 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADA: Region-Aware Dual-encoder Auxiliary learning for Barely-supervised Medical Image Segmentation
Apr 13, 2026Deep learning has greatly advanced medical image segmentation, but its success relies heavily on fully supervised learning, which requires dense annotations that are costly and time-consuming for 3D volumetric scans. Barely-supervised learning reduces annotation burden by using only a few labeled slices per volume. Existing methods typically propagate sparse annotations to unlabeled slices through geometric continuity to generate pseudo-labels, but this strategy lacks semantic understanding, often resulting in low-quality pseudo-labels. Furthermore, medical image segmentation is inherently a pixel-level visual understanding task, where accuracy fundamentally depends on the quality of local, fine-grained visual features. Inspired by this, we propose RADA, a novel Region-Aware Dual-encoder Auxiliary learning pipeline which introduces a dual-encoder framework pre-trained on Alpha-CLIP to extract fine-grained, region-specific visual features from the original images and limited annotations. The framework combines image-level fine-grained visual features with text-level semantic guidance, providing region-aware semantic supervision that bridges image-level semantics and pixel-level segmentation. Integrated into a triple-view training framework, RADA achieves SOTA performance under extremely sparse annotation settings on LA2018, KiTS19 and LiTS, demonstrating robust generalization across diverse datasets.
Geometry-as-context: Modulating Explicit 3D in Scene-consistent Video Generation to Geometry Context
Feb 25, 2026Scene-consistent video generation aims to create videos that explore 3D scenes based on a camera trajectory. Previous methods rely on video generation models with external memory for consistency, or iterative 3D reconstruction and inpainting, which accumulate errors during inference due to incorrect intermediary outputs, non-differentiable processes, and separate models. To overcome these limitations, we introduce ``geometry-as-context". It iteratively completes the following steps using an autoregressive camera-controlled video generation model: (1) estimates the geometry of the current view necessary for 3D reconstruction, and (2) simulates and restores novel view images rendered by the 3D scene. Under this multi-task framework, we develop the camera gated attention module to enhance the model's capability to effectively leverage camera poses. During the training phase, text contexts are utilized to ascertain whether geometric or RGB images should be generated. To ensure that the model can generate RGB-only outputs during inference, the geometry context is randomly dropped from the interleaved text-image-geometry training sequence. The method has been tested on scene video generation with one-direction and forth-and-back trajectories. The results show its superiority over previous approaches in maintaining scene consistency and camera control.
Bridging Information Asymmetry: A Hierarchical Framework for Deterministic Blind Face Restoration
Jan 27, 2026Blind face restoration remains a persistent challenge due to the inherent ill-posedness of reconstructing holistic structures from severely constrained observations. Current generative approaches, while capable of synthesizing realistic textures, often suffer from information asymmetry -- the intrinsic disparity between the information-sparse low quality inputs and the information-dense high quality outputs. This imbalance leads to a one-to-many mapping, where insufficient constraints result in stochastic uncertainty and hallucinatory artifacts. To bridge this gap, we present \textbf{Pref-Restore}, a hierarchical framework that integrates discrete semantic logic with continuous texture generation to achieve deterministic, preference-aligned restoration. Our methodology fundamentally addresses this information disparity through two complementary strategies: (1) Augmenting Input Density: We employ an auto-regressive integrator to reformulate textual instructions into dense latent queries, injecting high-level semantic stability to constrain the degraded signals; (2) Pruning Output Distribution: We pioneer the integration of on-policy reinforcement learning directly into the diffusion restoration loop. By transforming human preferences into differentiable constraints, we explicitly penalize stochastic deviations, thereby sharpening the posterior distribution toward the desired high-fidelity outcomes. Extensive experiments demonstrate that Pref-Restore achieves state-of-the-art performance across synthetic and real-world benchmarks. Furthermore, empirical analysis confirms that our preference-aligned strategy significantly reduces solution entropy, establishing a robust pathway toward reliable and deterministic blind restoration.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
AdaTok: Adaptive Token Compression with Object-Aware Representations for Efficient Multimodal LLMs
Nov 18, 2025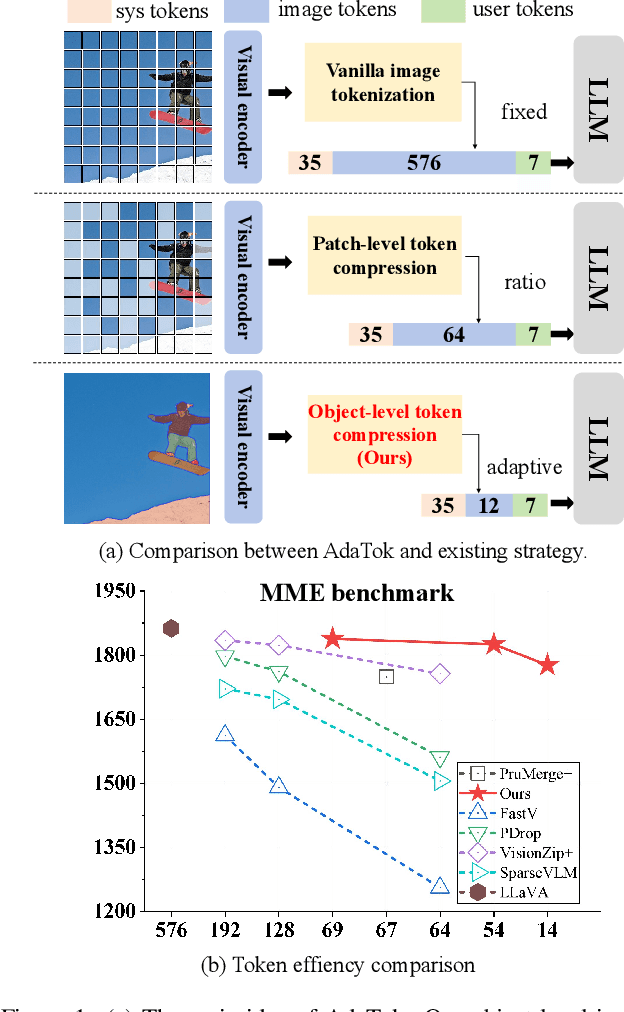
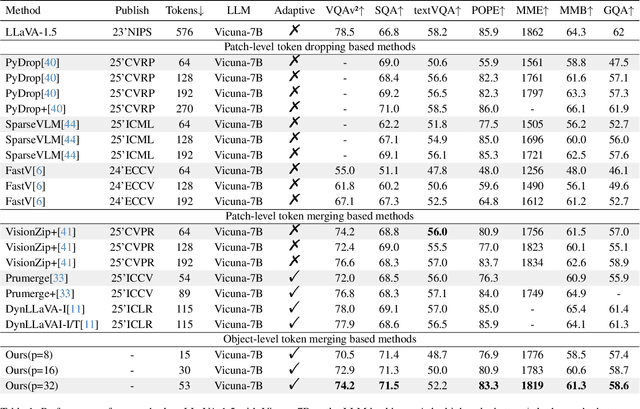
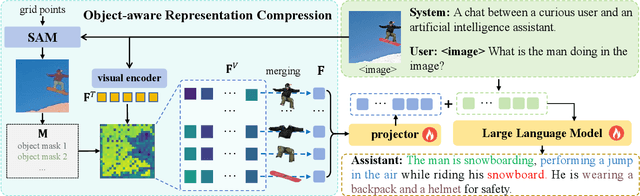
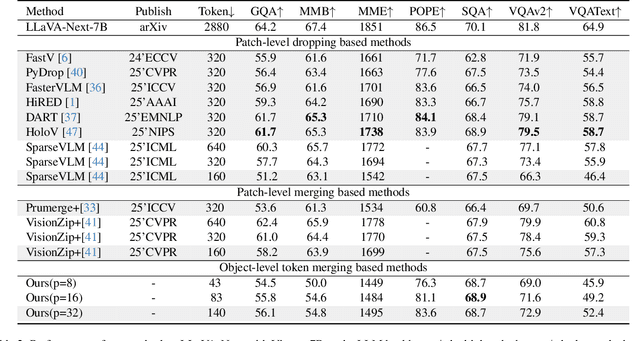
Multimodal Large Language Models (MLLMs) have demonstrated substantial value in unified text-image understanding and reasoning, primarily by converting images into sequences of patch-level tokens that align with their architectural paradigm. However, patch-level tokenization leads to a quadratic growth in image tokens, burdening MLLMs' understanding and reasoning with enormous computation and memory. Additionally, the traditional patch-wise scanning tokenization workflow misaligns with the human vision cognition system, further leading to hallucination and computational redundancy. To address this issue, we propose an object-level token merging strategy for Adaptive Token compression, revealing the consistency with human vision system. The experiments are conducted on multiple comprehensive benchmarks, which show that our approach averagely, utilizes only 10% tokens while achieving almost 96% of the vanilla model's performance. More extensive experimental results in comparison with relevant works demonstrate the superiority of our method in balancing compression ratio and performance. Our code will be available.
Novel Extraction of Discriminative Fine-Grained Feature to Improve Retinal Vessel Segmentation
May 06, 2025Retinal vessel segmentation is a vital early detection method for several severe ocular diseases. Despite significant progress in retinal vessel segmentation with the advancement of Neural Networks, there are still challenges to overcome. Specifically, retinal vessel segmentation aims to predict the class label for every pixel within a fundus image, with a primary focus on intra-image discrimination, making it vital for models to extract more discriminative features. Nevertheless, existing methods primarily focus on minimizing the difference between the output from the decoder and the label, but ignore fully using feature-level fine-grained representations from the encoder. To address these issues, we propose a novel Attention U-shaped Kolmogorov-Arnold Network named AttUKAN along with a novel Label-guided Pixel-wise Contrastive Loss for retinal vessel segmentation. Specifically, we implement Attention Gates into Kolmogorov-Arnold Networks to enhance model sensitivity by suppressing irrelevant feature activations and model interpretability by non-linear modeling of KAN blocks. Additionally, we also design a novel Label-guided Pixel-wise Contrastive Loss to supervise our proposed AttUKAN to extract more discriminative features by distinguishing between foreground vessel-pixel pairs and background pairs. Experiments are conducted across four public datasets including DRIVE, STARE, CHASE_DB1, HRF and our private dataset. AttUKAN achieves F1 scores of 82.50%, 81.14%, 81.34%, 80.21% and 80.09%, along with MIoU scores of 70.24%, 68.64%, 68.59%, 67.21% and 66.94% in the above datasets, which are the highest compared to 11 networks for retinal vessel segmentation. Quantitative and qualitative results show that our AttUKAN achieves state-of-the-art performance and outperforms existing retinal vessel segmentation methods. Our code will be available at https://github.com/stevezs315/AttUKAN.
SuperCL: Superpixel Guided Contrastive Learning for Medical Image Segmentation Pre-training
Apr 20, 2025Medical image segmentation is a critical yet challenging task, primarily due to the difficulty of obtaining extensive datasets of high-quality, expert-annotated images. Contrastive learning presents a potential but still problematic solution to this issue. Because most existing methods focus on extracting instance-level or pixel-to-pixel representation, which ignores the characteristics between intra-image similar pixel groups. Moreover, when considering contrastive pairs generation, most SOTA methods mainly rely on manually setting thresholds, which requires a large number of gradient experiments and lacks efficiency and generalization. To address these issues, we propose a novel contrastive learning approach named SuperCL for medical image segmentation pre-training. Specifically, our SuperCL exploits the structural prior and pixel correlation of images by introducing two novel contrastive pairs generation strategies: Intra-image Local Contrastive Pairs (ILCP) Generation and Inter-image Global Contrastive Pairs (IGCP) Generation. Considering superpixel cluster aligns well with the concept of contrastive pairs generation, we utilize the superpixel map to generate pseudo masks for both ILCP and IGCP to guide supervised contrastive learning. Moreover, we also propose two modules named Average SuperPixel Feature Map Generation (ASP) and Connected Components Label Generation (CCL) to better exploit the prior structural information for IGCP. Finally, experiments on 8 medical image datasets indicate our SuperCL outperforms existing 12 methods. i.e. Our SuperCL achieves a superior performance with more precise predictions from visualization figures and 3.15%, 5.44%, 7.89% DSC higher than the previous best results on MMWHS, CHAOS, Spleen with 10% annotations. Our code will be released after acceptance.
Exploiting Inherent Class Label: Towards Robust Scribble Supervised Semantic Segmentation
Mar 18, 2025Scribble-based weakly supervised semantic segmentation leverages only a few annotated pixels as labels to train a segmentation model, presenting significant potential for reducing the human labor involved in the annotation process. This approach faces two primary challenges: first, the sparsity of scribble annotations can lead to inconsistent predictions due to limited supervision; second, the variability in scribble annotations, reflecting differing human annotator preferences, can prevent the model from consistently capturing the discriminative regions of objects, potentially leading to unstable predictions. To address these issues, we propose a holistic framework, the class-driven scribble promotion network, for robust scribble-supervised semantic segmentation. This framework not only utilizes the provided scribble annotations but also leverages their associated class labels to generate reliable pseudo-labels. Within the network, we introduce a localization rectification module to mitigate noisy labels and a distance perception module to identify reliable regions surrounding scribble annotations and pseudo-labels. In addition, we introduce new large-scale benchmarks, ScribbleCOCO and ScribbleCityscapes, accompanied by a scribble simulation algorithm that enables evaluation across varying scribble styles. Our method demonstrates competitive performance in both accuracy and robustness, underscoring its superiority over existing approaches. The datasets and the codes will be made publicly available.
Interference-Aware Super-Constellation Design for NOMA
Mar 10, 2025Non-orthogonal multiple access (NOMA) has gained significant attention as a potential next-generation multiple access technique. However, its implementation with finite-alphabet inputs faces challenges. Particularly, due to inter-user interference, superimposed constellations may have overlapping symbols leading to high bit error rates when successive interference cancellation (SIC) is applied. To tackle the issue, this paper employs autoencoders to design interference-aware super-constellations. Unlike conventional methods where superimposed constellation may have overlapping symbols, the proposed autoencoder-based NOMA (AE-NOMA) is trained to design super-constellations with distinguishable symbols at receivers, regardless of channel gains. The proposed architecture removes the need for SIC, allowing maximum likelihood-based approaches to be used instead. The paper presents the conceptual architecture, loss functions, and training strategies for AE-NOMA. Various test results are provided to demonstrate the effectiveness of interference-aware constellations in improving the bit error rate, indicating the adaptability of AE-NOMA to different channel scenarios and its promising potential for implementing NOMA systems
V2C-CBM: Building Concept Bottlenecks with Vision-to-Concept Tokenizer
Jan 09, 2025


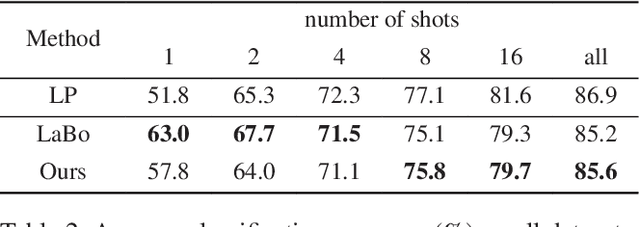
Concept Bottleneck Models (CBMs) offer inherent interpretability by initially translating images into human-comprehensible concepts, followed by a linear combination of these concepts for classification. However, the annotation of concepts for visual recognition tasks requires extensive expert knowledge and labor, constraining the broad adoption of CBMs. Recent approaches have leveraged the knowledge of large language models to construct concept bottlenecks, with multimodal models like CLIP subsequently mapping image features into the concept feature space for classification. Despite this, the concepts produced by language models can be verbose and may introduce non-visual attributes, which hurts accuracy and interpretability. In this study, we investigate to avoid these issues by constructing CBMs directly from multimodal models. To this end, we adopt common words as base concept vocabulary and leverage auxiliary unlabeled images to construct a Vision-to-Concept (V2C) tokenizer that can explicitly quantize images into their most relevant visual concepts, thus creating a vision-oriented concept bottleneck tightly coupled with the multimodal model. This leads to our V2C-CBM which is training efficient and interpretable with high accuracy. Our V2C-CBM has matched or outperformed LLM-supervised CBMs on various visual classification benchmarks, validating the efficacy of our approach.