 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable and Interpretable Multimodal Large Language Models: A Comprehensive Survey
Dec 03, 2024
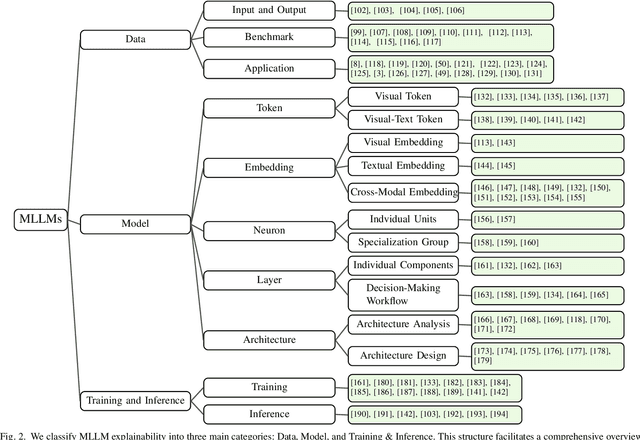
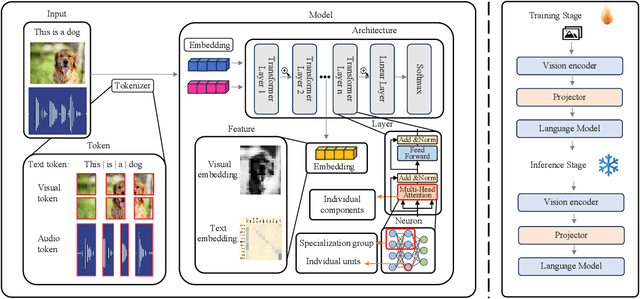
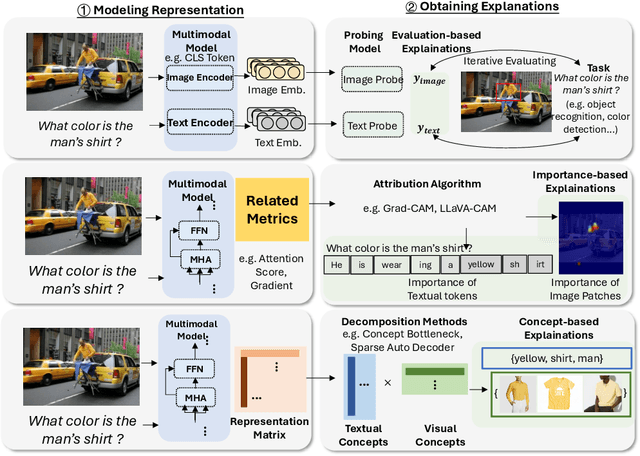
The rapid development of Artificial Intelligence (AI) has revolutionized numerous fields, with large language models (LLMs) and computer vision (CV) systems driving advancements in natural language understanding and visual processing, respectively. The convergence of these technologies has catalyzed the rise of multimodal AI, enabling richer, cross-modal understanding that spans text, vision, audio, and video modalities. Multimodal large language models (MLLMs), in particular, have emerged as a powerful framework, demonstrating impressive capabilities in tasks like image-text generation, visual question answering, and cross-modal retrieval. Despite these advancements, the complexity and scale of MLLMs introduce significant challenges in interpretability and explainability, essential for establishing transparency, trustworthiness, and reliability in high-stakes applications. This paper provides a comprehensive survey on the interpretability and explainability of MLLMs, proposing a novel framework that categorizes existing research across three perspectives: (I) Data, (II) Model, (III) Training \& Inference. We systematically analyze interpretability from token-level to embedding-level representations, assess approaches related to both architecture analysis and design, and explore training and inference strategies that enhance transparency. By comparing various methodologies, we identify their strengths and limitations and propose future research directions to address unresolved challenges in multimodal explainability. This survey offers a foundational resource for advancing interpretability and transparency in MLLMs, guiding researchers and practitioners toward developing more accountable and robust multimodal AI systems.
Exploring Response Uncertainty in MLLMs: An Empirical Evaluation under Misleading Scenarios
Nov 05, 2024



Ensuring that Multimodal Large Language Models (MLLMs) maintain consistency in their responses is essential for developing trustworthy multimodal intelligence. However, existing benchmarks include many samples where all MLLMs \textit{exhibit high response uncertainty when encountering misleading information}, requiring even 5-15 response attempts per sample to effectively assess uncertainty. Therefore, we propose a two-stage pipeline: first, we collect MLLMs' responses without misleading information, and then gather misleading ones via specific misleading instructions. By calculating the misleading rate, and capturing both correct-to-incorrect and incorrect-to-correct shifts between the two sets of responses, we can effectively metric the model's response uncertainty. Eventually, we establish a \textbf{\underline{M}}ultimodal \textbf{\underline{U}}ncertainty \textbf{\underline{B}}enchmark (\textbf{MUB}) that employs both explicit and implicit misleading instructions to comprehensively assess the vulnerability of MLLMs across diverse domains. Our experiments reveal that all open-source and close-source MLLMs are highly susceptible to misleading instructions, with an average misleading rate exceeding 86\%. To enhance the robustness of MLLMs, we further fine-tune all open-source MLLMs by incorporating explicit and implicit misleading data, which demonstrates a significant reduction in misleading rates. Our code is available at: \href{https://github.com/Yunkai696/MUB}{https://github.com/Yunkai696/MUB}
R3D-SWIN:Use Shifted Window Attention for Single-View 3D Reconstruction
Dec 09, 2023



Recently, vision transformers have performed well in various computer vision tasks, including voxel 3D reconstruction. However, the windows of the vision transformer are not multi-scale, and there is no connection between the windows, which limits the accuracy of voxel 3D reconstruction. Therefore, we propose a voxel 3D reconstruction network based on shifted window attention. To the best of our knowledge, this is the first work to apply shifted window attention to voxel 3D reconstruction. Experimental results on ShapeNet verify our method achieves SOTA accuracy in single-view reconstruction.