 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFUSE-RSVLM: Feature Fusion Vision-Language Model for Remote Sensing
Dec 30, 2025Large vision-language models (VLMs) exhibit strong performance across various tasks. However, these VLMs encounter significant challenges when applied to the remote sensing domain due to the inherent differences between remote sensing images and natural images. Existing remote sensing VLMs often fail to extract fine-grained visual features and suffer from visual forgetting during deep language processing. To address this, we introduce MF-RSVLM, a Multi-Feature Fusion Remote Sensing Vision--Language Model that effectively extracts and fuses visual features for RS understanding. MF-RSVLM learns multi-scale visual representations and combines global context with local details, improving the capture of small and complex structures in RS scenes. A recurrent visual feature injection scheme ensures the language model remains grounded in visual evidence and reduces visual forgetting during generation. Extensive experiments on diverse RS benchmarks show that MF-RSVLM achieves state-of-the-art or highly competitive performance across remote sensing classification, image captioning, and VQA tasks. Our code is publicly available at https://github.com/Yunkaidang/RSVLM.
A Benchmark for Ultra-High-Resolution Remote Sensing MLLMs
Dec 19, 2025Multimodal large language models (MLLMs) demonstrate strong perception and reasoning performance on existing remote sensing (RS) benchmarks. However, most prior benchmarks rely on low-resolution imagery, and some high-resolution benchmarks suffer from flawed reasoning-task designs. We show that text-only LLMs can perform competitively with multimodal vision-language models on RS reasoning tasks without access to images, revealing a critical mismatch between current benchmarks and the intended evaluation of visual understanding. To enable faithful assessment, we introduce RSHR-Bench, a super-high-resolution benchmark for RS visual understanding and reasoning. RSHR-Bench contains 5,329 full-scene images with a long side of at least 4,000 pixels, with up to about 3 x 10^8 pixels per image, sourced from widely used RS corpora and UAV collections. We design four task families: multiple-choice VQA, open-ended VQA, image captioning, and single-image evaluation. These tasks cover nine perception categories and four reasoning types, supporting multi-turn and multi-image dialog. To reduce reliance on language priors, we apply adversarial filtering with strong LLMs followed by rigorous human verification. Overall, we construct 3,864 VQA tasks, 3,913 image captioning tasks, and 500 fully human-written or verified single-image evaluation VQA pairs. Evaluations across open-source, closed-source, and RS-specific VLMs reveal persistent performance gaps in super-high-resolution scenarios. Code: https://github.com/Yunkaidang/RSHR
Multi-Level Correlation Network For Few-Shot Image Classification
Dec 04, 2024



Few-shot image classification(FSIC) aims to recognize novel classes given few labeled images from base classes. Recent works have achieved promising classification performance, especially for metric-learning methods, where a measure at only image feature level is usually used. In this paper, we argue that measure at such a level may not be effective enough to generalize from base to novel classes when using only a few images. Instead, a multi-level descriptor of an image is taken for consideration in this paper. We propose a multi-level correlation network (MLCN) for FSIC to tackle this problem by effectively capturing local information. Concretely, we present the self-correlation module and cross-correlation module to learn the semantic correspondence relation of local information based on learned representations. Moreover, we propose a pattern-correlation module to capture the pattern of fine-grained images and find relevant structural patterns between base classes and novel classes. Extensive experiments and analysis show the effectiveness of our proposed method on four widely-used FSIC benchmarks. The code for our approach is available at: https://github.com/Yunkai696/MLCN.
Explainable and Interpretable Multimodal Large Language Models: A Comprehensive Survey
Dec 03, 2024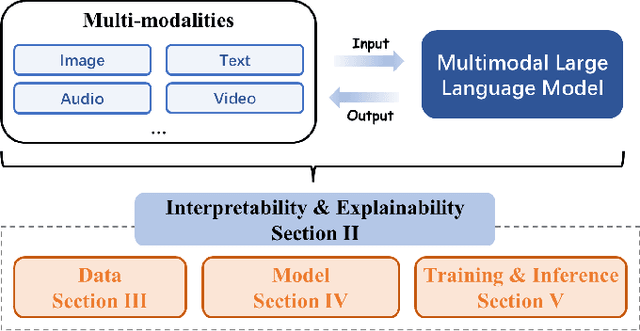
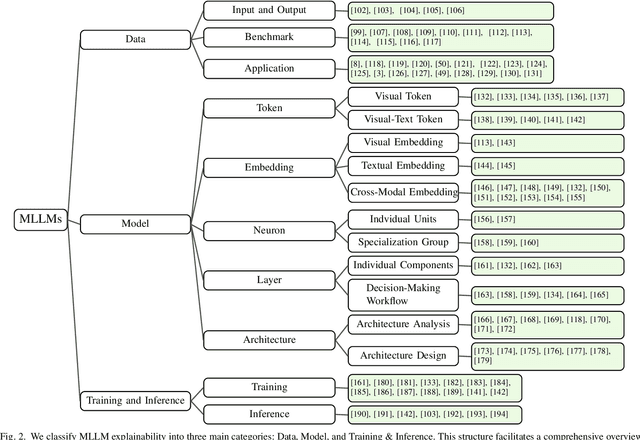
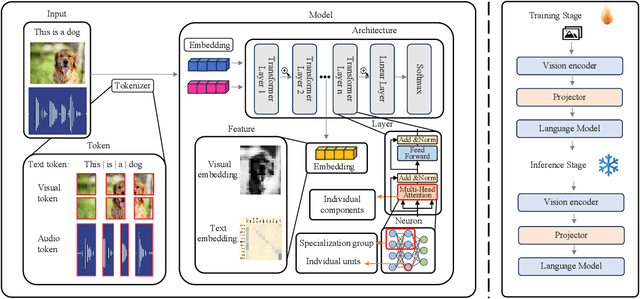
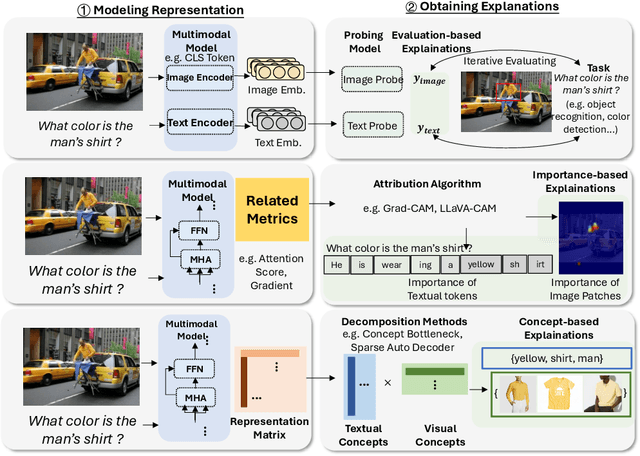
The rapid development of Artificial Intelligence (AI) has revolutionized numerous fields, with large language models (LLMs) and computer vision (CV) systems driving advancements in natural language understanding and visual processing, respectively. The convergence of these technologies has catalyzed the rise of multimodal AI, enabling richer, cross-modal understanding that spans text, vision, audio, and video modalities. Multimodal large language models (MLLMs), in particular, have emerged as a powerful framework, demonstrating impressive capabilities in tasks like image-text generation, visual question answering, and cross-modal retrieval. Despite these advancements, the complexity and scale of MLLMs introduce significant challenges in interpretability and explainability, essential for establishing transparency, trustworthiness, and reliability in high-stakes applications. This paper provides a comprehensive survey on the interpretability and explainability of MLLMs, proposing a novel framework that categorizes existing research across three perspectives: (I) Data, (II) Model, (III) Training \& Inference. We systematically analyze interpretability from token-level to embedding-level representations, assess approaches related to both architecture analysis and design, and explore training and inference strategies that enhance transparency. By comparing various methodologies, we identify their strengths and limitations and propose future research directions to address unresolved challenges in multimodal explainability. This survey offers a foundational resource for advancing interpretability and transparency in MLLMs, guiding researchers and practitioners toward developing more accountable and robust multimodal AI systems.
Exploring Response Uncertainty in MLLMs: An Empirical Evaluation under Misleading Scenarios
Nov 05, 2024



Ensuring that Multimodal Large Language Models (MLLMs) maintain consistency in their responses is essential for developing trustworthy multimodal intelligence. However, existing benchmarks include many samples where all MLLMs \textit{exhibit high response uncertainty when encountering misleading information}, requiring even 5-15 response attempts per sample to effectively assess uncertainty. Therefore, we propose a two-stage pipeline: first, we collect MLLMs' responses without misleading information, and then gather misleading ones via specific misleading instructions. By calculating the misleading rate, and capturing both correct-to-incorrect and incorrect-to-correct shifts between the two sets of responses, we can effectively metric the model's response uncertainty. Eventually, we establish a \textbf{\underline{M}}ultimodal \textbf{\underline{U}}ncertainty \textbf{\underline{B}}enchmark (\textbf{MUB}) that employs both explicit and implicit misleading instructions to comprehensively assess the vulnerability of MLLMs across diverse domains. Our experiments reveal that all open-source and close-source MLLMs are highly susceptible to misleading instructions, with an average misleading rate exceeding 86\%. To enhance the robustness of MLLMs, we further fine-tune all open-source MLLMs by incorporating explicit and implicit misleading data, which demonstrates a significant reduction in misleading rates. Our code is available at: \href{https://github.com/Yunkai696/MUB}{https://github.com/Yunkai696/MUB}
RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness
May 27, 2024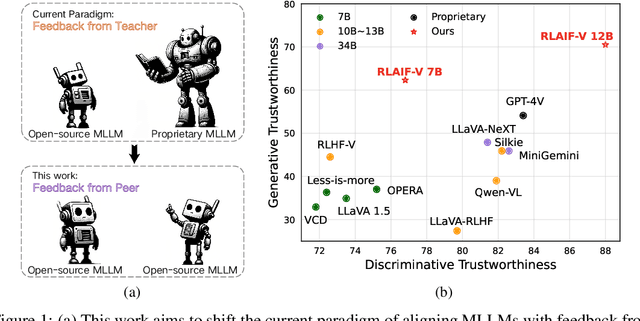
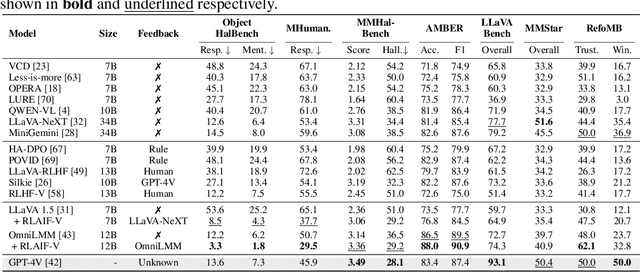
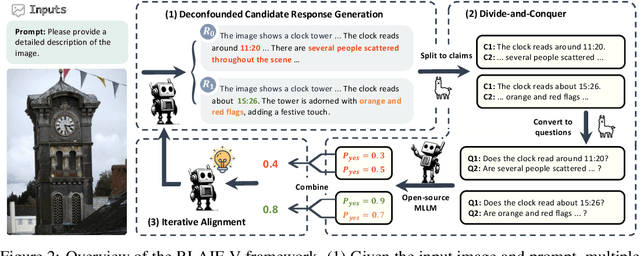
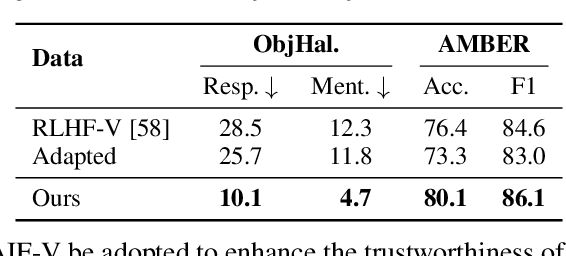
Learning from feedback reduces the hallucination of multimodal large language models (MLLMs) by aligning them with human preferences. While traditional methods rely on labor-intensive and time-consuming manual labeling, recent approaches employing models as automatic labelers have shown promising results without human intervention. However, these methods heavily rely on costly proprietary models like GPT-4V, resulting in scalability issues. Moreover, this paradigm essentially distills the proprietary models to provide a temporary solution to quickly bridge the performance gap. As this gap continues to shrink, the community is soon facing the essential challenge of aligning MLLMs using labeler models of comparable capability. In this work, we introduce RLAIF-V, a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. RLAIF-V maximally exploits the open-source feedback from two perspectives, including high-quality feedback data and online feedback learning algorithm. Extensive experiments on seven benchmarks in both automatic and human evaluation show that RLAIF-V substantially enhances the trustworthiness of models without sacrificing performance on other tasks. Using a 34B model as labeler, RLAIF-V 7B model reduces object hallucination by 82.9\% and overall hallucination by 42.1\%, outperforming the labeler model. Remarkably, RLAIF-V also reveals the self-alignment potential of open-source MLLMs, where a 12B model can learn from the feedback of itself to achieve less than 29.5\% overall hallucination rate, surpassing GPT-4V (45.9\%) by a large margin. The results shed light on a promising route to enhance the efficacy of leading-edge MLLMs.
FILM: How can Few-Shot Image Classification Benefit from Pre-Trained Language Models?
Jul 09, 2023
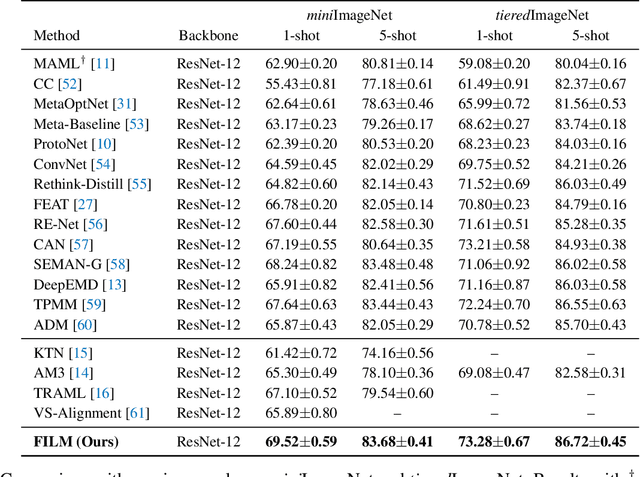


Few-shot learning aims to train models that can be generalized to novel classes with only a few samples. Recently, a line of works are proposed to enhance few-shot learning with accessible semantic information from class names. However, these works focus on improving existing modules such as visual prototypes and feature extractors of the standard few-shot learning framework. This limits the full potential use of semantic information. In this paper, we propose a novel few-shot learning framework that uses pre-trained language models based on contrastive learning. To address the challenge of alignment between visual features and textual embeddings obtained from text-based pre-trained language model, we carefully design the textual branch of our framework and introduce a metric module to generalize the cosine similarity. For better transferability, we let the metric module adapt to different few-shot tasks and adopt MAML to train the model via bi-level optimization. Moreover, we conduct extensive experiments on multiple benchmarks to demonstrate the effectiveness of our method.