 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Source Retrieval and Reasoning for Legal Sentencing Prediction
Feb 04, 2026Legal judgment prediction (LJP) aims to predict judicial outcomes from case facts and typically includes law article, charge, and sentencing prediction. While recent methods perform well on the first two subtasks, legal sentencing prediction (LSP) remains difficult due to its need for fine-grained objective knowledge and flexible subjective reasoning. To address these limitations, we propose $MSR^2$, a framework that integrates multi-source retrieval and reasoning in LLMs with reinforcement learning. $MSR^2$ enables LLMs to perform multi-source retrieval based on reasoning needs and applies a process-level reward to guide intermediate subjective reasoning steps. Experiments on two real-world datasets show that $MSR^2$ improves both accuracy and interpretability in LSP, providing a promising step toward practical legal AI. Our code is available at https://anonymous.4open.science/r/MSR2-FC3B.
FGNet: Leveraging Feature-Guided Attention to Refine SAM2 for 3D EM Neuron Segmentation
Nov 17, 2025Accurate segmentation of neural structures in Electron Microscopy (EM) images is paramount for neuroscience. However, this task is challenged by intricate morphologies, low signal-to-noise ratios, and scarce annotations, limiting the accuracy and generalization of existing methods. To address these challenges, we seek to leverage the priors learned by visual foundation models on a vast amount of natural images to better tackle this task. Specifically, we propose a novel framework that can effectively transfer knowledge from Segment Anything 2 (SAM2), which is pre-trained on natural images, to the EM domain. We first use SAM2 to extract powerful, general-purpose features. To bridge the domain gap, we introduce a Feature-Guided Attention module that leverages semantic cues from SAM2 to guide a lightweight encoder, the Fine-Grained Encoder (FGE), in focusing on these challenging regions. Finally, a dual-affinity decoder generates both coarse and refined affinity maps. Experimental results demonstrate that our method achieves performance comparable to state-of-the-art (SOTA) approaches with the SAM2 weights frozen. Upon further fine-tuning on EM data, our method significantly outperforms existing SOTA methods. This study validates that transferring representations pre-trained on natural images, when combined with targeted domain-adaptive guidance, can effectively address the specific challenges in neuron segmentation.
Think Smart, Not Hard: Difficulty Adaptive Reasoning for Large Audio Language Models
Sep 26, 2025Large Audio Language Models (LALMs), powered by the chain-of-thought (CoT) paradigm, have shown remarkable reasoning capabilities. Intuitively, different problems often require varying depths of reasoning. While some methods can determine whether to reason for a given problem, they typically lack a fine-grained mechanism to modulate how much to reason. This often results in a ``one-size-fits-all'' reasoning depth, which generates redundant overthinking for simple questions while failing to allocate sufficient thought to complex ones. In this paper, we conduct an in-depth analysis of LALMs and find that an effective and efficient LALM should reason smartly by adapting its reasoning depth to the problem's complexity. To achieve this, we propose a difficulty-adaptive reasoning method for LALMs. Specifically, we propose a reward function that dynamically links reasoning length to the model's perceived problem difficulty. This reward encourages shorter, concise reasoning for easy tasks and more elaborate, in-depth reasoning for complex ones. Extensive experiments demonstrate that our method is both effective and efficient, simultaneously improving task performance and significantly reducing the average reasoning length. Further analysis on reasoning structure paradigm offers valuable insights for future work.
Improving Contextual ASR via Multi-grained Fusion with Large Language Models
Jul 16, 2025While end-to-end Automatic Speech Recognition (ASR) models have shown impressive performance in transcribing general speech, they often struggle to accurately recognize contextually relevant keywords, such as proper nouns or user-specific entities. Previous approaches have explored leveraging keyword dictionaries in the textual modality to improve keyword recognition, either through token-level fusion that guides token-by-token generation or phrase-level fusion that enables direct copying of keyword phrases. However, these methods operate at different granularities and have their own limitations. In this paper, we propose a novel multi-grained fusion approach that jointly leverages the strengths of both token-level and phrase-level fusion with Large Language Models (LLMs). Our approach incorporates a late-fusion strategy that elegantly combines ASR's acoustic information with LLM's rich contextual knowledge, balancing fine-grained token precision with holistic phrase-level understanding. Experiments on Chinese and English datasets demonstrate that our approach achieves state-of-the-art performance on keyword-related metrics while preserving high accuracy on non-keyword text. Ablation studies further confirm that the token-level and phrase-level components both contribute significantly to the performance gains, complementing each other in our joint multi-grained framework. The code and models will be publicly available at https://github.com/.
Mixture of Small and Large Models for Chinese Spelling Check
Jun 07, 2025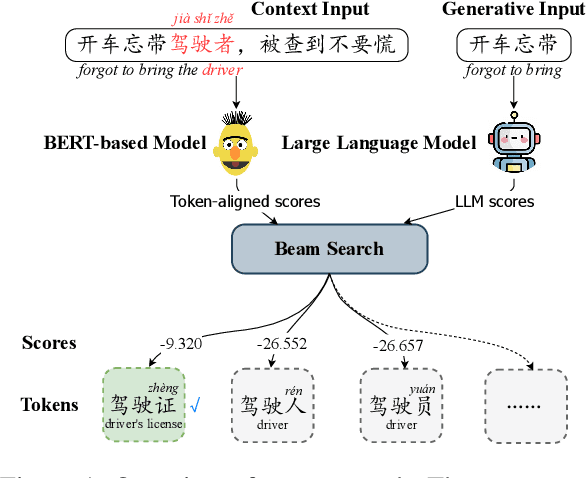
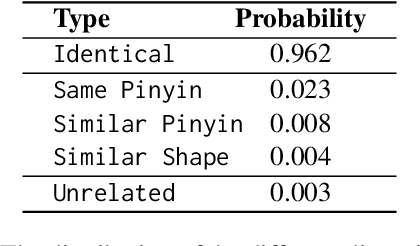
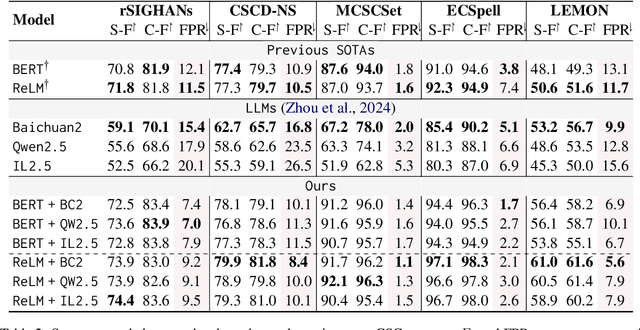

In the era of large language models (LLMs), the Chinese Spelling Check (CSC) task has seen various LLM methods developed, yet their performance remains unsatisfactory. In contrast, fine-tuned BERT-based models, relying on high-quality in-domain data, show excellent performance but suffer from edit pattern overfitting. This paper proposes a novel dynamic mixture approach that effectively combines the probability distributions of small models and LLMs during the beam search decoding phase, achieving a balanced enhancement of precise corrections from small models and the fluency of LLMs. This approach also eliminates the need for fine-tuning LLMs, saving significant time and resources, and facilitating domain adaptation. Comprehensive experiments demonstrate that our mixture approach significantly boosts error correction capabilities, achieving state-of-the-art results across multiple datasets. Our code is available at https://github.com/zhqiao-nlp/MSLLM.
Self-Correction Makes LLMs Better Parsers
Apr 19, 2025Large language models (LLMs) have achieved remarkable success across various natural language processing (NLP) tasks. However, recent studies suggest that they still face challenges in performing fundamental NLP tasks essential for deep language understanding, particularly syntactic parsing. In this paper, we conduct an in-depth analysis of LLM parsing capabilities, delving into the specific shortcomings of their parsing results. We find that LLMs may stem from limitations to fully leverage grammar rules in existing treebanks, which restricts their capability to generate valid syntactic structures. To help LLMs acquire knowledge without additional training, we propose a self-correction method that leverages grammar rules from existing treebanks to guide LLMs in correcting previous errors. Specifically, we automatically detect potential errors and dynamically search for relevant rules, offering hints and examples to guide LLMs in making corrections themselves. Experimental results on three datasets with various LLMs, demonstrate that our method significantly improves performance in both in-domain and cross-domain settings on the English and Chinese datasets.
A Training-free LLM-based Approach to General Chinese Character Error Correction
Feb 21, 2025



Chinese spelling correction (CSC) is a crucial task that aims to correct character errors in Chinese text. While conventional CSC focuses on character substitution errors caused by mistyping, two other common types of character errors, missing and redundant characters, have received less attention. These errors are often excluded from CSC datasets during the annotation process or ignored during evaluation, even when they have been annotated. This issue limits the practicality of the CSC task. To address this issue, we introduce the task of General Chinese Character Error Correction (C2EC), which focuses on all three types of character errors. We construct a high-quality C2EC benchmark by combining and manually verifying data from CCTC and Lemon datasets. We extend the training-free prompt-free CSC method to C2EC by using Levenshtein distance for handling length changes and leveraging an additional prompt-based large language model (LLM) to improve performance. Experiments show that our method enables a 14B-parameter LLM to be on par with models nearly 50 times larger on both conventional CSC and C2EC tasks, without any fine-tuning.
Capturing Nuanced Preferences: Preference-Aligned Distillation for Small Language Models
Feb 20, 2025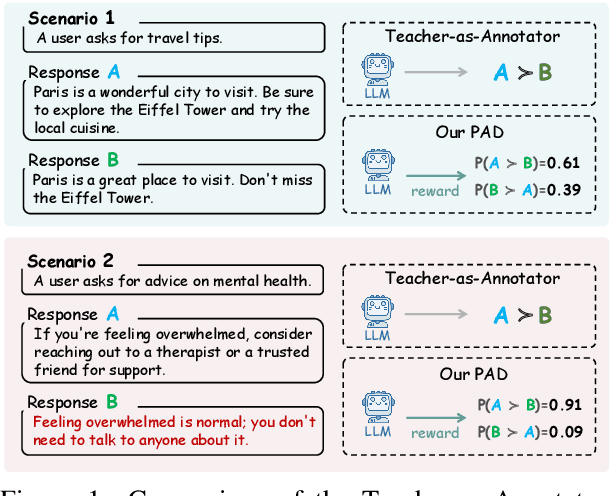
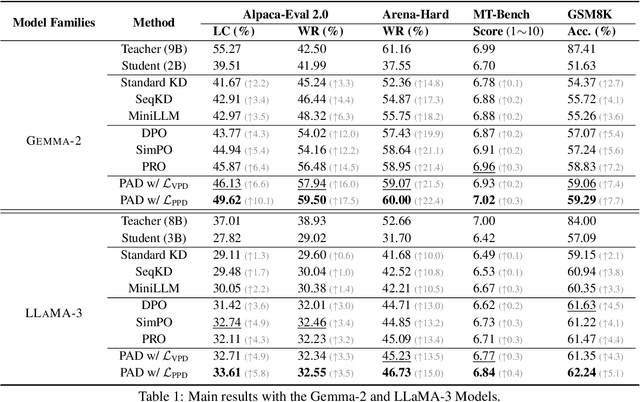
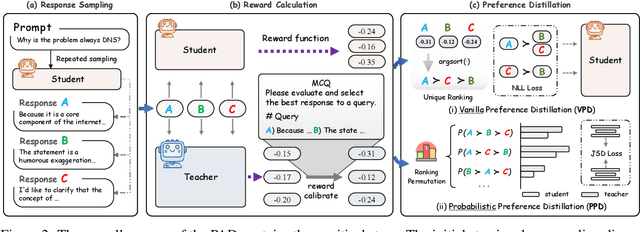
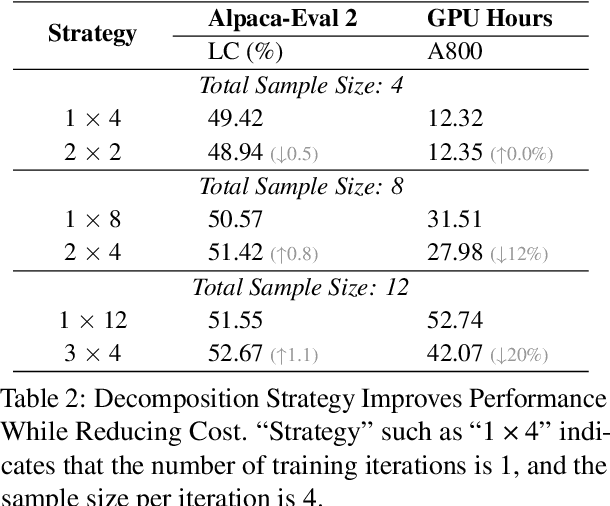
Aligning small language models (SLMs) with human values typically involves distilling preference knowledge from large language models (LLMs). However, existing distillation methods model preference knowledge in teacher LLMs by comparing pairwise responses, overlooking the extent of difference between responses. This limitation hinders student SLMs from capturing the nuanced preferences for multiple responses. In this paper, we propose a Preference-Aligned Distillation (PAD) framework, which models teacher's preference knowledge as a probability distribution over all potential preferences, thereby providing more nuanced supervisory signals. Our insight in developing PAD is rooted in the demonstration that language models can serve as reward functions, reflecting their intrinsic preferences. Based on this, PAD comprises three key steps: (1) sampling diverse responses using high-temperature; (2) computing rewards for both teacher and student to construct their intrinsic preference; and (3) training the student's intrinsic preference distribution to align with the teacher's. Experiments on four mainstream alignment benchmarks demonstrate that PAD consistently and significantly outperforms existing approaches, achieving over 20\% improvement on AlpacaEval 2 and Arena-Hard, indicating superior alignment with human preferences. Notably, on MT-Bench, using the \textsc{Gemma} model family, the student trained by PAD surpasses its teacher, further validating the effectiveness of our PAD.
DISC: Plug-and-Play Decoding Intervention with Similarity of Characters for Chinese Spelling Check
Dec 17, 2024



One key characteristic of the Chinese spelling check (CSC) task is that incorrect characters are usually similar to the correct ones in either phonetics or glyph. To accommodate this, previous works usually leverage confusion sets, which suffer from two problems, i.e., difficulty in determining which character pairs to include and lack of probabilities to distinguish items in the set. In this paper, we propose a light-weight plug-and-play DISC (i.e., decoding intervention with similarity of characters) module for CSC models.DISC measures phonetic and glyph similarities between characters and incorporates this similarity information only during the inference phase. This method can be easily integrated into various existing CSC models, such as ReaLiSe, SCOPE, and ReLM, without additional training costs. Experiments on three CSC benchmarks demonstrate that our proposed method significantly improves model performance, approaching and even surpassing the current state-of-the-art models.
Mining Word Boundaries from Speech-Text Parallel Data for Cross-domain Chinese Word Segmentation
Dec 12, 2024



Inspired by early research on exploring naturally annotated data for Chinese Word Segmentation (CWS), and also by recent research on integration of speech and text processing, this work for the first time proposes to explicitly mine word boundaries from speech-text parallel data. We employ the Montreal Forced Aligner (MFA) toolkit to perform character-level alignment on speech-text data, giving pauses as candidate word boundaries. Based on detailed analysis of collected pauses, we propose an effective probability-based strategy for filtering unreliable word boundaries. To more effectively utilize word boundaries as extra training data, we also propose a robust complete-then-train (CTT) strategy. We conduct cross-domain CWS experiments on two target domains, i.e., ZX and AISHELL2. We have annotated about 1,000 sentences as the evaluation data of AISHELL2. Experiments demonstrate the effectiveness of our proposed approach.