 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperG: Hypergraph-Enhanced LLMs for Structured Knowledge
Feb 25, 2025Given that substantial amounts of domain-specific knowledge are stored in structured formats, such as web data organized through HTML, Large Language Models (LLMs) are expected to fully comprehend this structured information to broaden their applications in various real-world downstream tasks. Current approaches for applying LLMs to structured data fall into two main categories: serialization-based and operation-based methods. Both approaches, whether relying on serialization or using SQL-like operations as an intermediary, encounter difficulties in fully capturing structural relationships and effectively handling sparse data. To address these unique characteristics of structured data, we propose HyperG, a hypergraph-based generation framework aimed at enhancing LLMs' ability to process structured knowledge. Specifically, HyperG first augment sparse data with contextual information, leveraging the generative power of LLMs, and incorporate a prompt-attentive hypergraph learning (PHL) network to encode both the augmented information and the intricate structural relationships within the data. To validate the effectiveness and generalization of HyperG, we conduct extensive experiments across two different downstream tasks requiring structured knowledge.
Capturing Nuanced Preferences: Preference-Aligned Distillation for Small Language Models
Feb 20, 2025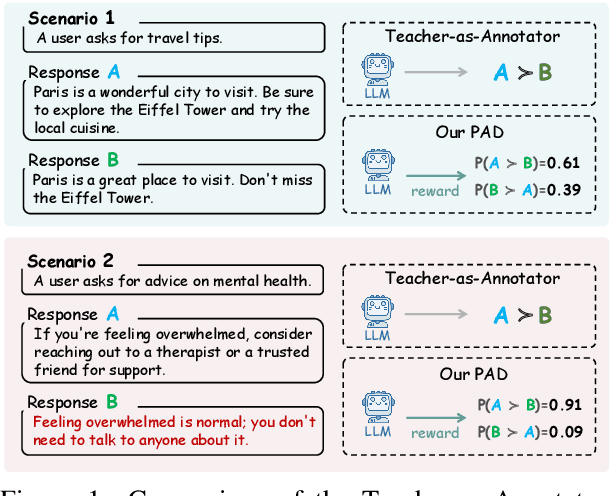
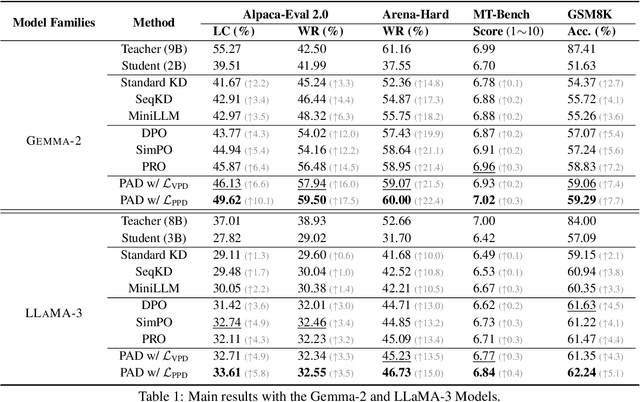
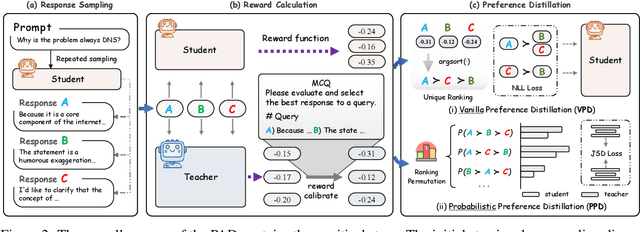
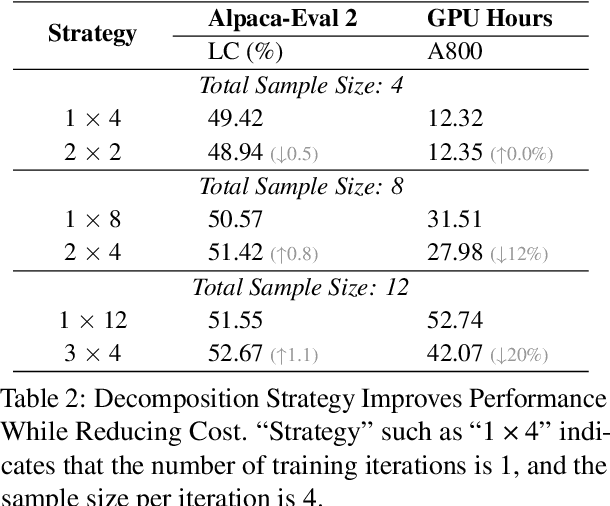
Aligning small language models (SLMs) with human values typically involves distilling preference knowledge from large language models (LLMs). However, existing distillation methods model preference knowledge in teacher LLMs by comparing pairwise responses, overlooking the extent of difference between responses. This limitation hinders student SLMs from capturing the nuanced preferences for multiple responses. In this paper, we propose a Preference-Aligned Distillation (PAD) framework, which models teacher's preference knowledge as a probability distribution over all potential preferences, thereby providing more nuanced supervisory signals. Our insight in developing PAD is rooted in the demonstration that language models can serve as reward functions, reflecting their intrinsic preferences. Based on this, PAD comprises three key steps: (1) sampling diverse responses using high-temperature; (2) computing rewards for both teacher and student to construct their intrinsic preference; and (3) training the student's intrinsic preference distribution to align with the teacher's. Experiments on four mainstream alignment benchmarks demonstrate that PAD consistently and significantly outperforms existing approaches, achieving over 20\% improvement on AlpacaEval 2 and Arena-Hard, indicating superior alignment with human preferences. Notably, on MT-Bench, using the \textsc{Gemma} model family, the student trained by PAD surpasses its teacher, further validating the effectiveness of our PAD.
Explainable and Interpretable Multimodal Large Language Models: A Comprehensive Survey
Dec 03, 2024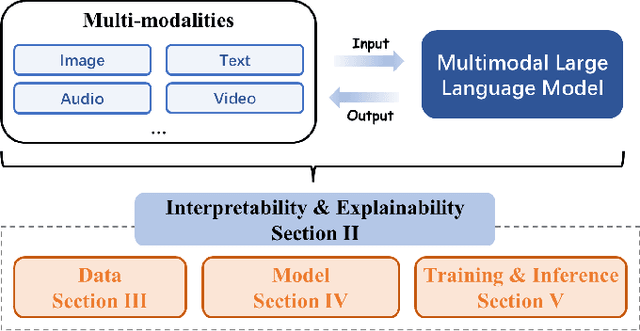
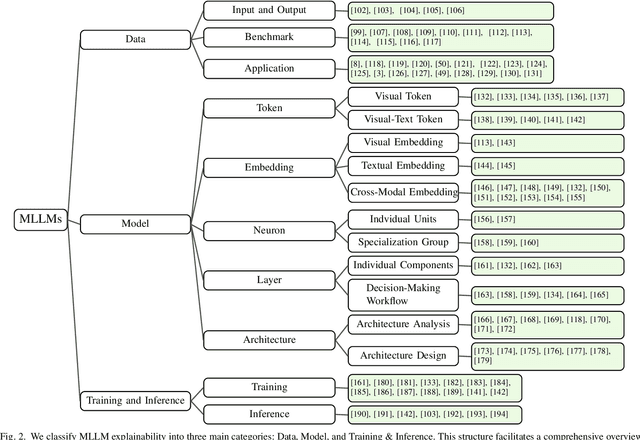
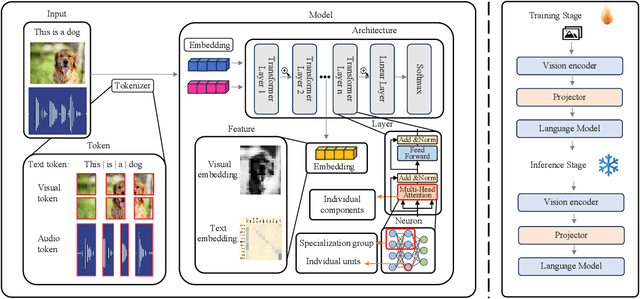
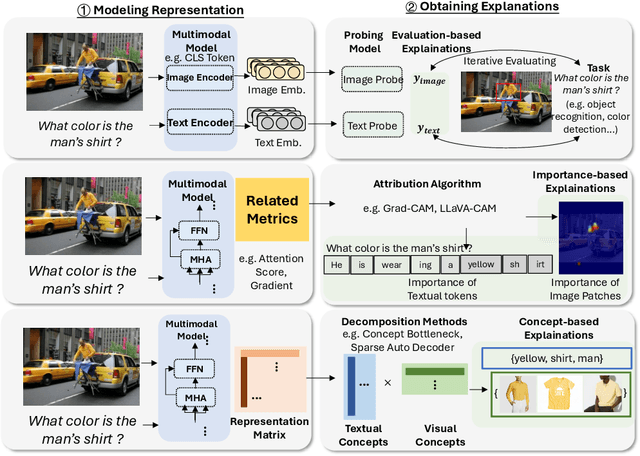
The rapid development of Artificial Intelligence (AI) has revolutionized numerous fields, with large language models (LLMs) and computer vision (CV) systems driving advancements in natural language understanding and visual processing, respectively. The convergence of these technologies has catalyzed the rise of multimodal AI, enabling richer, cross-modal understanding that spans text, vision, audio, and video modalities. Multimodal large language models (MLLMs), in particular, have emerged as a powerful framework, demonstrating impressive capabilities in tasks like image-text generation, visual question answering, and cross-modal retrieval. Despite these advancements, the complexity and scale of MLLMs introduce significant challenges in interpretability and explainability, essential for establishing transparency, trustworthiness, and reliability in high-stakes applications. This paper provides a comprehensive survey on the interpretability and explainability of MLLMs, proposing a novel framework that categorizes existing research across three perspectives: (I) Data, (II) Model, (III) Training \& Inference. We systematically analyze interpretability from token-level to embedding-level representations, assess approaches related to both architecture analysis and design, and explore training and inference strategies that enhance transparency. By comparing various methodologies, we identify their strengths and limitations and propose future research directions to address unresolved challenges in multimodal explainability. This survey offers a foundational resource for advancing interpretability and transparency in MLLMs, guiding researchers and practitioners toward developing more accountable and robust multimodal AI systems.
Look Twice Before You Answer: Memory-Space Visual Retracing for Hallucination Mitigation in Multimodal Large Language Models
Oct 04, 2024
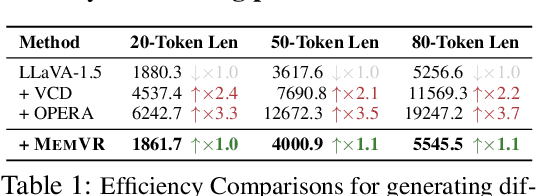
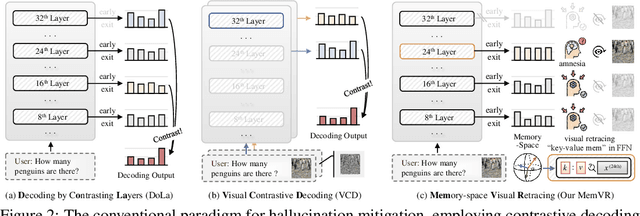
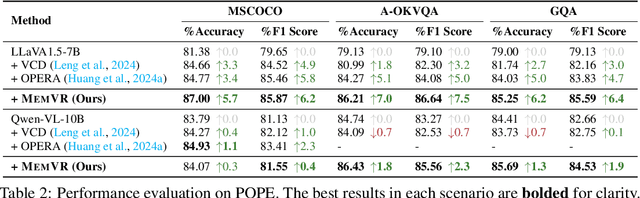
Despite their impressive capabilities, Multimodal Large Language Models (MLLMs) are susceptible to hallucinations, especially assertively fabricating content not present in the visual inputs. To address the aforementioned challenge, we follow a common cognitive process - when one's initial memory of critical on-sight details fades, it is intuitive to look at them a second time to seek a factual and accurate answer. Therefore, we introduce Memory-space Visual Retracing (MemVR), a novel hallucination mitigation paradigm that without the need for external knowledge retrieval or additional fine-tuning. In particular, we treat visual prompts as supplementary evidence to be reinjected into MLLMs via Feed Forward Network (FFN) as key-value memory, when the model is uncertain or even amnesic about question-relevant visual memories. Comprehensive experimental evaluations demonstrate that MemVR significantly mitigates hallucination issues across various MLLMs and excels in general benchmarks without incurring added time overhead, thus emphasizing its potential for widespread applicability.
LATEX-GCL: Large Language Models (LLMs)-Based Data Augmentation for Text-Attributed Graph Contrastive Learning
Sep 02, 2024



Graph Contrastive Learning (GCL) is a potent paradigm for self-supervised graph learning that has attracted attention across various application scenarios. However, GCL for learning on Text-Attributed Graphs (TAGs) has yet to be explored. Because conventional augmentation techniques like feature embedding masking cannot directly process textual attributes on TAGs. A naive strategy for applying GCL to TAGs is to encode the textual attributes into feature embeddings via a language model and then feed the embeddings into the following GCL module for processing. Such a strategy faces three key challenges: I) failure to avoid information loss, II) semantic loss during the text encoding phase, and III) implicit augmentation constraints that lead to uncontrollable and incomprehensible results. In this paper, we propose a novel GCL framework named LATEX-GCL to utilize Large Language Models (LLMs) to produce textual augmentations and LLMs' powerful natural language processing (NLP) abilities to address the three limitations aforementioned to pave the way for applying GCL to TAG tasks. Extensive experiments on four high-quality TAG datasets illustrate the superiority of the proposed LATEX-GCL method. The source codes and datasets are released to ease the reproducibility, which can be accessed via this link: https://anonymous.4open.science/r/LATEX-GCL-0712.
Reasoning Factual Knowledge in Structured Data with Large Language Models
Aug 22, 2024



Large language models (LLMs) have made remarkable progress in various natural language processing tasks as a benefit of their capability to comprehend and reason with factual knowledge. However, a significant amount of factual knowledge is stored in structured data, which possesses unique characteristics that differ from the unstructured texts used for pretraining. This difference can introduce imperceptible inference parameter deviations, posing challenges for LLMs in effectively utilizing and reasoning with structured data to accurately infer factual knowledge. To this end, we propose a benchmark named StructFact, to evaluate the structural reasoning capabilities of LLMs in inferring factual knowledge. StructFact comprises 8,340 factual questions encompassing various tasks, domains, timelines, and regions. This benchmark allows us to investigate the capability of LLMs across five factual tasks derived from the unique characteristics of structural facts. Extensive experiments on a set of LLMs with different training strategies reveal the limitations of current LLMs in inferring factual knowledge from structured data. We present this benchmark as a compass to navigate the strengths and weaknesses of LLMs in reasoning with structured data for knowledge-sensitive tasks, and to encourage advancements in related real-world applications. Please find our code at https://github.com/EganGu/StructFact.
Refiner: Restructure Retrieval Content Efficiently to Advance Question-Answering Capabilities
Jun 18, 2024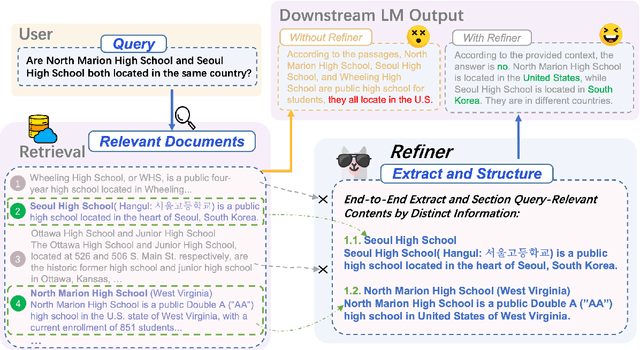

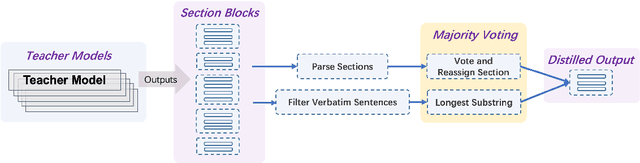

Large Language Models (LLMs) are limited by their parametric knowledge, leading to hallucinations in knowledge-extensive tasks. To address this, Retrieval-Augmented Generation (RAG) incorporates external document chunks to expand LLM knowledge. Furthermore, compressing information from document chunks through extraction or summarization can improve LLM performance. Nonetheless, LLMs still struggle to notice and utilize scattered key information, a problem known as the "lost-in-the-middle" syndrome. Therefore, we typically need to restructure the content for LLM to recognize the key information. We propose $\textit{Refiner}$, an end-to-end extract-and-restructure paradigm that operates in the post-retrieval process of RAG. $\textit{Refiner}$ leverages a single decoder-only LLM to adaptively extract query-relevant contents verbatim along with the necessary context, and section them based on their interconnectedness, thereby highlights information distinction, and aligns downstream LLMs with the original context effectively. Experiments show that a trained $\textit{Refiner}$ (with 7B parameters) exhibits significant gain to downstream LLM in improving answer accuracy, and outperforms other state-of-the-art advanced RAG and concurrent compressing approaches in various single-hop and multi-hop QA tasks. Notably, $\textit{Refiner}$ achieves a 80.5% tokens reduction and a 1.6-7.0% improvement margin in multi-hop tasks compared to the next best solution. $\textit{Refiner}$ is a plug-and-play solution that can be seamlessly integrated with RAG systems, facilitating its application across diverse open-source frameworks.