 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Conditional Diffusion for Motion-Robust Retinal Temporal Laser Speckle Contrast Imaging
Apr 22, 2026Retinal laser speckle contrast imaging (LSCI) is a noninvasive optical modality for monitoring retinal blood flow dynamics. However, conventional temporal LSCI (tLSCI) reconstruction relies on sufficiently long speckle sequences to obtain stable temporal statistics, which makes it vulnerable to acquisition disturbances and limits effective temporal resolution. A physically informed reconstruction framework, termed RetinaDiff (Retinal Diffusion Model), is proposed for retinal tLSCI that is robust to motion and requires only a few frames. In RetinaDiff, registration based on phase correlation is first applied to stabilize the raw speckle sequence before contrast computation, reducing interframe misalignment so that fluctuations at each pixel primarily reflect true flow dynamics. This step provides a physics prior corrected for motion and a high quality multiframe tLSCI reference. Next, guided by the physics prior, a conditional diffusion model performs inverse reconstruction by jointly conditioning on the registered speckle sequence and the corrected prior. Experiments on data acquired with a retinal LSCI system developed in house show improved structural continuity and statistical stability compared with direct reconstruction from few frames and representative baselines. The framework also remains effective in a small number of extremely challenging cases, where both the direct 5-frame input and the conventional multiframe reconstruction are severely degraded. Overall, this work provides a practical and physically grounded route for reliable retinal tLSCI reconstruction from extremely limited frames. The source code and model weights will be publicly available at https://github.com/QianChen113/RetinaDiff.
Novel Extraction of Discriminative Fine-Grained Feature to Improve Retinal Vessel Segmentation
May 06, 2025Retinal vessel segmentation is a vital early detection method for several severe ocular diseases. Despite significant progress in retinal vessel segmentation with the advancement of Neural Networks, there are still challenges to overcome. Specifically, retinal vessel segmentation aims to predict the class label for every pixel within a fundus image, with a primary focus on intra-image discrimination, making it vital for models to extract more discriminative features. Nevertheless, existing methods primarily focus on minimizing the difference between the output from the decoder and the label, but ignore fully using feature-level fine-grained representations from the encoder. To address these issues, we propose a novel Attention U-shaped Kolmogorov-Arnold Network named AttUKAN along with a novel Label-guided Pixel-wise Contrastive Loss for retinal vessel segmentation. Specifically, we implement Attention Gates into Kolmogorov-Arnold Networks to enhance model sensitivity by suppressing irrelevant feature activations and model interpretability by non-linear modeling of KAN blocks. Additionally, we also design a novel Label-guided Pixel-wise Contrastive Loss to supervise our proposed AttUKAN to extract more discriminative features by distinguishing between foreground vessel-pixel pairs and background pairs. Experiments are conducted across four public datasets including DRIVE, STARE, CHASE_DB1, HRF and our private dataset. AttUKAN achieves F1 scores of 82.50%, 81.14%, 81.34%, 80.21% and 80.09%, along with MIoU scores of 70.24%, 68.64%, 68.59%, 67.21% and 66.94% in the above datasets, which are the highest compared to 11 networks for retinal vessel segmentation. Quantitative and qualitative results show that our AttUKAN achieves state-of-the-art performance and outperforms existing retinal vessel segmentation methods. Our code will be available at https://github.com/stevezs315/AttUKAN.
Low-Rank Mixture-of-Experts for Continual Medical Image Segmentation
Jun 19, 2024



The primary goal of continual learning (CL) task in medical image segmentation field is to solve the "catastrophic forgetting" problem, where the model totally forgets previously learned features when it is extended to new categories (class-level) or tasks (task-level). Due to the privacy protection, the historical data labels are inaccessible. Prevalent continual learning methods primarily focus on generating pseudo-labels for old datasets to force the model to memorize the learned features. However, the incorrect pseudo-labels may corrupt the learned feature and lead to a new problem that the better the model is trained on the old task, the poorer the model performs on the new tasks. To avoid this problem, we propose a network by introducing the data-specific Mixture of Experts (MoE) structure to handle the new tasks or categories, ensuring that the network parameters of previous tasks are unaffected or only minimally impacted. To further overcome the tremendous memory costs caused by introducing additional structures, we propose a Low-Rank strategy which significantly reduces memory cost. We validate our method on both class-level and task-level continual learning challenges. Extensive experiments on multiple datasets show our model outperforms all other methods.
Branches Mutual Promotion for End-to-End Weakly Supervised Semantic Segmentation
Aug 09, 2023



End-to-end weakly supervised semantic segmentation aims at optimizing a segmentation model in a single-stage training process based on only image annotations. Existing methods adopt an online-trained classification branch to provide pseudo annotations for supervising the segmentation branch. However, this strategy makes the classification branch dominate the whole concurrent training process, hindering these two branches from assisting each other. In our work, we treat these two branches equally by viewing them as diverse ways to generate the segmentation map, and add interactions on both their supervision and operation to achieve mutual promotion. For this purpose, a bidirectional supervision mechanism is elaborated to force the consistency between the outputs of these two branches. Thus, the segmentation branch can also give feedback to the classification branch to enhance the quality of localization seeds. Moreover, our method also designs interaction operations between these two branches to exchange their knowledge to assist each other. Experiments indicate our work outperforms existing end-to-end weakly supervised segmentation methods.
Label-noise-tolerant medical image classification via self-attention and self-supervised learning
Jun 16, 2023Deep neural networks (DNNs) have been widely applied in medical image classification and achieve remarkable classification performance. These achievements heavily depend on large-scale accurately annotated training data. However, label noise is inevitably introduced in the medical image annotation, as the labeling process heavily relies on the expertise and experience of annotators. Meanwhile, DNNs suffer from overfitting noisy labels, degrading the performance of models. Therefore, in this work, we innovatively devise noise-robust training approach to mitigate the adverse effects of noisy labels in medical image classification. Specifically, we incorporate contrastive learning and intra-group attention mixup strategies into the vanilla supervised learning. The contrastive learning for feature extractor helps to enhance visual representation of DNNs. The intra-group attention mixup module constructs groups and assigns self-attention weights for group-wise samples, and subsequently interpolates massive noisy-suppressed samples through weighted mixup operation. We conduct comparative experiments on both synthetic and real-world noisy medical datasets under various noise levels. Rigorous experiments validate that our noise-robust method with contrastive learning and attention mixup can effectively handle with label noise, and is superior to state-of-the-art methods. An ablation study also shows that both components contribute to boost model performance. The proposed method demonstrates its capability of curb label noise and has certain potential toward real-world clinic applications.
Background-aware Classification Activation Map for Weakly Supervised Object Localization
Dec 29, 2021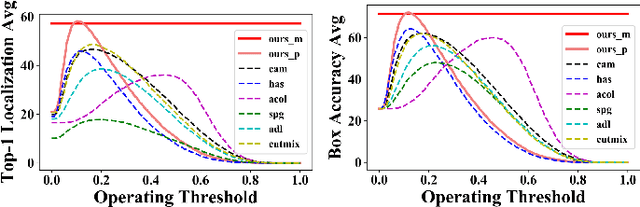
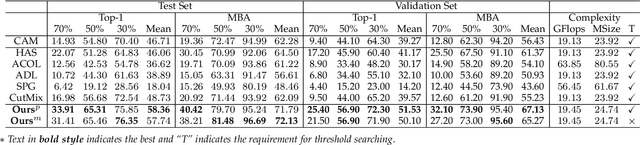

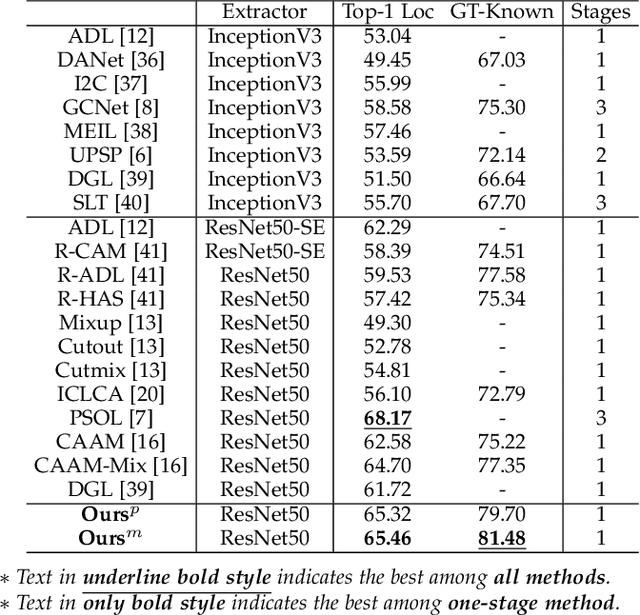
Weakly supervised object localization (WSOL) relaxes the requirement of dense annotations for object localization by using image-level classification masks to supervise its learning process. However, current WSOL methods suffer from excessive activation of background locations and need post-processing to obtain the localization mask. This paper attributes these issues to the unawareness of background cues, and propose the background-aware classification activation map (B-CAM) to simultaneously learn localization scores of both object and background with only image-level labels. In our B-CAM, two image-level features, aggregated by pixel-level features of potential background and object locations, are used to purify the object feature from the object-related background and to represent the feature of the pure-background sample, respectively. Then based on these two features, both the object classifier and the background classifier are learned to determine the binary object localization mask. Our B-CAM can be trained in end-to-end manner based on a proposed stagger classification loss, which not only improves the objects localization but also suppresses the background activation. Experiments show that our B-CAM outperforms one-stage WSOL methods on the CUB-200, OpenImages and VOC2012 datasets.
A Label Management Mechanism for Retinal Fundus Image Classification of Diabetic Retinopathy
Jun 23, 2021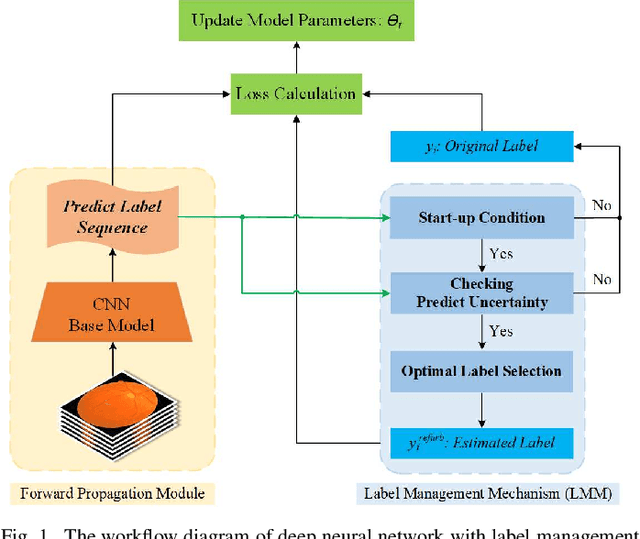
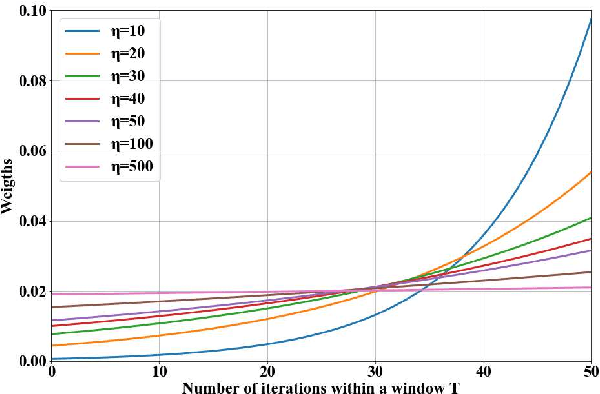
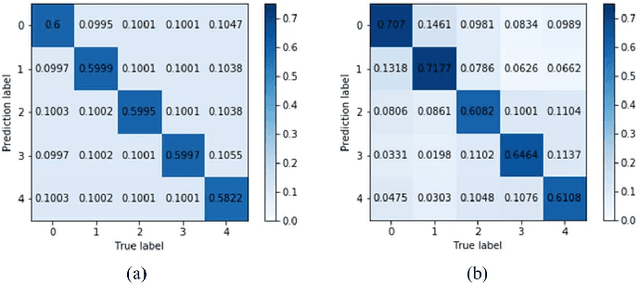
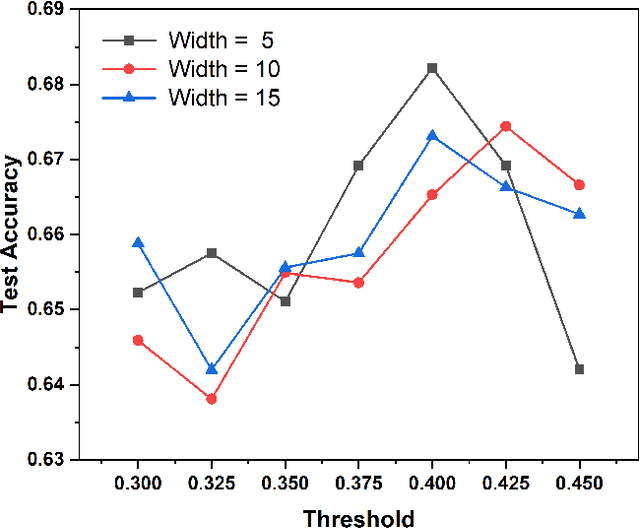
Diabetic retinopathy (DR) remains the most prevalent cause of vision impairment and irreversible blindness in the working-age adults. Due to the renaissance of deep learning (DL), DL-based DR diagnosis has become a promising tool for the early screening and severity grading of DR. However, training deep neural networks (DNNs) requires an enormous amount of carefully labeled data. Noisy label data may be introduced when labeling plenty of data, degrading the performance of models. In this work, we propose a novel label management mechanism (LMM) for the DNN to overcome overfitting on the noisy data. LMM utilizes maximum posteriori probability (MAP) in the Bayesian statistic and time-weighted technique to selectively correct the labels of unclean data, which gradually purify the training data and improve classification performance. Comprehensive experiments on both synthetic noise data (Messidor \& our collected DR dataset) and real-world noise data (ANIMAL-10N) demonstrated that LMM could boost performance of models and is superior to three state-of-the-art methods.