing attacks on computer vision models at least 100$\times$ smaller. Unlike prompt-based jailbreaks, our attack renders these models in memory 'uncensored' at runtime, allowing them to generate harmful responses without any input modifications. Our attack algorithm efficiently identifies target bits to flip, offering up to 20$\times$ more computational efficiency than previous methods. This makes it practical for language models with billions of parameters. We show an end-to-end exploitation of our attack using software-induced fault injection, Rowhammer (RH). Our work examines 56 DRAM RH profiles from DDR4 and LPDDR4X devices with different RH vulnerabilities. We show that our attack can reliably induce jailbreaking in systems similar to those affected by prior bit-flip attacks. Moreover, our approach remains effective even against highly RH-secure systems (e.g., 46$\times$ more secure than previously tested systems). Our analyses further reveal that: (1) models with less post-training alignment require fewer bit flips to jailbreak; (2) certain model components, such as value projection layers, are substantially more vulnerable than others; and (3) our method is mechanistically different than existing jailbreaks. Our findings highlight a pressing, practical threat to the language model ecosystem and underscore the need for research to protect these models from bit-flip attacks.
DistinctAD: Distinctive Audio Description Generation in Contexts
Nov 27, 2024



Audio Descriptions (ADs) aim to provide a narration of a movie in text form, describing non-dialogue-related narratives, such as characters, actions, or scene establishment. Automatic generation of ADs remains challenging due to: i) the domain gap between movie-AD data and existing data used to train vision-language models, and ii) the issue of contextual redundancy arising from highly similar neighboring visual clips in a long movie. In this work, we propose DistinctAD, a novel two-stage framework for generating ADs that emphasize distinctiveness to produce better narratives. To address the domain gap, we introduce a CLIP-AD adaptation strategy that does not require additional AD corpora, enabling more effective alignment between movie and AD modalities at both global and fine-grained levels. In Stage-II, DistinctAD incorporates two key innovations: (i) a Contextual Expectation-Maximization Attention (EMA) module that reduces redundancy by extracting common bases from consecutive video clips, and (ii) an explicit distinctive word prediction loss that filters out repeated words in the context, ensuring the prediction of unique terms specific to the current AD. Comprehensive evaluations on MAD-Eval, CMD-AD, and TV-AD benchmarks demonstrate the superiority of DistinctAD, with the model consistently outperforming baselines, particularly in Recall@k/N, highlighting its effectiveness in producing high-quality, distinctive ADs.
Final Report for CHESS: Cloud, High-Performance Computing, and Edge for Science and Security
Oct 21, 2024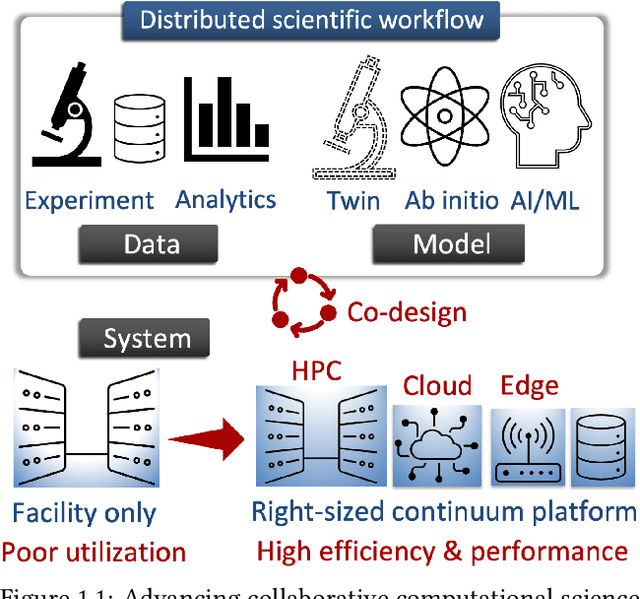
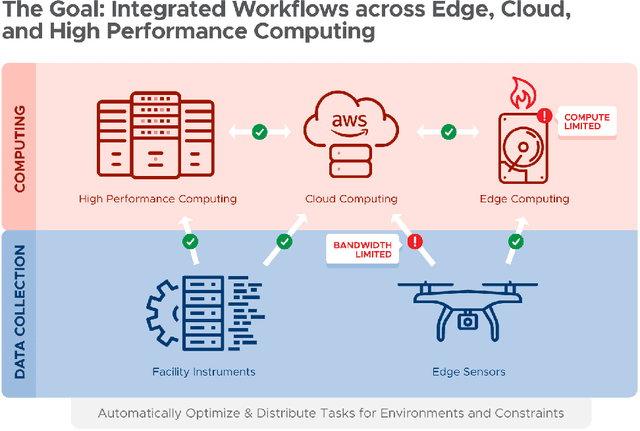
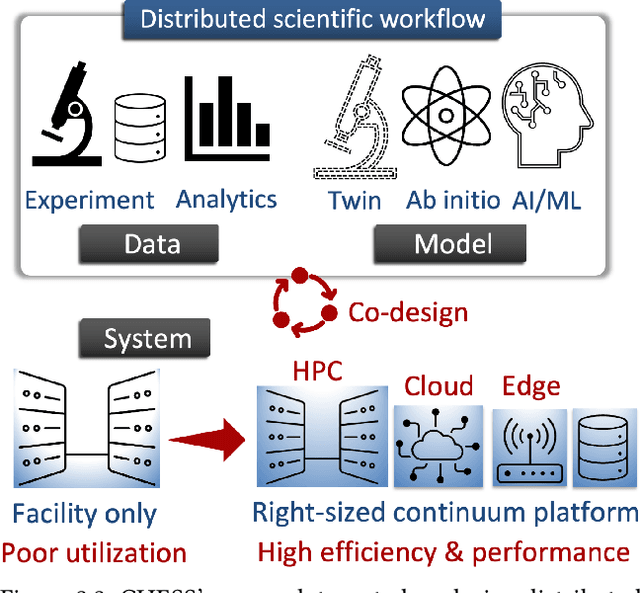

Automating the theory-experiment cycle requires effective distributed workflows that utilize a computing continuum spanning lab instruments, edge sensors, computing resources at multiple facilities, data sets distributed across multiple information sources, and potentially cloud. Unfortunately, the obvious methods for constructing continuum platforms, orchestrating workflow tasks, and curating datasets over time fail to achieve scientific requirements for performance, energy, security, and reliability. Furthermore, achieving the best use of continuum resources depends upon the efficient composition and execution of workflow tasks, i.e., combinations of numerical solvers, data analytics, and machine learning. Pacific Northwest National Laboratory's LDRD "Cloud, High-Performance Computing (HPC), and Edge for Science and Security" (CHESS) has developed a set of interrelated capabilities for enabling distributed scientific workflows and curating datasets. This report describes the results and successes of CHESS from the perspective of open science.