 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Projection Universal Model for Comprehensive Full-Body Medical Imaging Segmentation
Dec 26, 2024The integration of deep learning in medical imaging has shown great promise for enhancing diagnostic, therapeutic, and research outcomes. However, applying universal models across multiple modalities remains challenging due to the inherent variability in data characteristics. This study aims to introduce and evaluate a Modality Projection Universal Model (MPUM). MPUM employs a novel modality-projection strategy, which allows the model to dynamically adjust its parameters to optimize performance across different imaging modalities. The MPUM demonstrated superior accuracy in identifying anatomical structures, enabling precise quantification for improved clinical decision-making. It also identifies metabolic associations within the brain-body axis, advancing research on brain-body physiological correlations. Furthermore, MPUM's unique controller-based convolution layer enables visualization of saliency maps across all network layers, significantly enhancing the model's interpretability.
A Novel Unified Conditional Score-based Generative Framework for Multi-modal Medical Image Completion
Jul 07, 2022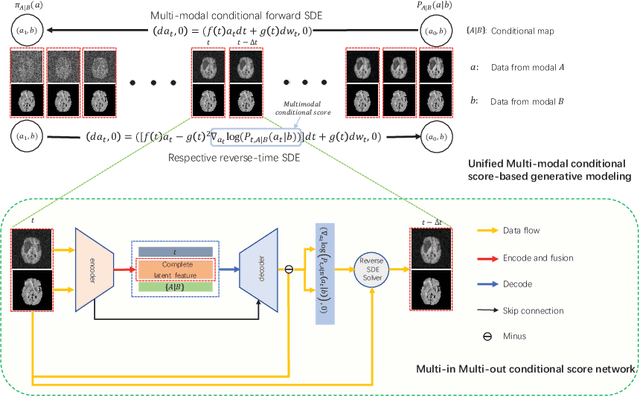
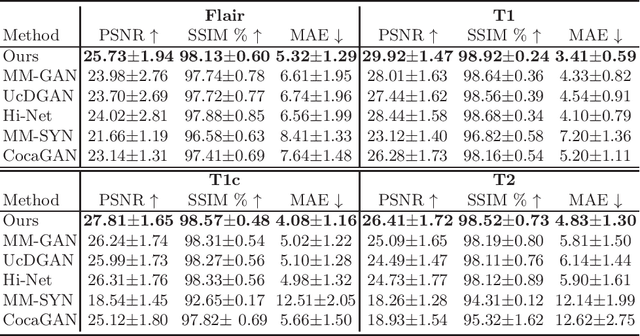
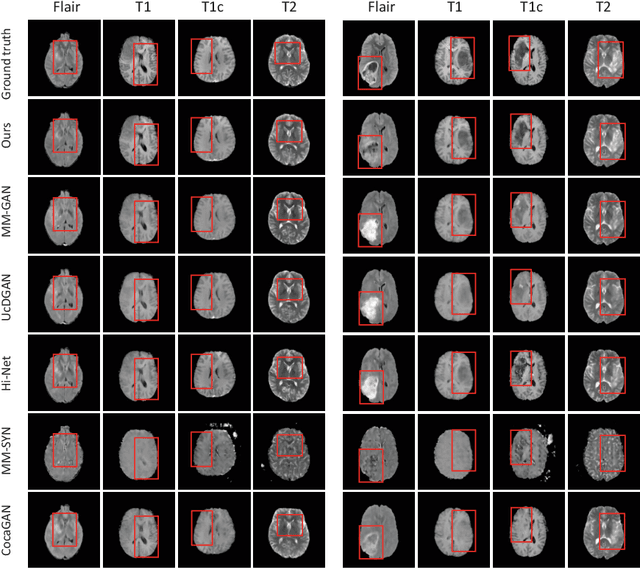
Multi-modal medical image completion has been extensively applied to alleviate the missing modality issue in a wealth of multi-modal diagnostic tasks. However, for most existing synthesis methods, their inferences of missing modalities can collapse into a deterministic mapping from the available ones, ignoring the uncertainties inherent in the cross-modal relationships. Here, we propose the Unified Multi-Modal Conditional Score-based Generative Model (UMM-CSGM) to take advantage of Score-based Generative Model (SGM) in modeling and stochastically sampling a target probability distribution, and further extend SGM to cross-modal conditional synthesis for various missing-modality configurations in a unified framework. Specifically, UMM-CSGM employs a novel multi-in multi-out Conditional Score Network (mm-CSN) to learn a comprehensive set of cross-modal conditional distributions via conditional diffusion and reverse generation in the complete modality space. In this way, the generation process can be accurately conditioned by all available information, and can fit all possible configurations of missing modalities in a single network. Experiments on BraTS19 dataset show that the UMM-CSGM can more reliably synthesize the heterogeneous enhancement and irregular area in tumor-induced lesions for any missing modalities.
Background-aware Classification Activation Map for Weakly Supervised Object Localization
Dec 29, 2021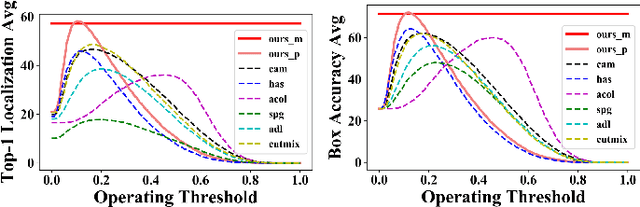
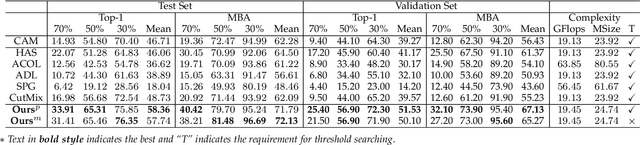

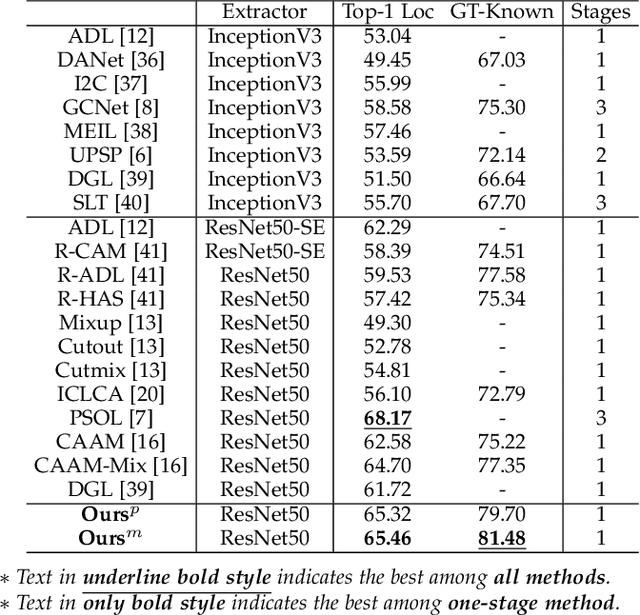
Weakly supervised object localization (WSOL) relaxes the requirement of dense annotations for object localization by using image-level classification masks to supervise its learning process. However, current WSOL methods suffer from excessive activation of background locations and need post-processing to obtain the localization mask. This paper attributes these issues to the unawareness of background cues, and propose the background-aware classification activation map (B-CAM) to simultaneously learn localization scores of both object and background with only image-level labels. In our B-CAM, two image-level features, aggregated by pixel-level features of potential background and object locations, are used to purify the object feature from the object-related background and to represent the feature of the pure-background sample, respectively. Then based on these two features, both the object classifier and the background classifier are learned to determine the binary object localization mask. Our B-CAM can be trained in end-to-end manner based on a proposed stagger classification loss, which not only improves the objects localization but also suppresses the background activation. Experiments show that our B-CAM outperforms one-stage WSOL methods on the CUB-200, OpenImages and VOC2012 datasets.
A Label Management Mechanism for Retinal Fundus Image Classification of Diabetic Retinopathy
Jun 23, 2021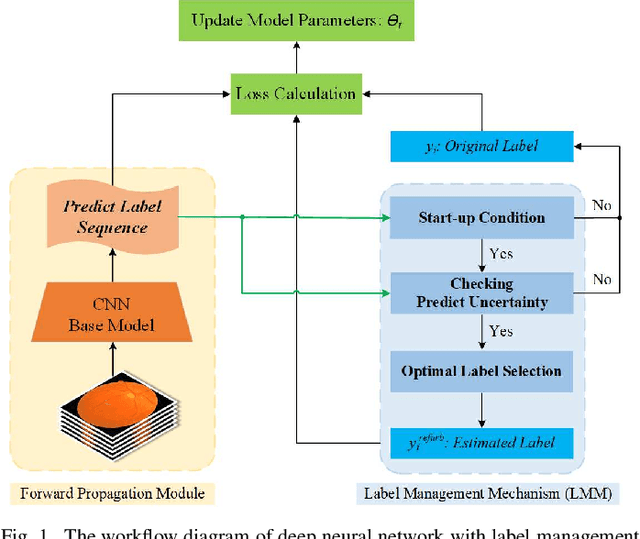
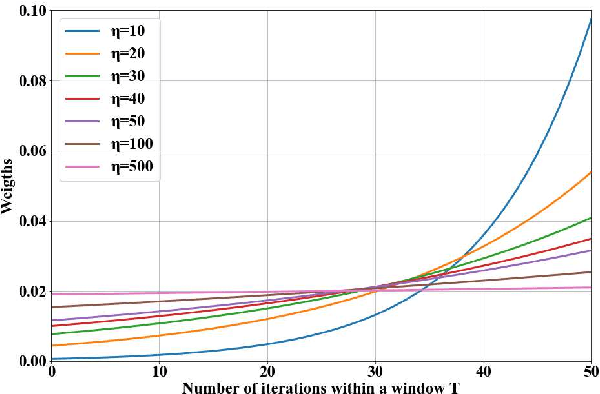
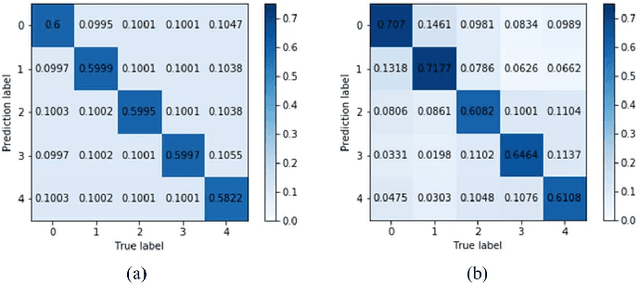
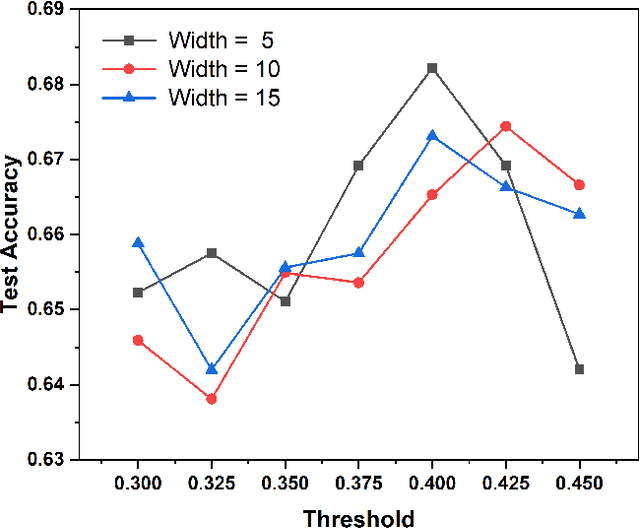
Diabetic retinopathy (DR) remains the most prevalent cause of vision impairment and irreversible blindness in the working-age adults. Due to the renaissance of deep learning (DL), DL-based DR diagnosis has become a promising tool for the early screening and severity grading of DR. However, training deep neural networks (DNNs) requires an enormous amount of carefully labeled data. Noisy label data may be introduced when labeling plenty of data, degrading the performance of models. In this work, we propose a novel label management mechanism (LMM) for the DNN to overcome overfitting on the noisy data. LMM utilizes maximum posteriori probability (MAP) in the Bayesian statistic and time-weighted technique to selectively correct the labels of unclean data, which gradually purify the training data and improve classification performance. Comprehensive experiments on both synthetic noise data (Messidor \& our collected DR dataset) and real-world noise data (ANIMAL-10N) demonstrated that LMM could boost performance of models and is superior to three state-of-the-art methods.