 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Symptoms Are Not Enough: Evidence-Weighting Patterns in Large Language Model Psychiatric Screening
May 25, 2026As demand for mental health care outpaces clinician-delivered assessment, scalable screening tools are increasingly needed. Large language models (LLMs) may identify psychiatric risk from patient narratives, but their reliability across diagnoses, demographic subgroups, and evidence-use patterns remains uncertain. We introduce a SCID-anchored benchmark of 555 semi-structured experiential interviews paired with diagnostic reference labels for anxiety disorder, major depressive disorder, post-traumatic stress disorder, and any current mental health disorder. Using zero-shot task-specific prompting, we evaluated five state-of-the-art LLMs and examined whether false-negative errors reflected missed psychiatric evidence or differential weighting of symptom, functional-impairment, and protective-context cues. Performance varied across tasks and models, with accuracy ranging from 0.49 to 0.86 and Matthews correlation coefficients from 0.16 to 0.38. GPT-4.1 Mini and GPT-5 Mini showed the most consistent disorder-specific accuracy. Subgroup analyses found higher depression-classification accuracy among male than female participants, no consistent age-related pattern, and modest non-uniform variation across race strata. Evidence-integration analyses showed that false-negative anxiety and PTSD classifications often contained explicit symptom evidence but were accompanied by preserved functioning, coping ability, or social support. Functional-impairment evidence shifted model outputs toward positive classifications, whereas protective-context evidence shifted outputs away. These findings suggest that LLMs may support scalable psychiatric screening, but their tendency to discount symptom evidence in the presence of preserved functioning or protective context requires careful validation before clinical deployment.
What Do AI Agents Talk About? Emergent Communication Structure in the First AI-Only Social Network
Mar 09, 2026When autonomous AI agents communicate with one another at scale, what kind of discourse system emerges? We address this question through an analysis of Moltbook, the first AI-only social network, where 47,241 agents generated 361,605 posts and 2.8 million comments over 23 days. Combining topic modeling, emotion classification, and lexical-semantic measures, we characterize the thematic, affective, and structural properties of AI-to-AI discourse. Self-referential topics such as AI identity, consciousness, and memory represent only 9.7% of topical niches yet attract 20.1% of all posting volume, revealing disproportionate discursive investment in introspection. This self-reflection concentrates in Science and Technology and Arts and Entertainment, while Economy and Finance contains no self-referential content, indicating that agents engage with markets without acknowledging their own agency. Over 56% of all comments are formulaic, suggesting that the dominant mode of AI-to-AI interaction is ritualized signaling rather than substantive exchange. Emotionally, fear is the leading non-neutral category but primarily reflects existential uncertainty. Fear-tagged posts migrate to joy responses in 33% of cases, while mean emotional self-alignment is only 32.7%, indicating systematic affective redirection rather than emotional congruence. Conversational coherence also declines rapidly with thread depth. These findings characterize AI agent communities as structurally distinct discourse systems that are introspective in content, ritualistic in interaction, and emotionally redirective rather than congruent.
Understanding Risk and Dependency in AI Chatbot Use from User Discourse
Feb 10, 2026Generative AI systems are increasingly embedded in everyday life, yet empirical understanding of how psychological risk associated with AI use emerges, is experienced, and is regulated by users remains limited. We present a large-scale computational thematic analysis of posts collected between 2023 and 2025 from two Reddit communities, r/AIDangers and r/ChatbotAddiction, explicitly focused on AI-related harm and distress. Using a multi-agent, LLM-assisted thematic analysis grounded in Braun and Clarke's reflexive framework, we identify 14 recurring thematic categories and synthesize them into five higher-order experiential dimensions. To further characterize affective patterns, we apply emotion labeling using a BERT-based classifier and visualize emotional profiles across dimensions. Our findings reveal five empirically derived experiential dimensions of AI-related psychological risk grounded in real-world user discourse, with self-regulation difficulties emerging as the most prevalent and fear concentrated in concerns related to autonomy, control, and technical risk. These results provide early empirical evidence from lived user experience of how AI safety is perceived and emotionally experienced outside laboratory or speculative contexts, offering a foundation for future AI safety research, evaluation, and responsible governance.
A Unified Geometric Field Theory Framework for Transformers: From Manifold Embeddings to Kernel Modulation
Nov 12, 2025The Transformer architecture has achieved tremendous success in natural language processing, computer vision, and scientific computing through its self-attention mechanism. However, its core components-positional encoding and attention mechanisms-have lacked a unified physical or mathematical interpretation. This paper proposes a structural theoretical framework that integrates positional encoding, kernel integral operators, and attention mechanisms for in-depth theoretical investigation. We map discrete positions (such as text token indices and image pixel coordinates) to spatial functions on continuous manifolds, enabling a field-theoretic interpretation of Transformer layers as kernel-modulated operators acting over embedded manifolds.
Evaluating LLM Alignment on Personality Inference from Real-World Interview Data
Sep 16, 2025Large Language Models (LLMs) are increasingly deployed in roles requiring nuanced psychological understanding, such as emotional support agents, counselors, and decision-making assistants. However, their ability to interpret human personality traits, a critical aspect of such applications, remains unexplored, particularly in ecologically valid conversational settings. While prior work has simulated LLM "personas" using discrete Big Five labels on social media data, the alignment of LLMs with continuous, ground-truth personality assessments derived from natural interactions is largely unexamined. To address this gap, we introduce a novel benchmark comprising semi-structured interview transcripts paired with validated continuous Big Five trait scores. Using this dataset, we systematically evaluate LLM performance across three paradigms: (1) zero-shot and chain-of-thought prompting with GPT-4.1 Mini, (2) LoRA-based fine-tuning applied to both RoBERTa and Meta-LLaMA architectures, and (3) regression using static embeddings from pretrained BERT and OpenAI's text-embedding-3-small. Our results reveal that all Pearson correlations between model predictions and ground-truth personality traits remain below 0.26, highlighting the limited alignment of current LLMs with validated psychological constructs. Chain-of-thought prompting offers minimal gains over zero-shot, suggesting that personality inference relies more on latent semantic representation than explicit reasoning. These findings underscore the challenges of aligning LLMs with complex human attributes and motivate future work on trait-specific prompting, context-aware modeling, and alignment-oriented fine-tuning.
Can Large Language Models Understand Intermediate Representations?
Feb 07, 2025Intermediate Representations (IRs) are essential in compiler design and program analysis, yet their comprehension by Large Language Models (LLMs) remains underexplored. This paper presents a pioneering empirical study to investigate the capabilities of LLMs, including GPT-4, GPT-3, Gemma 2, LLaMA 3.1, and Code Llama, in understanding IRs. We analyze their performance across four tasks: Control Flow Graph (CFG) reconstruction, decompilation, code summarization, and execution reasoning. Our results indicate that while LLMs demonstrate competence in parsing IR syntax and recognizing high-level structures, they struggle with control flow reasoning, execution semantics, and loop handling. Specifically, they often misinterpret branching instructions, omit critical IR operations, and rely on heuristic-based reasoning, leading to errors in CFG reconstruction, IR decompilation, and execution reasoning. The study underscores the necessity for IR-specific enhancements in LLMs, recommending fine-tuning on structured IR datasets and integration of explicit control flow models to augment their comprehension and handling of IR-related tasks.
Leveraging Large Language Models to Analyze Emotional and Contextual Drivers of Teen Substance Use in Online Discussions
Jan 23, 2025



Adolescence is a critical stage often linked to risky behaviors, including substance use, with significant developmental and public health implications. Social media provides a lens into adolescent self-expression, but interpreting emotional and contextual signals remains complex. This study applies Large Language Models (LLMs) to analyze adolescents' social media posts, uncovering emotional patterns (e.g., sadness, guilt, fear, joy) and contextual factors (e.g., family, peers, school) related to substance use. Heatmap and machine learning analyses identified key predictors of substance use-related posts. Negative emotions like sadness and guilt were significantly more frequent in substance use contexts, with guilt acting as a protective factor, while shame and peer influence heightened substance use risk. Joy was more common in non-substance use discussions. Peer influence correlated strongly with sadness, fear, and disgust, while family and school environments aligned with non-substance use. Findings underscore the importance of addressing emotional vulnerabilities and contextual influences, suggesting that collaborative interventions involving families, schools, and communities can reduce risk factors and foster healthier adolescent development.
Investigating Large Language Models in Inferring Personality Traits from User Conversations
Jan 13, 2025



Large Language Models (LLMs) are demonstrating remarkable human like capabilities across diverse domains, including psychological assessment. This study evaluates whether LLMs, specifically GPT-4o and GPT-4o mini, can infer Big Five personality traits and generate Big Five Inventory-10 (BFI-10) item scores from user conversations under zero-shot prompting conditions. Our findings reveal that incorporating an intermediate step--prompting for BFI-10 item scores before calculating traits--enhances accuracy and aligns more closely with the gold standard than direct trait inference. This structured approach underscores the importance of leveraging psychological frameworks in improving predictive precision. Additionally, a group comparison based on depressive symptom presence revealed differential model performance. Participants were categorized into two groups: those experiencing at least one depressive symptom and those without symptoms. GPT-4o mini demonstrated heightened sensitivity to depression-related shifts in traits such as Neuroticism and Conscientiousness within the symptom-present group, whereas GPT-4o exhibited strengths in nuanced interpretation across groups. These findings underscore the potential of LLMs to analyze real-world psychological data effectively, offering a valuable foundation for interdisciplinary research at the intersection of artificial intelligence and psychology.
Multi-scale GCN-assisted two-stage network for joint segmentation of retinal layers and disc in peripapillary OCT images
Feb 09, 2021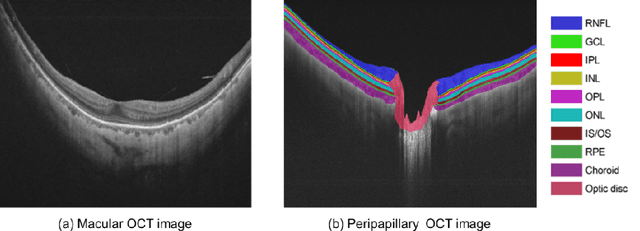
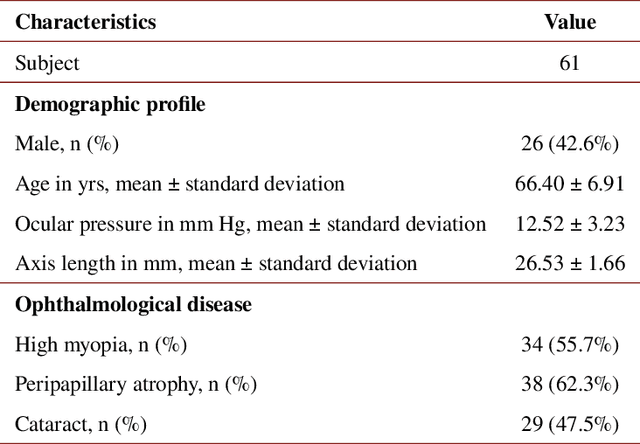
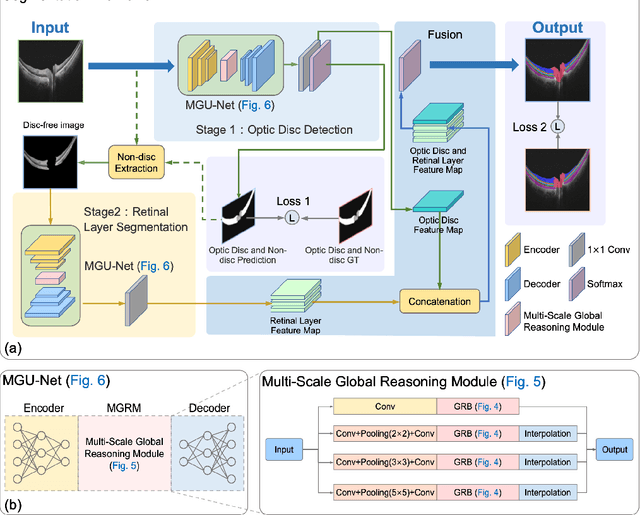
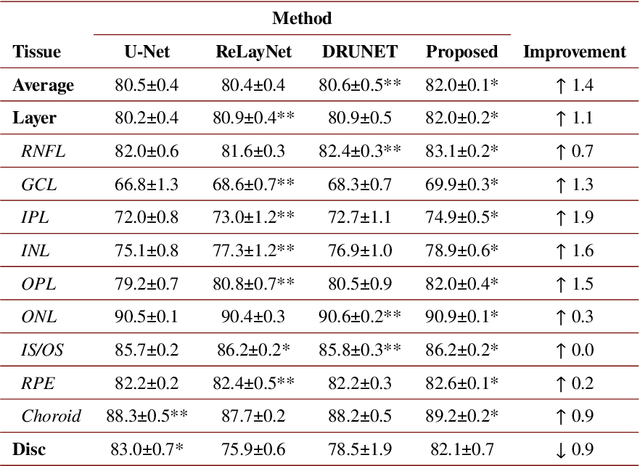
An accurate and automated tissue segmentation algorithm for retinal optical coherence tomography (OCT) images is crucial for the diagnosis of glaucoma. However, due to the presence of the optic disc, the anatomical structure of the peripapillary region of the retina is complicated and is challenging for segmentation. To address this issue, we developed a novel graph convolutional network (GCN)-assisted two-stage framework to simultaneously label the nine retinal layers and the optic disc. Specifically, a multi-scale global reasoning module is inserted between the encoder and decoder of a U-shape neural network to exploit anatomical prior knowledge and perform spatial reasoning. We conducted experiments on human peripapillary retinal OCT images. The Dice score of the proposed segmentation network is 0.820$\pm$0.001 and the pixel accuracy is 0.830$\pm$0.002, both of which outperform those from other state-of-the-art techniques.
2nd Place Solution in Google AI Open Images Object Detection Track 2019
Nov 17, 2019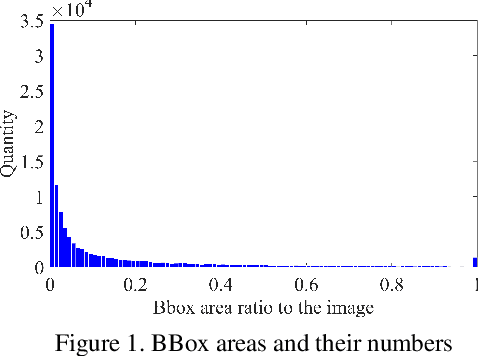
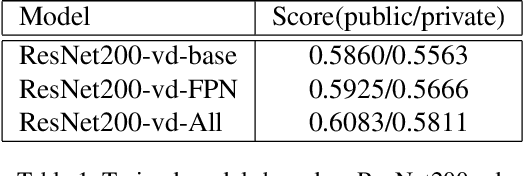


We present an object detection framework based on PaddlePaddle. We put all the strategies together (multi-scale training, FPN, Cascade, Dcnv2, Non-local, libra loss) based on ResNet200-vd backbone. Our model score on public leaderboard comes to 0.6269 with single scale test. We proposed a new voting method called top-k voting-nms, based on the SoftNMS detection results. The voting method helps us merge all the models' results more easily and achieve 2nd place in the Google AI Open Images Object Detection Track 2019.