 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongSkywork: A Training Recipe for Efficiently Extending Context Length in Large Language Models
Jun 02, 2024We introduce LongSkywork, a long-context Large Language Model (LLM) capable of processing up to 200,000 tokens. We provide a training recipe for efficiently extending context length of LLMs. We identify that the critical element in enhancing long-context processing capability is to incorporate a long-context SFT stage following the standard SFT stage. A mere 200 iterations can convert the standard SFT model into a long-context model. To reduce the effort in collecting and annotating data for long-context language modeling, we develop two novel methods for creating synthetic data. These methods are applied during the continual pretraining phase as well as the Supervised Fine-Tuning (SFT) phase, greatly enhancing the training efficiency of our long-context LLMs. Our findings suggest that synthetic long-context SFT data can surpass the performance of data curated by humans to some extent. LongSkywork achieves outstanding performance on a variety of long-context benchmarks. In the Needle test, a benchmark for long-context information retrieval, our models achieved perfect accuracy across multiple context spans. Moreover, in realistic application scenarios, LongSkywork-13B demonstrates performance on par with Claude2.1, the leading long-context model, underscoring the effectiveness of our proposed methods.
Skywork: A More Open Bilingual Foundation Model
Oct 30, 2023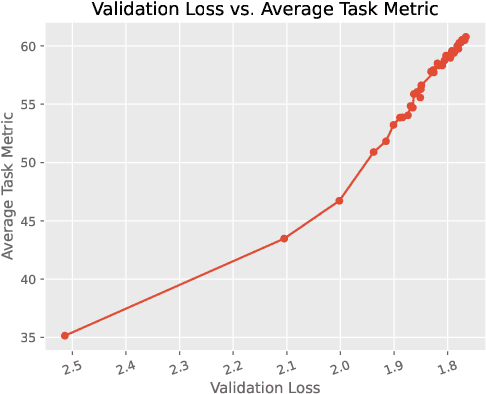
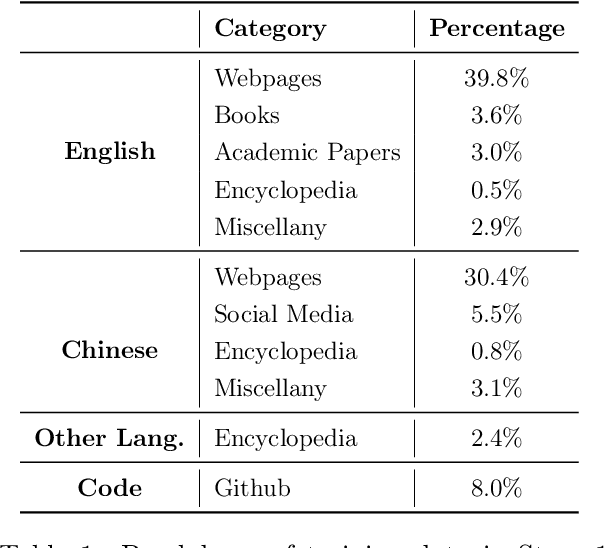
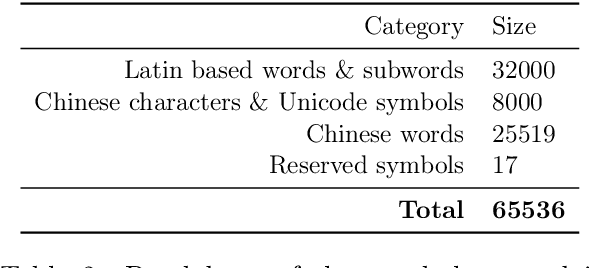
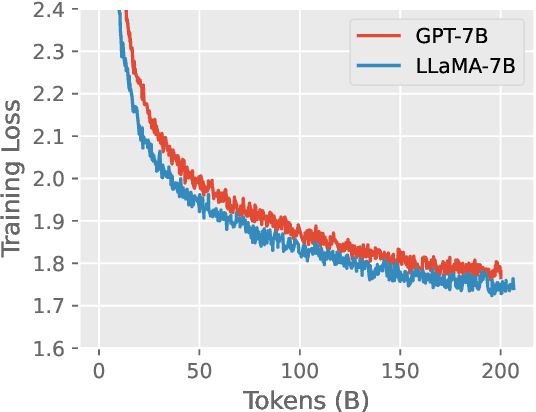
In this technical report, we present Skywork-13B, a family of large language models (LLMs) trained on a corpus of over 3.2 trillion tokens drawn from both English and Chinese texts. This bilingual foundation model is the most extensively trained and openly published LLMs of comparable size to date. We introduce a two-stage training methodology using a segmented corpus, targeting general purpose training and then domain-specific enhancement training, respectively. We show that our model not only excels on popular benchmarks, but also achieves \emph{state of the art} performance in Chinese language modeling on diverse domains. Furthermore, we propose a novel leakage detection method, demonstrating that test data contamination is a pressing issue warranting further investigation by the LLM community. To spur future research, we release Skywork-13B along with checkpoints obtained during intermediate stages of the training process. We are also releasing part of our SkyPile corpus, a collection of over 150 billion tokens of web text, which is the largest high quality open Chinese pre-training corpus to date. We hope Skywork-13B and our open corpus will serve as a valuable open-source resource to democratize access to high-quality LLMs.
SkyMath: Technical Report
Oct 26, 2023Large language models (LLMs) have shown great potential to solve varieties of natural language processing (NLP) tasks, including mathematical reasoning. In this work, we present SkyMath, a large language model for mathematics with 13 billion parameters. By applying self-compare fine-tuning, we have enhanced mathematical reasoning abilities of Skywork-13B-Base remarkably. On GSM8K, SkyMath outperforms all known open-source models of similar size and has established a new SOTA performance.
Context Perception Parallel Decoder for Scene Text Recognition
Jul 23, 2023



Scene text recognition (STR) methods have struggled to attain high accuracy and fast inference speed. Autoregressive (AR)-based STR model uses the previously recognized characters to decode the next character iteratively. It shows superiority in terms of accuracy. However, the inference speed is slow also due to this iteration. Alternatively, parallel decoding (PD)-based STR model infers all the characters in a single decoding pass. It has advantages in terms of inference speed but worse accuracy, as it is difficult to build a robust recognition context in such a pass. In this paper, we first present an empirical study of AR decoding in STR. In addition to constructing a new AR model with the top accuracy, we find out that the success of AR decoder lies also in providing guidance on visual context perception rather than language modeling as claimed in existing studies. As a consequence, we propose Context Perception Parallel Decoder (CPPD) to decode the character sequence in a single PD pass. CPPD devises a character counting module and a character ordering module. Given a text instance, the former infers the occurrence count of each character, while the latter deduces the character reading order and placeholders. Together with the character prediction task, they construct a context that robustly tells what the character sequence is and where the characters appear, well mimicking the context conveyed by AR decoding. Experiments on both English and Chinese benchmarks demonstrate that CPPD models achieve highly competitive accuracy. Moreover, they run approximately 7x faster than their AR counterparts, and are also among the fastest recognizers. The code will be released soon.
PP-StructureV2: A Stronger Document Analysis System
Oct 11, 2022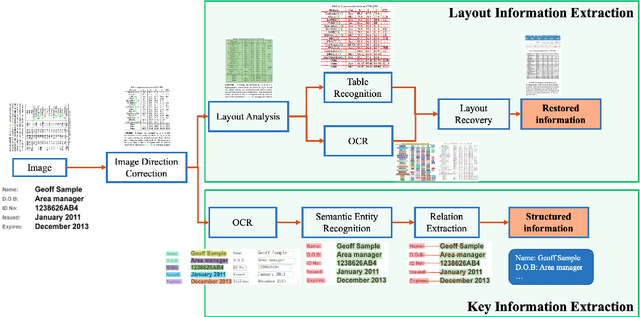



A large amount of document data exists in unstructured form such as raw images without any text information. Designing a practical document image analysis system is a meaningful but challenging task. In previous work, we proposed an intelligent document analysis system PP-Structure. In order to further upgrade the function and performance of PP-Structure, we propose PP-StructureV2 in this work, which contains two subsystems: Layout Information Extraction and Key Information Extraction. Firstly, we integrate Image Direction Correction module and Layout Restoration module to enhance the functionality of the system. Secondly, 8 practical strategies are utilized in PP-StructureV2 for better performance. For Layout Analysis model, we introduce ultra light-weight detector PP-PicoDet and knowledge distillation algorithm FGD for model lightweighting, which increased the inference speed by 11 times with comparable mAP. For Table Recognition model, we utilize PP-LCNet, CSP-PAN and SLAHead to optimize the backbone module, feature fusion module and decoding module, respectively, which improved the table structure accuracy by 6\% with comparable inference speed. For Key Information Extraction model, we introduce VI-LayoutXLM which is a visual-feature independent LayoutXLM architecture, TB-YX sorting algorithm and U-DML knowledge distillation algorithm, which brought 2.8\% and 9.1\% improvement respectively on the Hmean of Semantic Entity Recognition and Relation Extraction tasks. All the above mentioned models and code are open-sourced in the GitHub repository PaddleOCR.
PP-OCRv3: More Attempts for the Improvement of Ultra Lightweight OCR System
Jun 07, 2022

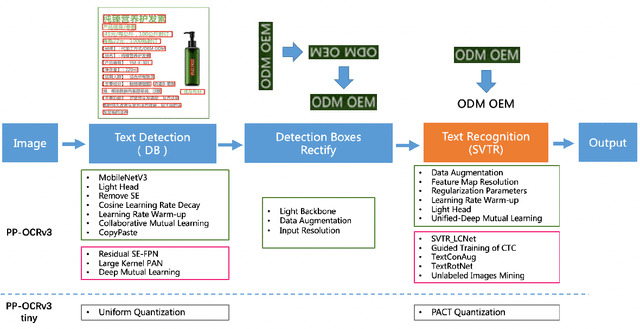
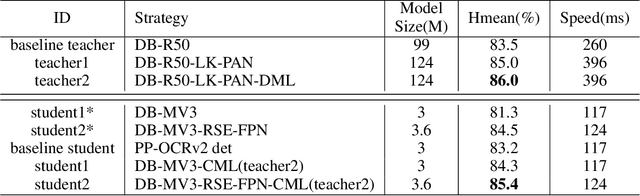
Optical character recognition (OCR) technology has been widely used in various scenes, as shown in Figure 1. Designing a practical OCR system is still a meaningful but challenging task. In previous work, considering the efficiency and accuracy, we proposed a practical ultra lightweight OCR system (PP-OCR), and an optimized version PP-OCRv2. In order to further improve the performance of PP-OCRv2, a more robust OCR system PP-OCRv3 is proposed in this paper. PP-OCRv3 upgrades the text detection model and text recognition model in 9 aspects based on PP-OCRv2. For text detector, we introduce a PAN module with large receptive field named LK-PAN, a FPN module with residual attention mechanism named RSE-FPN, and DML distillation strategy. For text recognizer, the base model is replaced from CRNN to SVTR, and we introduce lightweight text recognition network SVTR LCNet, guided training of CTC by attention, data augmentation strategy TextConAug, better pre-trained model by self-supervised TextRotNet, UDML, and UIM to accelerate the model and improve the effect. Experiments on real data show that the hmean of PP-OCRv3 is 5% higher than PP-OCRv2 under comparable inference speed. All the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleOCR which is powered by PaddlePaddle.
SVTR: Scene Text Recognition with a Single Visual Model
Apr 30, 2022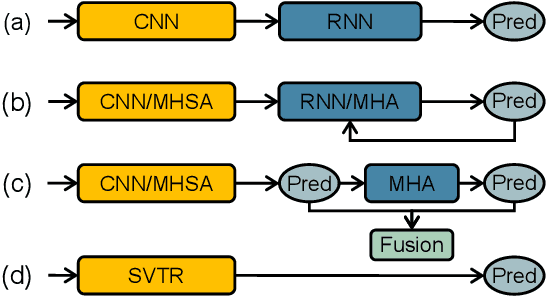

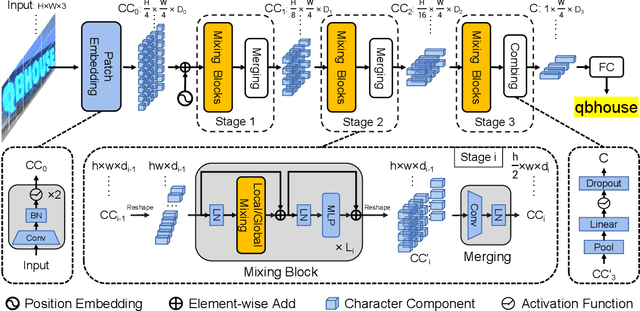

Dominant scene text recognition models commonly contain two building blocks, a visual model for feature extraction and a sequence model for text transcription. This hybrid architecture, although accurate, is complex and less efficient. In this study, we propose a Single Visual model for Scene Text recognition within the patch-wise image tokenization framework, which dispenses with the sequential modeling entirely. The method, termed SVTR, firstly decomposes an image text into small patches named character components. Afterward, hierarchical stages are recurrently carried out by component-level mixing, merging and/or combining. Global and local mixing blocks are devised to perceive the inter-character and intra-character patterns, leading to a multi-grained character component perception. Thus, characters are recognized by a simple linear prediction. Experimental results on both English and Chinese scene text recognition tasks demonstrate the effectiveness of SVTR. SVTR-L (Large) achieves highly competitive accuracy in English and outperforms existing methods by a large margin in Chinese, while running faster. In addition, SVTR-T (Tiny) is an effective and much smaller model, which shows appealing speed at inference. The code is publicly available at https://github.com/PaddlePaddle/PaddleOCR.
* 7pages,6figures
PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System
Sep 07, 2021

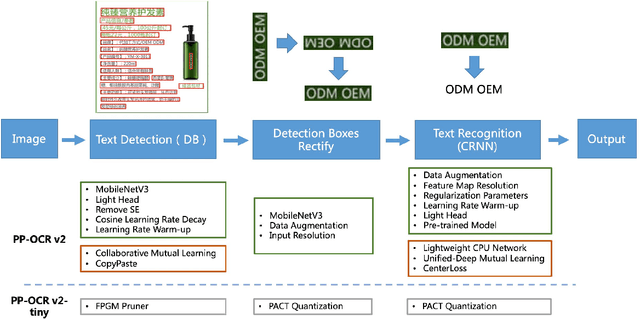
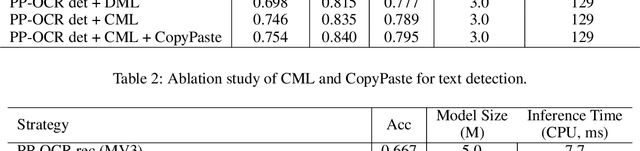
Optical Character Recognition (OCR) systems have been widely used in various of application scenarios. Designing an OCR system is still a challenging task. In previous work, we proposed a practical ultra lightweight OCR system (PP-OCR) to balance the accuracy against the efficiency. In order to improve the accuracy of PP-OCR and keep high efficiency, in this paper, we propose a more robust OCR system, i.e. PP-OCRv2. We introduce bag of tricks to train a better text detector and a better text recognizer, which include Collaborative Mutual Learning (CML), CopyPaste, Lightweight CPUNetwork (LCNet), Unified-Deep Mutual Learning (U-DML) and Enhanced CTCLoss. Experiments on real data show that the precision of PP-OCRv2 is 7% higher than PP-OCR under the same inference cost. It is also comparable to the server models of the PP-OCR which uses ResNet series as backbones. All of the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleOCR which is powered by PaddlePaddle.
PP-OCR: A Practical Ultra Lightweight OCR System
Oct 15, 2020

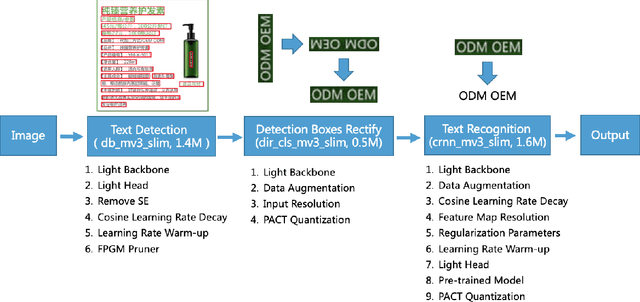
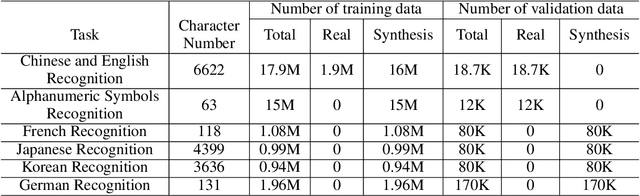
The Optical Character Recognition (OCR) systems have been widely used in various of application scenarios, such as office automation (OA) systems, factory automations, online educations, map productions etc. However, OCR is still a challenging task due to the various of text appearances and the demand of computational efficiency. In this paper, we propose a practical ultra lightweight OCR system, i.e., PP-OCR. The overall model size of the PP-OCR is only 3.5M for recognizing 6622 Chinese characters and 2.8M for recognizing 63 alphanumeric symbols, respectively. We introduce a bag of strategies to either enhance the model ability or reduce the model size. The corresponding ablation experiments with the real data are also provided. Meanwhile, several pre-trained models for the Chinese and English recognition are released, including a text detector (97K images are used), a direction classifier (600K images are used) as well as a text recognizer (17.9M images are used). Besides, the proposed PP-OCR are also verified in several other language recognition tasks, including French, Korean, Japanese and German. All of the above mentioned models are open-sourced and the codes are available in the GitHub repository, i.e., https://github.com/PaddlePaddle/PaddleOCR.