 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Unified Conditional Score-based Generative Framework for Multi-modal Medical Image Completion
Jul 07, 2022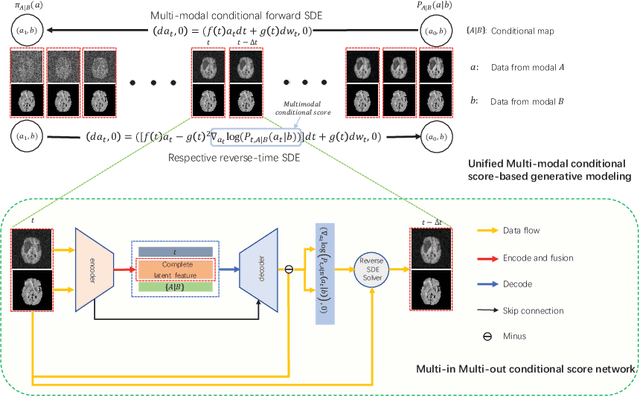
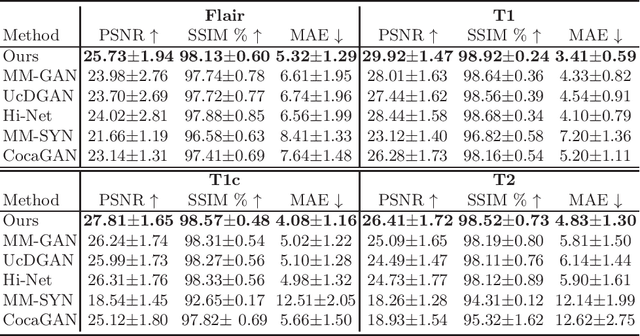
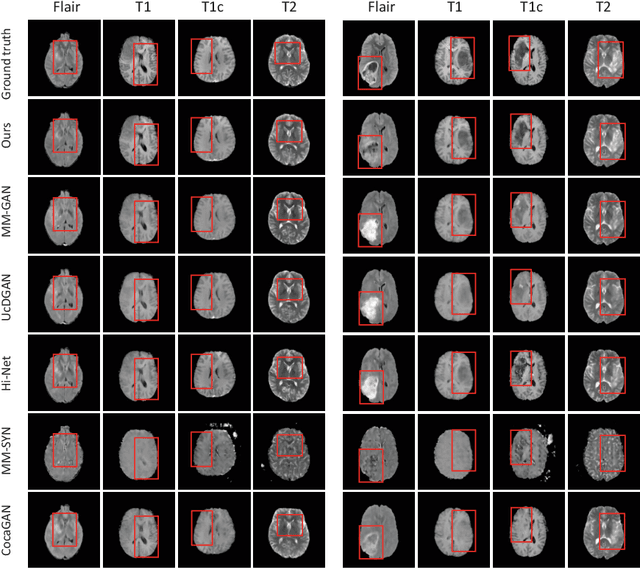
Multi-modal medical image completion has been extensively applied to alleviate the missing modality issue in a wealth of multi-modal diagnostic tasks. However, for most existing synthesis methods, their inferences of missing modalities can collapse into a deterministic mapping from the available ones, ignoring the uncertainties inherent in the cross-modal relationships. Here, we propose the Unified Multi-Modal Conditional Score-based Generative Model (UMM-CSGM) to take advantage of Score-based Generative Model (SGM) in modeling and stochastically sampling a target probability distribution, and further extend SGM to cross-modal conditional synthesis for various missing-modality configurations in a unified framework. Specifically, UMM-CSGM employs a novel multi-in multi-out Conditional Score Network (mm-CSN) to learn a comprehensive set of cross-modal conditional distributions via conditional diffusion and reverse generation in the complete modality space. In this way, the generation process can be accurately conditioned by all available information, and can fit all possible configurations of missing modalities in a single network. Experiments on BraTS19 dataset show that the UMM-CSGM can more reliably synthesize the heterogeneous enhancement and irregular area in tumor-induced lesions for any missing modalities.
Knee Cartilage Defect Assessment by Graph Representation and Surface Convolution
Jan 12, 2022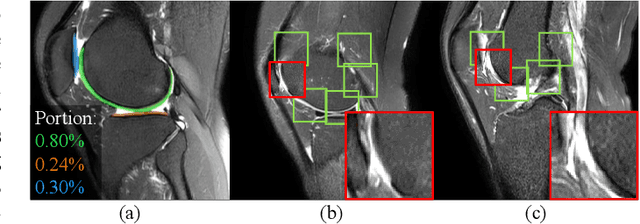
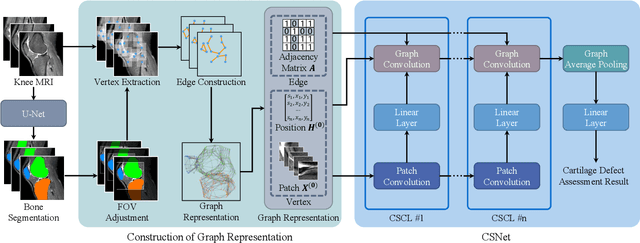
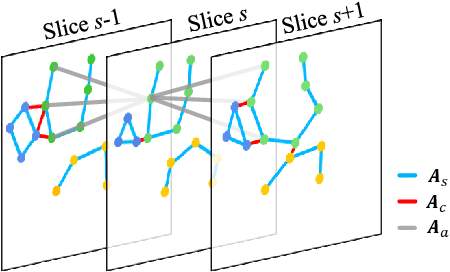
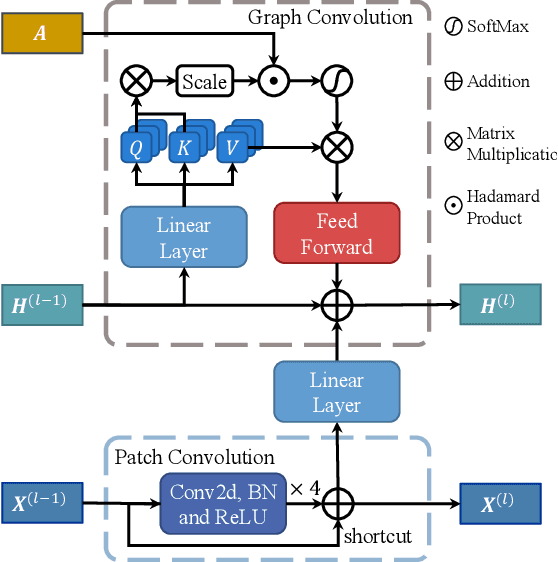
Knee osteoarthritis (OA) is the most common osteoarthritis and a leading cause of disability. Cartilage defects are regarded as major manifestations of knee OA, which are visible by magnetic resonance imaging (MRI). Thus early detection and assessment for knee cartilage defects are important for protecting patients from knee OA. In this way, many attempts have been made on knee cartilage defect assessment by applying convolutional neural networks (CNNs) to knee MRI. However, the physiologic characteristics of the cartilage may hinder such efforts: the cartilage is a thin curved layer, implying that only a small portion of voxels in knee MRI can contribute to the cartilage defect assessment; heterogeneous scanning protocols further challenge the feasibility of the CNNs in clinical practice; the CNN-based knee cartilage evaluation results lack interpretability. To address these challenges, we model the cartilages structure and appearance from knee MRI into a graph representation, which is capable of handling highly diverse clinical data. Then, guided by the cartilage graph representation, we design a non-Euclidean deep learning network with the self-attention mechanism, to extract cartilage features in the local and global, and to derive the final assessment with a visualized result. Our comprehensive experiments show that the proposed method yields superior performance in knee cartilage defect assessment, plus its convenient 3D visualization for interpretability.
Hierarchical Latent Word Clustering
Jan 20, 2016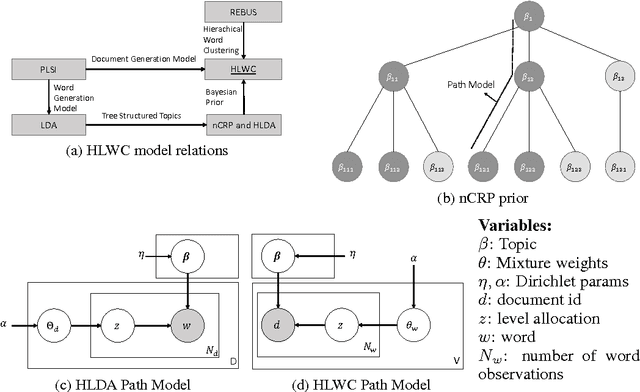
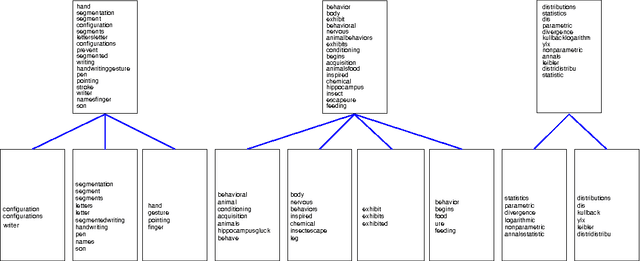
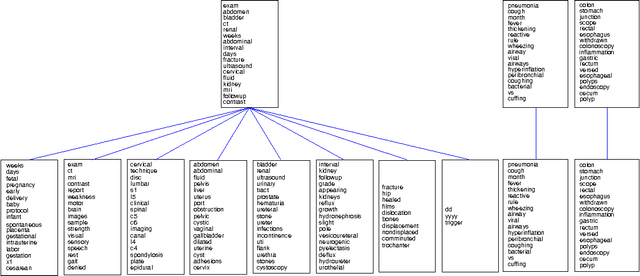
This paper presents a new Bayesian non-parametric model by extending the usage of Hierarchical Dirichlet Allocation to extract tree structured word clusters from text data. The inference algorithm of the model collects words in a cluster if they share similar distribution over documents. In our experiments, we observed meaningful hierarchical structures on NIPS corpus and radiology reports collected from public repositories.
Information Forests
Feb 07, 2012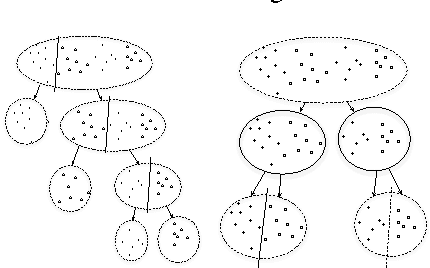
We describe Information Forests, an approach to classification that generalizes Random Forests by replacing the splitting criterion of non-leaf nodes from a discriminative one -- based on the entropy of the label distribution -- to a generative one -- based on maximizing the information divergence between the class-conditional distributions in the resulting partitions. The basic idea consists of deferring classification until a measure of "classification confidence" is sufficiently high, and instead breaking down the data so as to maximize this measure. In an alternative interpretation, Information Forests attempt to partition the data into subsets that are "as informative as possible" for the purpose of the task, which is to classify the data. Classification confidence, or informative content of the subsets, is quantified by the Information Divergence. Our approach relates to active learning, semi-supervised learning, mixed generative/discriminative learning.