 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiFPO: Implicit Model Fusion via Preference Optimization in Large Language Models
May 20, 2025Model fusion combines multiple Large Language Models (LLMs) with different strengths into a more powerful, integrated model through lightweight training methods. Existing works on model fusion focus primarily on supervised fine-tuning (SFT), leaving preference alignment (PA) --a critical phase for enhancing LLM performance--largely unexplored. The current few fusion methods on PA phase, like WRPO, simplify the process by utilizing only response outputs from source models while discarding their probability information. To address this limitation, we propose InfiFPO, a preference optimization method for implicit model fusion. InfiFPO replaces the reference model in Direct Preference Optimization (DPO) with a fused source model that synthesizes multi-source probabilities at the sequence level, circumventing complex vocabulary alignment challenges in previous works and meanwhile maintaining the probability information. By introducing probability clipping and max-margin fusion strategies, InfiFPO enables the pivot model to align with human preferences while effectively distilling knowledge from source models. Comprehensive experiments on 11 widely-used benchmarks demonstrate that InfiFPO consistently outperforms existing model fusion and preference optimization methods. When using Phi-4 as the pivot model, InfiFPO improve its average performance from 79.95 to 83.33 on 11 benchmarks, significantly improving its capabilities in mathematics, coding, and reasoning tasks.
InfiGFusion: Graph-on-Logits Distillation via Efficient Gromov-Wasserstein for Model Fusion
May 20, 2025



Recent advances in large language models (LLMs) have intensified efforts to fuse heterogeneous open-source models into a unified system that inherits their complementary strengths. Existing logit-based fusion methods maintain inference efficiency but treat vocabulary dimensions independently, overlooking semantic dependencies encoded by cross-dimension interactions. These dependencies reflect how token types interact under a model's internal reasoning and are essential for aligning models with diverse generation behaviors. To explicitly model these dependencies, we propose \textbf{InfiGFusion}, the first structure-aware fusion framework with a novel \textit{Graph-on-Logits Distillation} (GLD) loss. Specifically, we retain the top-$k$ logits per output and aggregate their outer products across sequence positions to form a global co-activation graph, where nodes represent vocabulary channels and edges quantify their joint activations. To ensure scalability and efficiency, we design a sorting-based closed-form approximation that reduces the original $O(n^4)$ cost of Gromov-Wasserstein distance to $O(n \log n)$, with provable approximation guarantees. Experiments across multiple fusion settings show that GLD consistently improves fusion quality and stability. InfiGFusion outperforms SOTA models and fusion baselines across 11 benchmarks spanning reasoning, coding, and mathematics. It shows particular strength in complex reasoning tasks, with +35.6 improvement on Multistep Arithmetic and +37.06 on Causal Judgement over SFT, demonstrating superior multi-step and relational inference.
HyperG: Hypergraph-Enhanced LLMs for Structured Knowledge
Feb 25, 2025Given that substantial amounts of domain-specific knowledge are stored in structured formats, such as web data organized through HTML, Large Language Models (LLMs) are expected to fully comprehend this structured information to broaden their applications in various real-world downstream tasks. Current approaches for applying LLMs to structured data fall into two main categories: serialization-based and operation-based methods. Both approaches, whether relying on serialization or using SQL-like operations as an intermediary, encounter difficulties in fully capturing structural relationships and effectively handling sparse data. To address these unique characteristics of structured data, we propose HyperG, a hypergraph-based generation framework aimed at enhancing LLMs' ability to process structured knowledge. Specifically, HyperG first augment sparse data with contextual information, leveraging the generative power of LLMs, and incorporate a prompt-attentive hypergraph learning (PHL) network to encode both the augmented information and the intricate structural relationships within the data. To validate the effectiveness and generalization of HyperG, we conduct extensive experiments across two different downstream tasks requiring structured knowledge.
Capturing Nuanced Preferences: Preference-Aligned Distillation for Small Language Models
Feb 20, 2025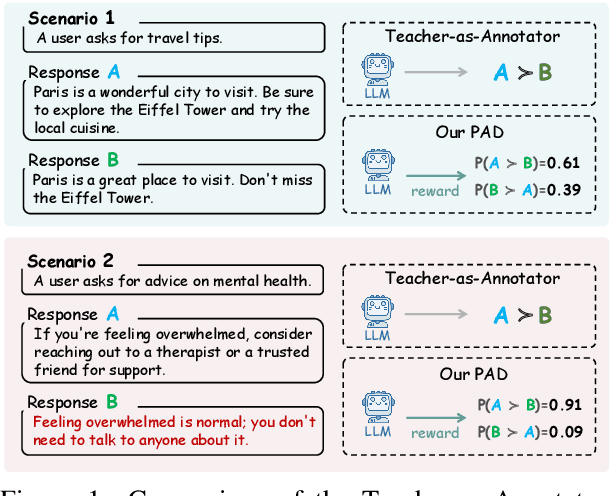
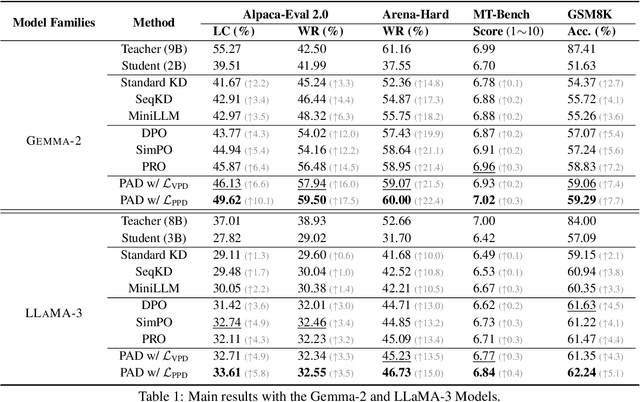
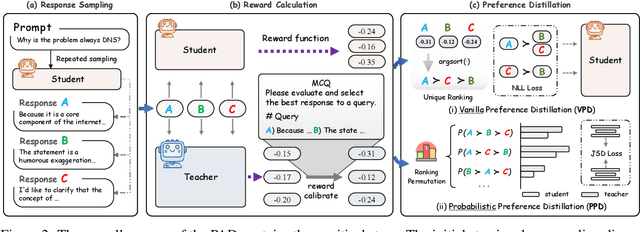
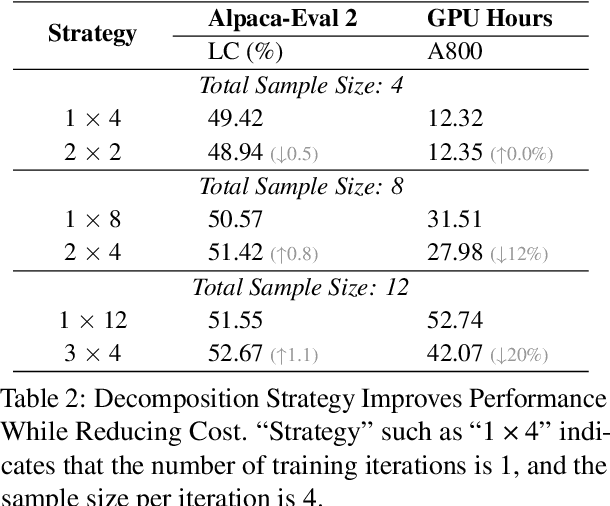
Aligning small language models (SLMs) with human values typically involves distilling preference knowledge from large language models (LLMs). However, existing distillation methods model preference knowledge in teacher LLMs by comparing pairwise responses, overlooking the extent of difference between responses. This limitation hinders student SLMs from capturing the nuanced preferences for multiple responses. In this paper, we propose a Preference-Aligned Distillation (PAD) framework, which models teacher's preference knowledge as a probability distribution over all potential preferences, thereby providing more nuanced supervisory signals. Our insight in developing PAD is rooted in the demonstration that language models can serve as reward functions, reflecting their intrinsic preferences. Based on this, PAD comprises three key steps: (1) sampling diverse responses using high-temperature; (2) computing rewards for both teacher and student to construct their intrinsic preference; and (3) training the student's intrinsic preference distribution to align with the teacher's. Experiments on four mainstream alignment benchmarks demonstrate that PAD consistently and significantly outperforms existing approaches, achieving over 20\% improvement on AlpacaEval 2 and Arena-Hard, indicating superior alignment with human preferences. Notably, on MT-Bench, using the \textsc{Gemma} model family, the student trained by PAD surpasses its teacher, further validating the effectiveness of our PAD.
Exploring Response Uncertainty in MLLMs: An Empirical Evaluation under Misleading Scenarios
Nov 05, 2024



Ensuring that Multimodal Large Language Models (MLLMs) maintain consistency in their responses is essential for developing trustworthy multimodal intelligence. However, existing benchmarks include many samples where all MLLMs \textit{exhibit high response uncertainty when encountering misleading information}, requiring even 5-15 response attempts per sample to effectively assess uncertainty. Therefore, we propose a two-stage pipeline: first, we collect MLLMs' responses without misleading information, and then gather misleading ones via specific misleading instructions. By calculating the misleading rate, and capturing both correct-to-incorrect and incorrect-to-correct shifts between the two sets of responses, we can effectively metric the model's response uncertainty. Eventually, we establish a \textbf{\underline{M}}ultimodal \textbf{\underline{U}}ncertainty \textbf{\underline{B}}enchmark (\textbf{MUB}) that employs both explicit and implicit misleading instructions to comprehensively assess the vulnerability of MLLMs across diverse domains. Our experiments reveal that all open-source and close-source MLLMs are highly susceptible to misleading instructions, with an average misleading rate exceeding 86\%. To enhance the robustness of MLLMs, we further fine-tune all open-source MLLMs by incorporating explicit and implicit misleading data, which demonstrates a significant reduction in misleading rates. Our code is available at: \href{https://github.com/Yunkai696/MUB}{https://github.com/Yunkai696/MUB}
Reasoning Factual Knowledge in Structured Data with Large Language Models
Aug 22, 2024



Large language models (LLMs) have made remarkable progress in various natural language processing tasks as a benefit of their capability to comprehend and reason with factual knowledge. However, a significant amount of factual knowledge is stored in structured data, which possesses unique characteristics that differ from the unstructured texts used for pretraining. This difference can introduce imperceptible inference parameter deviations, posing challenges for LLMs in effectively utilizing and reasoning with structured data to accurately infer factual knowledge. To this end, we propose a benchmark named StructFact, to evaluate the structural reasoning capabilities of LLMs in inferring factual knowledge. StructFact comprises 8,340 factual questions encompassing various tasks, domains, timelines, and regions. This benchmark allows us to investigate the capability of LLMs across five factual tasks derived from the unique characteristics of structural facts. Extensive experiments on a set of LLMs with different training strategies reveal the limitations of current LLMs in inferring factual knowledge from structured data. We present this benchmark as a compass to navigate the strengths and weaknesses of LLMs in reasoning with structured data for knowledge-sensitive tasks, and to encourage advancements in related real-world applications. Please find our code at https://github.com/EganGu/StructFact.