 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePursuing Top Growth with Novel Loss Function
Feb 20, 2025



Making consistently profitable financial decisions in a continuously evolving and volatile stock market has always been a difficult task. Professionals from different disciplines have developed foundational theories to anticipate price movement and evaluate securities such as the famed Capital Asset Pricing Model (CAPM). In recent years, the role of artificial intelligence (AI) in asset pricing has been growing. Although the black-box nature of deep learning models lacks interpretability, they have continued to solidify their position in the financial industry. We aim to further enhance AI's potential and utility by introducing a return-weighted loss function that will drive top growth while providing the ML models a limited amount of information. Using only publicly accessible stock data (open/close/high/low, trading volume, sector information) and several technical indicators constructed from them, we propose an efficient daily trading system that detects top growth opportunities. Our best models achieve 61.73% annual return on daily rebalancing with an annualized Sharpe Ratio of 1.18 over 1340 testing days from 2019 to 2024, and 37.61% annual return with an annualized Sharpe Ratio of 0.97 over 1360 testing days from 2005 to 2010. The main drivers for success, especially independent of any domain knowledge, are the novel return-weighted loss function, the integration of categorical and continuous data, and the ML model architecture. We also demonstrate the superiority of our novel loss function over traditional loss functions via several performance metrics and statistical evidence.
PP-StructureV2: A Stronger Document Analysis System
Oct 11, 2022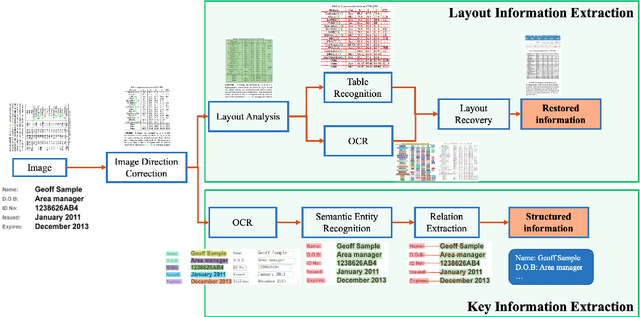



A large amount of document data exists in unstructured form such as raw images without any text information. Designing a practical document image analysis system is a meaningful but challenging task. In previous work, we proposed an intelligent document analysis system PP-Structure. In order to further upgrade the function and performance of PP-Structure, we propose PP-StructureV2 in this work, which contains two subsystems: Layout Information Extraction and Key Information Extraction. Firstly, we integrate Image Direction Correction module and Layout Restoration module to enhance the functionality of the system. Secondly, 8 practical strategies are utilized in PP-StructureV2 for better performance. For Layout Analysis model, we introduce ultra light-weight detector PP-PicoDet and knowledge distillation algorithm FGD for model lightweighting, which increased the inference speed by 11 times with comparable mAP. For Table Recognition model, we utilize PP-LCNet, CSP-PAN and SLAHead to optimize the backbone module, feature fusion module and decoding module, respectively, which improved the table structure accuracy by 6\% with comparable inference speed. For Key Information Extraction model, we introduce VI-LayoutXLM which is a visual-feature independent LayoutXLM architecture, TB-YX sorting algorithm and U-DML knowledge distillation algorithm, which brought 2.8\% and 9.1\% improvement respectively on the Hmean of Semantic Entity Recognition and Relation Extraction tasks. All the above mentioned models and code are open-sourced in the GitHub repository PaddleOCR.
PP-OCRv3: More Attempts for the Improvement of Ultra Lightweight OCR System
Jun 07, 2022

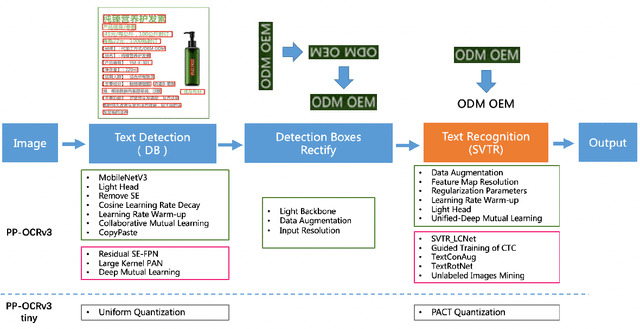
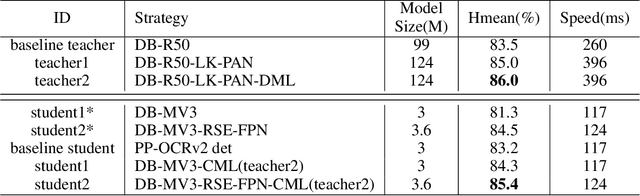
Optical character recognition (OCR) technology has been widely used in various scenes, as shown in Figure 1. Designing a practical OCR system is still a meaningful but challenging task. In previous work, considering the efficiency and accuracy, we proposed a practical ultra lightweight OCR system (PP-OCR), and an optimized version PP-OCRv2. In order to further improve the performance of PP-OCRv2, a more robust OCR system PP-OCRv3 is proposed in this paper. PP-OCRv3 upgrades the text detection model and text recognition model in 9 aspects based on PP-OCRv2. For text detector, we introduce a PAN module with large receptive field named LK-PAN, a FPN module with residual attention mechanism named RSE-FPN, and DML distillation strategy. For text recognizer, the base model is replaced from CRNN to SVTR, and we introduce lightweight text recognition network SVTR LCNet, guided training of CTC by attention, data augmentation strategy TextConAug, better pre-trained model by self-supervised TextRotNet, UDML, and UIM to accelerate the model and improve the effect. Experiments on real data show that the hmean of PP-OCRv3 is 5% higher than PP-OCRv2 under comparable inference speed. All the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleOCR which is powered by PaddlePaddle.
PP-ShiTu: A Practical Lightweight Image Recognition System
Nov 01, 2021
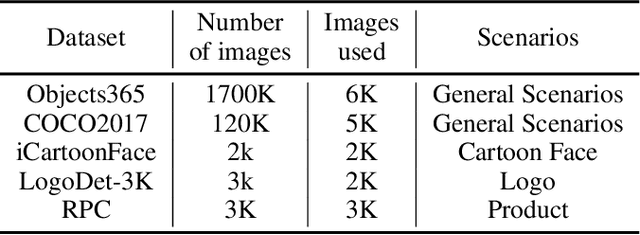
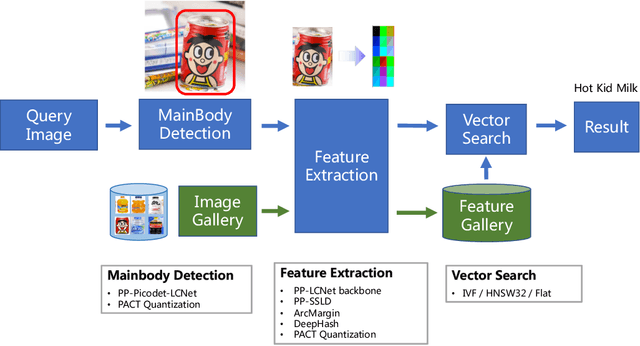
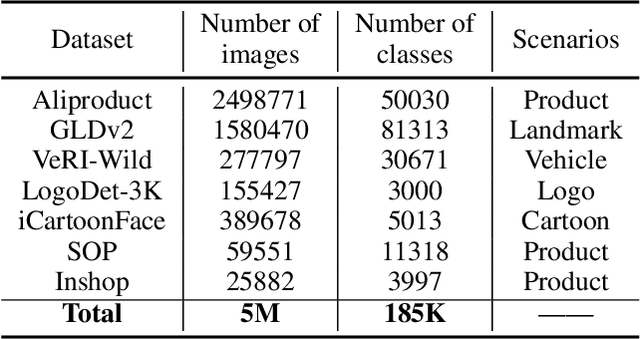
In recent years, image recognition applications have developed rapidly. A large number of studies and techniques have emerged in different fields, such as face recognition, pedestrian and vehicle re-identification, landmark retrieval, and product recognition. In this paper, we propose a practical lightweight image recognition system, named PP-ShiTu, consisting of the following 3 modules, mainbody detection, feature extraction and vector search. We introduce popular strategies including metric learning, deep hash, knowledge distillation and model quantization to improve accuracy and inference speed. With strategies above, PP-ShiTu works well in different scenarios with a set of models trained on a mixed dataset. Experiments on different datasets and benchmarks show that the system is widely effective in different domains of image recognition. All the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleClas on PaddlePaddle.
PP-LCNet: A Lightweight CPU Convolutional Neural Network
Sep 17, 2021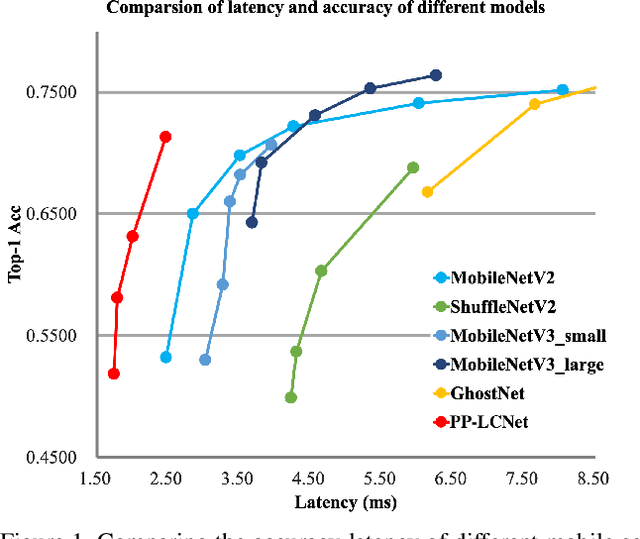
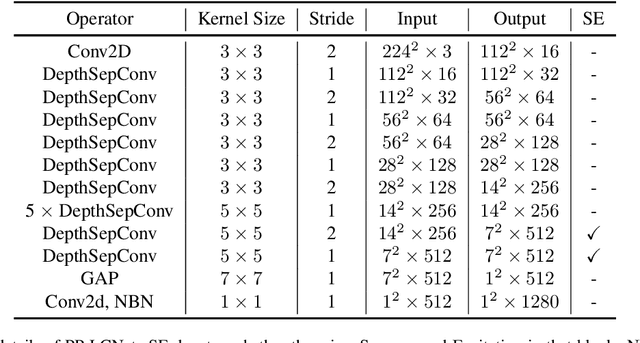
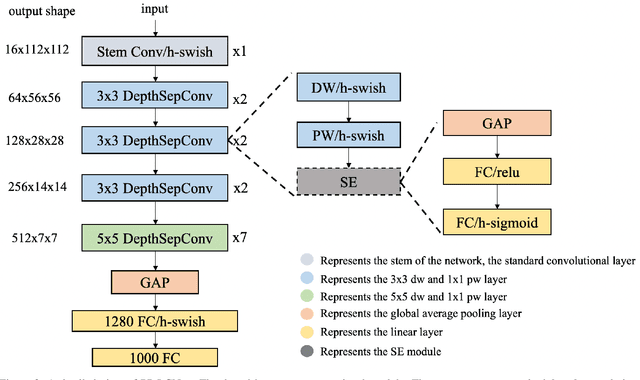
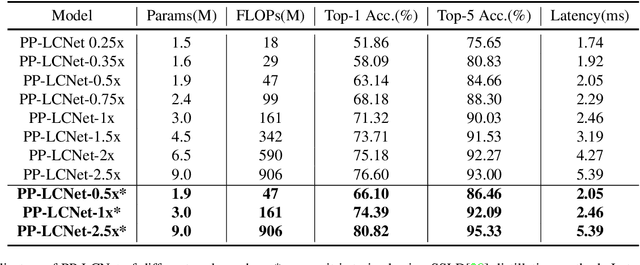
We propose a lightweight CPU network based on the MKLDNN acceleration strategy, named PP-LCNet, which improves the performance of lightweight models on multiple tasks. This paper lists technologies which can improve network accuracy while the latency is almost constant. With these improvements, the accuracy of PP-LCNet can greatly surpass the previous network structure with the same inference time for classification. As shown in Figure 1, it outperforms the most state-of-the-art models. And for downstream tasks of computer vision, it also performs very well, such as object detection, semantic segmentation, etc. All our experiments are implemented based on PaddlePaddle. Code and pretrained models are available at PaddleClas.
PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System
Sep 07, 2021

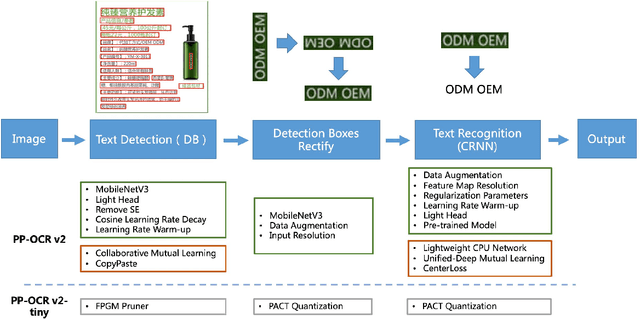
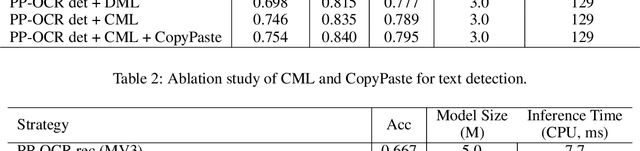
Optical Character Recognition (OCR) systems have been widely used in various of application scenarios. Designing an OCR system is still a challenging task. In previous work, we proposed a practical ultra lightweight OCR system (PP-OCR) to balance the accuracy against the efficiency. In order to improve the accuracy of PP-OCR and keep high efficiency, in this paper, we propose a more robust OCR system, i.e. PP-OCRv2. We introduce bag of tricks to train a better text detector and a better text recognizer, which include Collaborative Mutual Learning (CML), CopyPaste, Lightweight CPUNetwork (LCNet), Unified-Deep Mutual Learning (U-DML) and Enhanced CTCLoss. Experiments on real data show that the precision of PP-OCRv2 is 7% higher than PP-OCR under the same inference cost. It is also comparable to the server models of the PP-OCR which uses ResNet series as backbones. All of the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleOCR which is powered by PaddlePaddle.
Beyond Self-Supervision: A Simple Yet Effective Network Distillation Alternative to Improve Backbones
Mar 10, 2021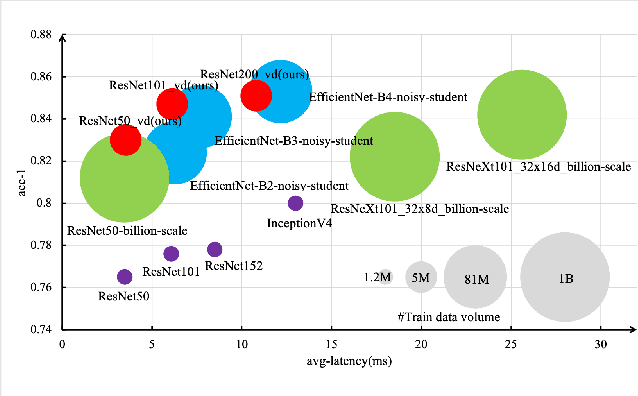
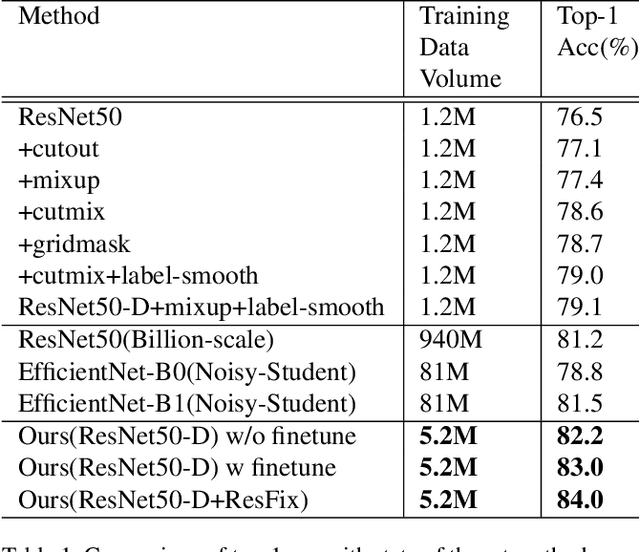
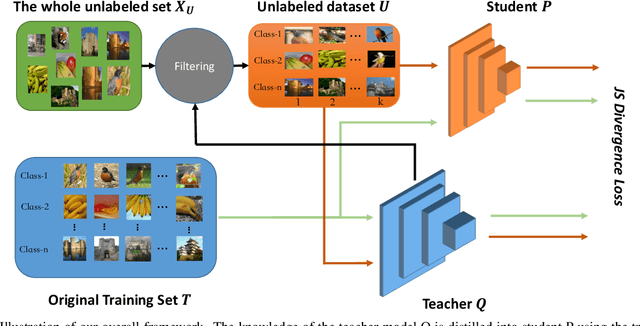
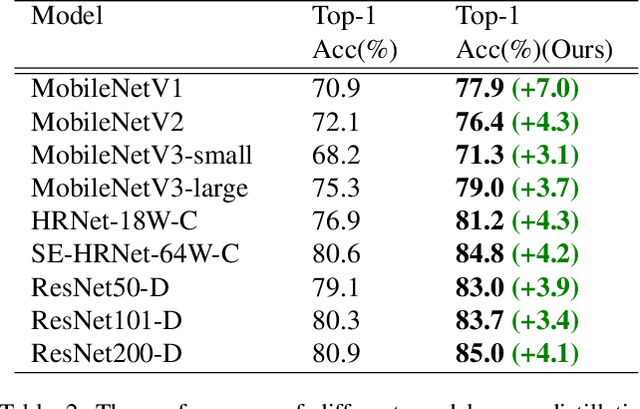
Recently, research efforts have been concentrated on revealing how pre-trained model makes a difference in neural network performance. Self-supervision and semi-supervised learning technologies have been extensively explored by the community and are proven to be of great potential in obtaining a powerful pre-trained model. However, these models require huge training costs (i.e., hundreds of millions of images or training iterations). In this paper, we propose to improve existing baseline networks via knowledge distillation from off-the-shelf pre-trained big powerful models. Different from existing knowledge distillation frameworks which require student model to be consistent with both soft-label generated by teacher model and hard-label annotated by humans, our solution performs distillation by only driving prediction of the student model consistent with that of the teacher model. Therefore, our distillation setting can get rid of manually labeled data and can be trained with extra unlabeled data to fully exploit capability of teacher model for better learning. We empirically find that such simple distillation settings perform extremely effective, for example, the top-1 accuracy on ImageNet-1k validation set of MobileNetV3-large and ResNet50-D can be significantly improved from 75.2% to 79% and 79.1% to 83%, respectively. We have also thoroughly analyzed what are dominant factors that affect the distillation performance and how they make a difference. Extensive downstream computer vision tasks, including transfer learning, object detection and semantic segmentation, can significantly benefit from the distilled pretrained models. All our experiments are implemented based on PaddlePaddle, codes and a series of improved pretrained models with ssld suffix are available in PaddleClas.
PP-OCR: A Practical Ultra Lightweight OCR System
Oct 15, 2020

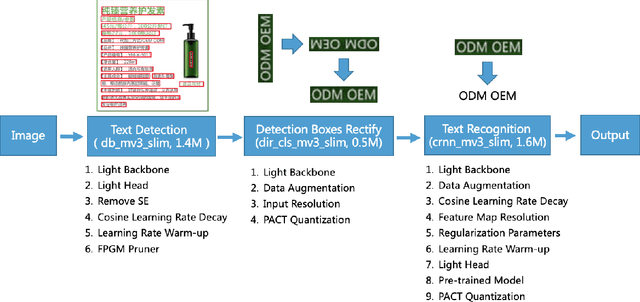
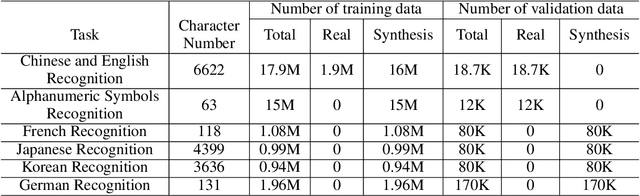
The Optical Character Recognition (OCR) systems have been widely used in various of application scenarios, such as office automation (OA) systems, factory automations, online educations, map productions etc. However, OCR is still a challenging task due to the various of text appearances and the demand of computational efficiency. In this paper, we propose a practical ultra lightweight OCR system, i.e., PP-OCR. The overall model size of the PP-OCR is only 3.5M for recognizing 6622 Chinese characters and 2.8M for recognizing 63 alphanumeric symbols, respectively. We introduce a bag of strategies to either enhance the model ability or reduce the model size. The corresponding ablation experiments with the real data are also provided. Meanwhile, several pre-trained models for the Chinese and English recognition are released, including a text detector (97K images are used), a direction classifier (600K images are used) as well as a text recognizer (17.9M images are used). Besides, the proposed PP-OCR are also verified in several other language recognition tasks, including French, Korean, Japanese and German. All of the above mentioned models are open-sourced and the codes are available in the GitHub repository, i.e., https://github.com/PaddlePaddle/PaddleOCR.
HS-ResNet: Hierarchical-Split Block on Convolutional Neural Network
Oct 15, 2020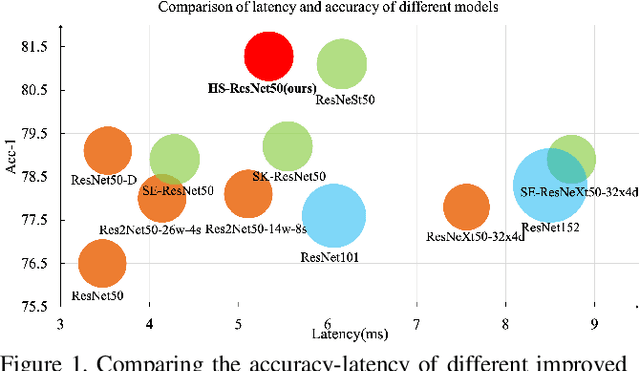
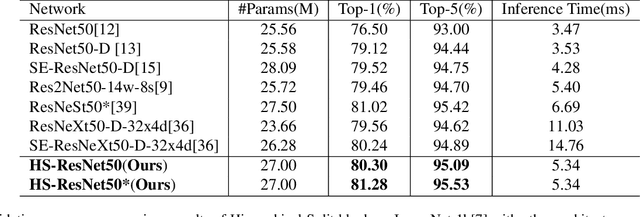
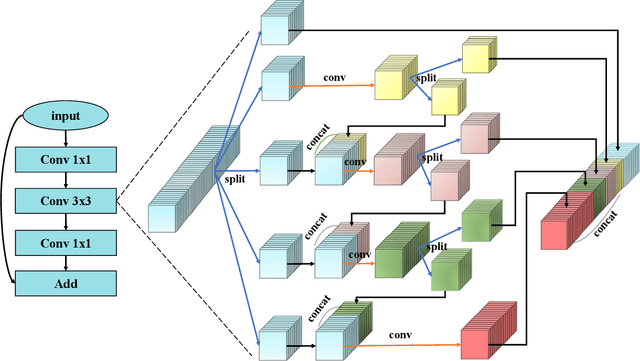

This paper addresses representational block named Hierarchical-Split Block, which can be taken as a plug-and-play block to upgrade existing convolutional neural networks, improves model performance significantly in a network. Hierarchical-Split Block contains many hierarchical split and concatenate connections within one single residual block. We find multi-scale features is of great importance for numerous vision tasks. Moreover, Hierarchical-Split block is very flexible and efficient, which provides a large space of potential network architectures for different applications. In this work, we present a common backbone based on Hierarchical-Split block for tasks: image classification, object detection, instance segmentation and semantic image segmentation/parsing. Our approach shows significant improvements over all these core tasks in comparison with the baseline. As shown in Figure1, for image classification, our 50-layers network(HS-ResNet50) achieves 81.28% top-1 accuracy with competitive latency on ImageNet-1k dataset. It also outperforms most state-of-the-art models. The source code and models will be available on: https://github.com/PaddlePaddle/PaddleClas
2nd Place Solution in Google AI Open Images Object Detection Track 2019
Nov 17, 2019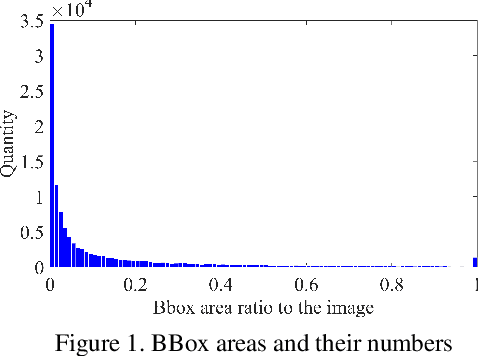
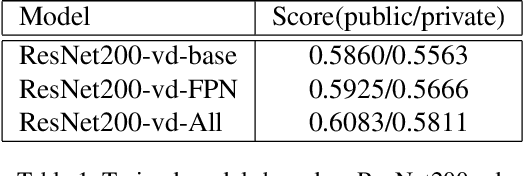


We present an object detection framework based on PaddlePaddle. We put all the strategies together (multi-scale training, FPN, Cascade, Dcnv2, Non-local, libra loss) based on ResNet200-vd backbone. Our model score on public leaderboard comes to 0.6269 with single scale test. We proposed a new voting method called top-k voting-nms, based on the SoftNMS detection results. The voting method helps us merge all the models' results more easily and achieve 2nd place in the Google AI Open Images Object Detection Track 2019.