 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System
Paper and Code


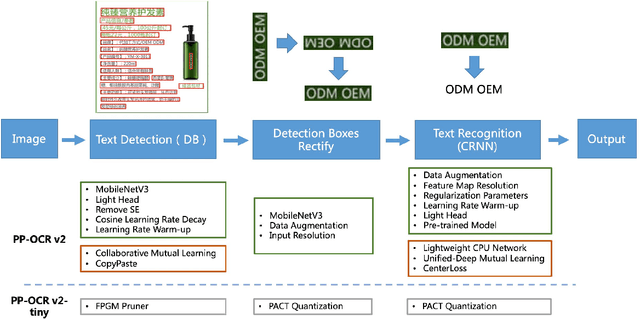
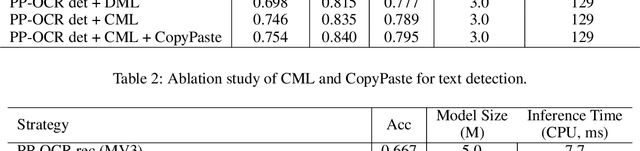
Optical Character Recognition (OCR) systems have been widely used in various of application scenarios. Designing an OCR system is still a challenging task. In previous work, we proposed a practical ultra lightweight OCR system (PP-OCR) to balance the accuracy against the efficiency. In order to improve the accuracy of PP-OCR and keep high efficiency, in this paper, we propose a more robust OCR system, i.e. PP-OCRv2. We introduce bag of tricks to train a better text detector and a better text recognizer, which include Collaborative Mutual Learning (CML), CopyPaste, Lightweight CPUNetwork (LCNet), Unified-Deep Mutual Learning (U-DML) and Enhanced CTCLoss. Experiments on real data show that the precision of PP-OCRv2 is 7% higher than PP-OCR under the same inference cost. It is also comparable to the server models of the PP-OCR which uses ResNet series as backbones. All of the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleOCR which is powered by PaddlePaddle.