 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEMON-Mapping: Loop-Enhanced Large-Scale Multi-Session Point Cloud Merging and Optimization for Globally Consistent Mapping
May 15, 2025With the rapid development of robotics, multi-robot collaboration has become critical and challenging. One key problem is integrating data from multiple robots to build a globally consistent and accurate map for robust cooperation and precise localization. While traditional multi-robot pose graph optimization (PGO) maintains basic global consistency, it focuses primarily on pose optimization and ignores the geometric structure of the map. Moreover, PGO only uses loop closure as a constraint between two nodes, failing to fully exploit its capability to maintaining local consistency of multi-robot maps. Therefore, PGO-based multi-robot mapping methods often suffer from serious map divergence and blur, especially in regions with overlapping submaps. To address this issue, we propose Lemon-Mapping, a loop-enhanced framework for large-scale multi-session point cloud map fusion and optimization, which reasonably utilizes loop closure and improves the geometric quality of the map. We re-examine the role of loops for multi-robot mapping and introduce three key innovations. First, we develop a robust loop processing mechanism that effectively rejects outliers and a novel loop recall strategy to recover mistakenly removed loops. Second, we introduce a spatial bundle adjustment method for multi-robot maps that significantly reduces the divergence in overlapping regions and eliminates map blur. Third, we design a PGO strategy that leverages the refined constraints of bundle adjustment to extend the local accuracy to the global map. We validate our framework on several public datasets and a self-collected dataset. Experimental results demonstrate that our method outperforms traditional map merging approaches in terms of mapping accuracy and reduction of map divergence. Scalability experiments also demonstrate the strong capability of our framework to handle scenarios involving numerous robots.
LongSkywork: A Training Recipe for Efficiently Extending Context Length in Large Language Models
Jun 02, 2024We introduce LongSkywork, a long-context Large Language Model (LLM) capable of processing up to 200,000 tokens. We provide a training recipe for efficiently extending context length of LLMs. We identify that the critical element in enhancing long-context processing capability is to incorporate a long-context SFT stage following the standard SFT stage. A mere 200 iterations can convert the standard SFT model into a long-context model. To reduce the effort in collecting and annotating data for long-context language modeling, we develop two novel methods for creating synthetic data. These methods are applied during the continual pretraining phase as well as the Supervised Fine-Tuning (SFT) phase, greatly enhancing the training efficiency of our long-context LLMs. Our findings suggest that synthetic long-context SFT data can surpass the performance of data curated by humans to some extent. LongSkywork achieves outstanding performance on a variety of long-context benchmarks. In the Needle test, a benchmark for long-context information retrieval, our models achieved perfect accuracy across multiple context spans. Moreover, in realistic application scenarios, LongSkywork-13B demonstrates performance on par with Claude2.1, the leading long-context model, underscoring the effectiveness of our proposed methods.
Graph Attention-Based Symmetry Constraint Extraction for Analog Circuits
Dec 22, 2023



In recent years, analog circuits have received extensive attention and are widely used in many emerging applications. The high demand for analog circuits necessitates shorter circuit design cycles. To achieve the desired performance and specifications, various geometrical symmetry constraints must be carefully considered during the analog layout process. However, the manual labeling of these constraints by experienced analog engineers is a laborious and time-consuming process. To handle the costly runtime issue, we propose a graph-based learning framework to automatically extract symmetric constraints in analog circuit layout. The proposed framework leverages the connection characteristics of circuits and the devices'information to learn the general rules of symmetric constraints, which effectively facilitates the extraction of device-level constraints on circuit netlists. The experimental results demonstrate that compared to state-of-the-art symmetric constraint detection approaches, our framework achieves higher accuracy and lower false positive rate.
IBADR: an Iterative Bias-Aware Dataset Refinement Framework for Debiasing NLU models
Nov 01, 2023



As commonly-used methods for debiasing natural language understanding (NLU) models, dataset refinement approaches heavily rely on manual data analysis, and thus maybe unable to cover all the potential biased features. In this paper, we propose IBADR, an Iterative Bias-Aware Dataset Refinement framework, which debiases NLU models without predefining biased features. We maintain an iteratively expanded sample pool. Specifically, at each iteration, we first train a shallow model to quantify the bias degree of samples in the pool. Then, we pair each sample with a bias indicator representing its bias degree, and use these extended samples to train a sample generator. In this way, this generator can effectively learn the correspondence relationship between bias indicators and samples. Furthermore, we employ the generator to produce pseudo samples with fewer biased features by feeding specific bias indicators. Finally, we incorporate the generated pseudo samples into the pool. Experimental results and in-depth analyses on two NLU tasks show that IBADR not only significantly outperforms existing dataset refinement approaches, achieving SOTA, but also is compatible with model-centric methods.
Skywork: A More Open Bilingual Foundation Model
Oct 30, 2023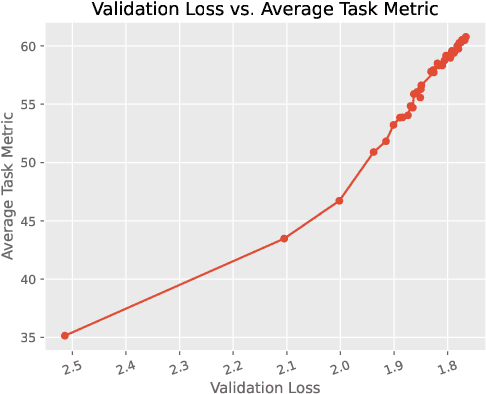
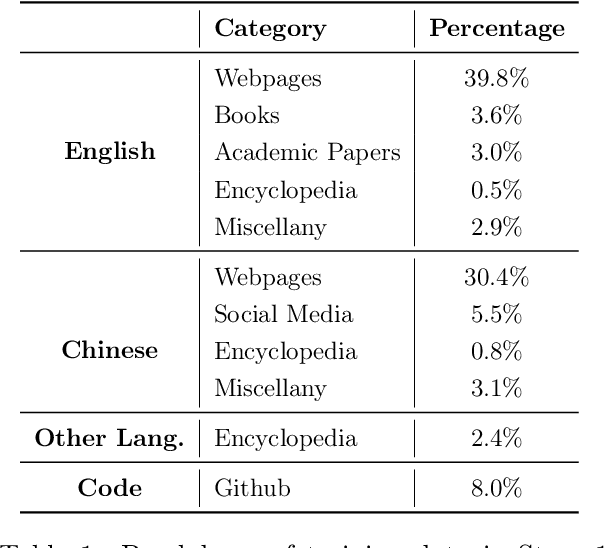
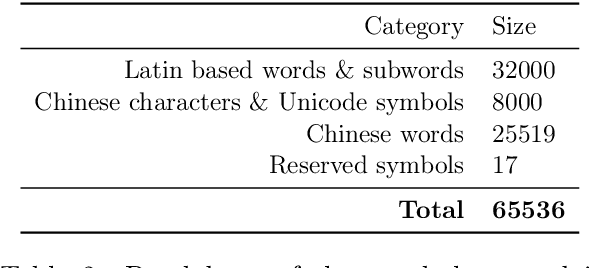
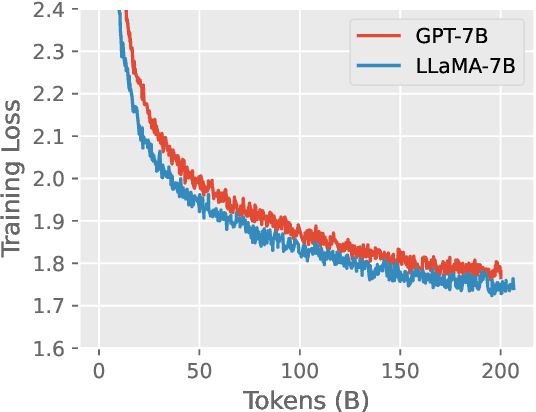
In this technical report, we present Skywork-13B, a family of large language models (LLMs) trained on a corpus of over 3.2 trillion tokens drawn from both English and Chinese texts. This bilingual foundation model is the most extensively trained and openly published LLMs of comparable size to date. We introduce a two-stage training methodology using a segmented corpus, targeting general purpose training and then domain-specific enhancement training, respectively. We show that our model not only excels on popular benchmarks, but also achieves \emph{state of the art} performance in Chinese language modeling on diverse domains. Furthermore, we propose a novel leakage detection method, demonstrating that test data contamination is a pressing issue warranting further investigation by the LLM community. To spur future research, we release Skywork-13B along with checkpoints obtained during intermediate stages of the training process. We are also releasing part of our SkyPile corpus, a collection of over 150 billion tokens of web text, which is the largest high quality open Chinese pre-training corpus to date. We hope Skywork-13B and our open corpus will serve as a valuable open-source resource to democratize access to high-quality LLMs.
SkyMath: Technical Report
Oct 26, 2023Large language models (LLMs) have shown great potential to solve varieties of natural language processing (NLP) tasks, including mathematical reasoning. In this work, we present SkyMath, a large language model for mathematics with 13 billion parameters. By applying self-compare fine-tuning, we have enhanced mathematical reasoning abilities of Skywork-13B-Base remarkably. On GSM8K, SkyMath outperforms all known open-source models of similar size and has established a new SOTA performance.
A Simple yet Effective Self-Debiasing Framework for Transformer Models
Jun 02, 2023
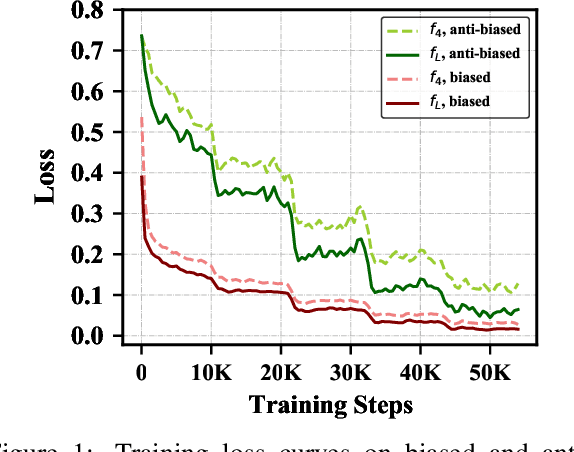
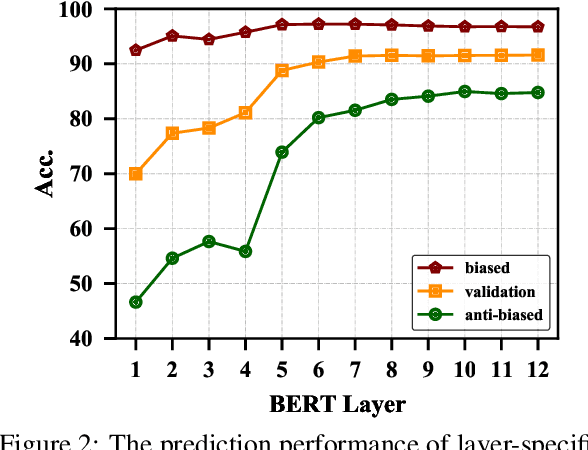

Current Transformer-based natural language understanding (NLU) models heavily rely on dataset biases, while failing to handle real-world out-of-distribution (OOD) instances. Many methods have been proposed to deal with this issue, but they ignore the fact that the features learned in different layers of Transformer-based NLU models are different. In this paper, we first conduct preliminary studies to obtain two conclusions: 1) both low- and high-layer sentence representations encode common biased features during training; 2) the low-layer sentence representations encode fewer unbiased features than the highlayer ones. Based on these conclusions, we propose a simple yet effective self-debiasing framework for Transformer-based NLU models. Concretely, we first stack a classifier on a selected low layer. Then, we introduce a residual connection that feeds the low-layer sentence representation to the top-layer classifier. In this way, the top-layer sentence representation will be trained to ignore the common biased features encoded by the low-layer sentence representation and focus on task-relevant unbiased features. During inference, we remove the residual connection and directly use the top-layer sentence representation to make predictions. Extensive experiments and indepth analyses on NLU tasks show that our framework performs better than several competitive baselines, achieving a new SOTA on all OOD test sets.
SeSQL: Yet Another Large-scale Session-level Chinese Text-to-SQL Dataset
Aug 26, 2022
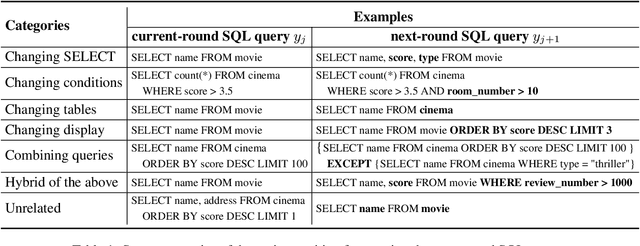
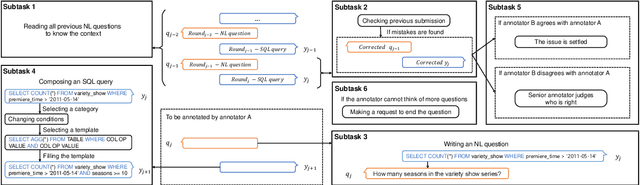
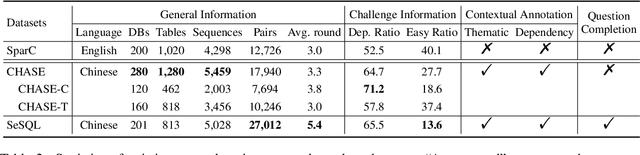
As the first session-level Chinese dataset, CHASE contains two separate parts, i.e., 2,003 sessions manually constructed from scratch (CHASE-C), and 3,456 sessions translated from English SParC (CHASE-T). We find the two parts are highly discrepant and incompatible as training and evaluation data. In this work, we present SeSQL, yet another large-scale session-level text-to-SQL dataset in Chinese, consisting of 5,028 sessions all manually constructed from scratch. In order to guarantee data quality, we adopt an iterative annotation workflow to facilitate intense and in-time review of previous-round natural language (NL) questions and SQL queries. Moreover, by completing all context-dependent NL questions, we obtain 27,012 context-independent question/SQL pairs, allowing SeSQL to be used as the largest dataset for single-round multi-DB text-to-SQL parsing. We conduct benchmark session-level text-to-SQL parsing experiments on SeSQL by employing three competitive session-level parsers, and present detailed analysis.
An Interpretability Evaluation Benchmark for Pre-trained Language Models
Jul 28, 2022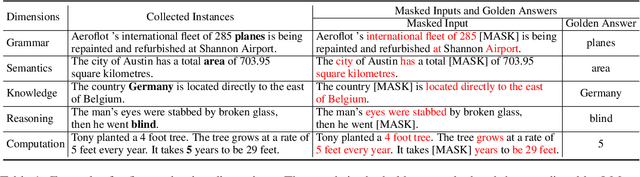
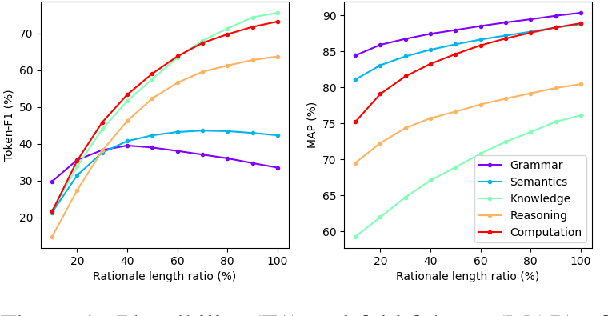

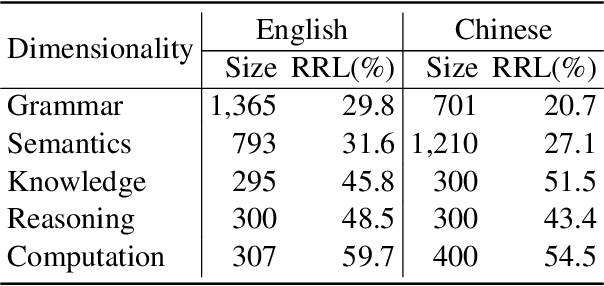
While pre-trained language models (LMs) have brought great improvements in many NLP tasks, there is increasing attention to explore capabilities of LMs and interpret their predictions. However, existing works usually focus only on a certain capability with some downstream tasks. There is a lack of datasets for directly evaluating the masked word prediction performance and the interpretability of pre-trained LMs. To fill in the gap, we propose a novel evaluation benchmark providing with both English and Chinese annotated data. It tests LMs abilities in multiple dimensions, i.e., grammar, semantics, knowledge, reasoning and computation. In addition, it provides carefully annotated token-level rationales that satisfy sufficiency and compactness. It contains perturbed instances for each original instance, so as to use the rationale consistency under perturbations as the metric for faithfulness, a perspective of interpretability. We conduct experiments on several widely-used pre-trained LMs. The results show that they perform very poorly on the dimensions of knowledge and computation. And their plausibility in all dimensions is far from satisfactory, especially when the rationale is short. In addition, the pre-trained LMs we evaluated are not robust on syntax-aware data. We will release this evaluation benchmark at \url{http://xyz}, and hope it can facilitate the research progress of pre-trained LMs.
A Fine-grained Interpretability Evaluation Benchmark for Neural NLP
May 23, 2022
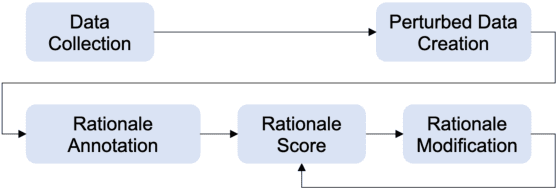
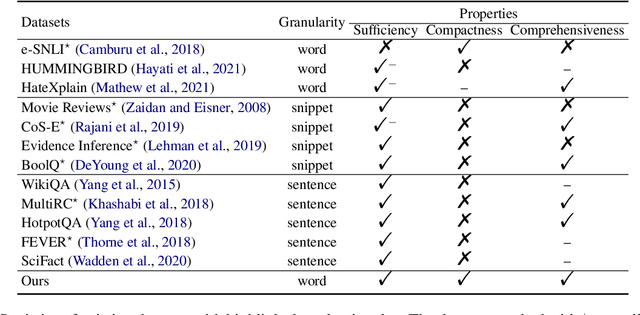
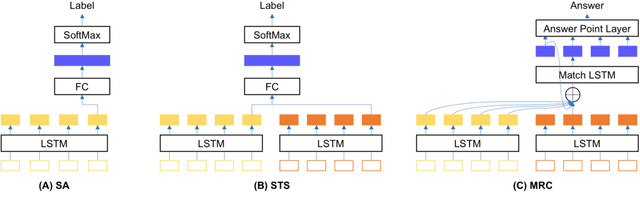
While there is increasing concern about the interpretability of neural models, the evaluation of interpretability remains an open problem, due to the lack of proper evaluation datasets and metrics. In this paper, we present a novel benchmark to evaluate the interpretability of both neural models and saliency methods. This benchmark covers three representative NLP tasks: sentiment analysis, textual similarity and reading comprehension, each provided with both English and Chinese annotated data. In order to precisely evaluate the interpretability, we provide token-level rationales that are carefully annotated to be sufficient, compact and comprehensive. We also design a new metric, i.e., the consistency between the rationales before and after perturbations, to uniformly evaluate the interpretability of models and saliency methods on different tasks. Based on this benchmark, we conduct experiments on three typical models with three saliency methods, and unveil their strengths and weakness in terms of interpretability. We will release this benchmark at \url{https://xyz} and hope it can facilitate the research in building trustworthy systems.