 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactDiff: Latent Diffusion for Facial Reaction Generation
May 20, 2025Given the audio-visual clip of the speaker, facial reaction generation aims to predict the listener's facial reactions. The challenge lies in capturing the relevance between video and audio while balancing appropriateness, realism, and diversity. While prior works have mostly focused on uni-modal inputs or simplified reaction mappings, recent approaches such as PerFRDiff have explored multi-modal inputs and the one-to-many nature of appropriate reaction mappings. In this work, we propose the Facial Reaction Diffusion (ReactDiff) framework that uniquely integrates a Multi-Modality Transformer with conditional diffusion in the latent space for enhanced reaction generation. Unlike existing methods, ReactDiff leverages intra- and inter-class attention for fine-grained multi-modal interaction, while the latent diffusion process between the encoder and decoder enables diverse yet contextually appropriate outputs. Experimental results demonstrate that ReactDiff significantly outperforms existing approaches, achieving a facial reaction correlation of 0.26 and diversity score of 0.094 while maintaining competitive realism. The code is open-sourced at \href{https://github.com/Hunan-Tiger/ReactDiff}{github}.
MUC: Mixture of Uncalibrated Cameras for Robust 3D Human Body Reconstruction
Mar 08, 2024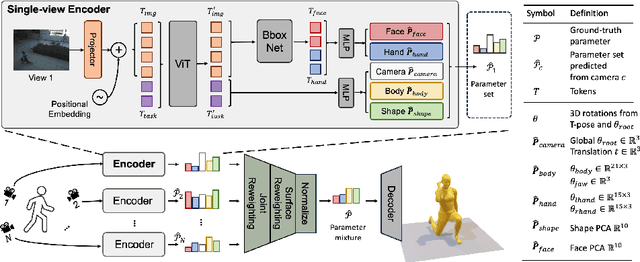
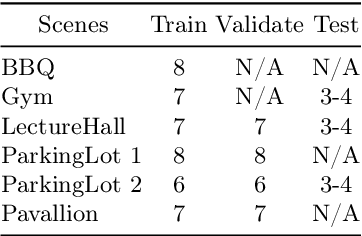
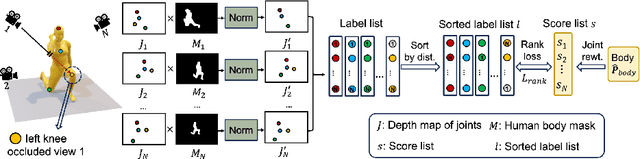

Multiple cameras can provide multi-view video coverage of a person. It is necessary to fuse multi-view data, e.g., for subsequent behavioral analysis, while such fusion often relies on calibration of cameras in traditional solutions. However, it is non-trivial to calibrate multiple cameras. In this work, we propose a method to reconstruct 3D human body from multiple uncalibrated camera views. First, we adopt a pre-trained human body encoder to process each individual camera view, such that human body models and parameters can be reconstructed for each view. Next, instead of simply averaging models across views, we train a network to determine the weights of individual views for their fusion, based on the parameters estimated for joints and hands of human body as well as camera positions. Further, we turn to the mesh surface of human body for dynamic fusion, such that facial expression can be seamlessly integrated into the model of human body. Our method has demonstrated superior performance in reconstructing human body upon two public datasets. More importantly, our method can flexibly support ad-hoc deployment of an arbitrary number of cameras, which has significant potential in related applications. We will release source code upon acceptance of the paper.
ChatCAD+: Towards a Universal and Reliable Interactive CAD using LLMs
May 26, 2023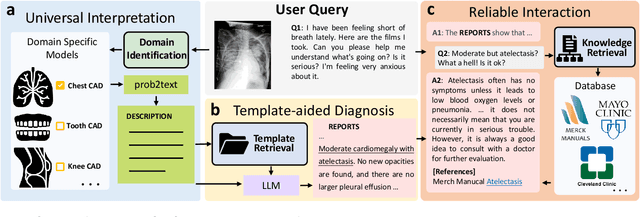
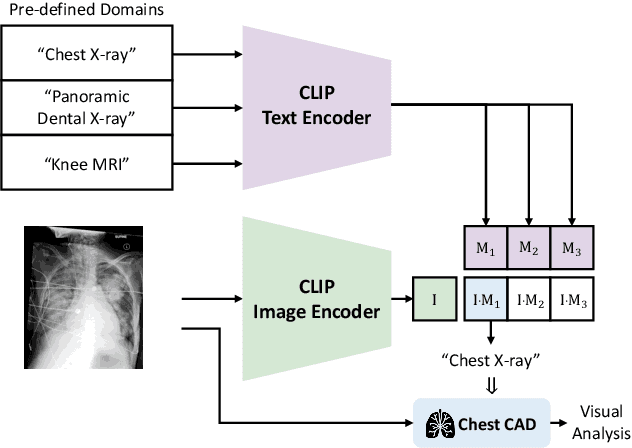
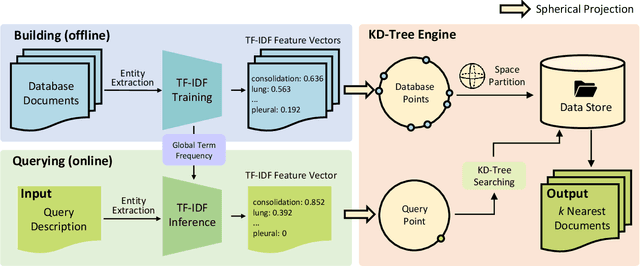
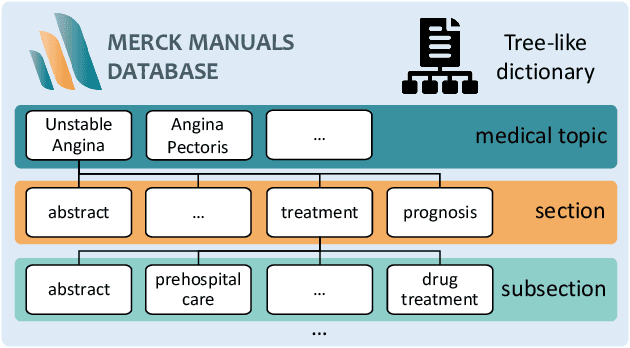
The potential of integrating Computer-Assisted Diagnosis (CAD) with Large Language Models (LLMs) in clinical applications, particularly in digital family doctor and clinic assistant roles, shows promise. However, existing works have limitations in terms of reliability, effectiveness, and their narrow applicability to specific image domains, which restricts their overall processing capabilities. Moreover, the mismatch in writing style between LLMs and radiologists undermines their practical utility. To address these challenges, we present ChatCAD+, an interactive CAD system that is universal, reliable, and capable of handling medical images from diverse domains. ChatCAD+ utilizes current information obtained from reputable medical websites to offer precise medical advice. Additionally, it incorporates a template retrieval system that emulates real-world diagnostic reporting, thereby improving its seamless integration into existing clinical workflows. The source code is available at https://github.com/zhaozh10/ChatCAD. The online demo will be available soon.
Learning Better Contrastive View from Radiologist's Gaze
May 15, 2023



Recent self-supervised contrastive learning methods greatly benefit from the Siamese structure that aims to minimizing distances between positive pairs. These methods usually apply random data augmentation to input images, expecting the augmented views of the same images to be similar and positively paired. However, random augmentation may overlook image semantic information and degrade the quality of augmented views in contrastive learning. This issue becomes more challenging in medical images since the abnormalities related to diseases can be tiny, and are easy to be corrupted (e.g., being cropped out) in the current scheme of random augmentation. In this work, we first demonstrate that, for widely-used X-ray images, the conventional augmentation prevalent in contrastive pre-training can affect the performance of the downstream diagnosis or classification tasks. Then, we propose a novel augmentation method, i.e., FocusContrast, to learn from radiologists' gaze in diagnosis and generate contrastive views for medical images with guidance from radiologists' visual attention. Specifically, we track the gaze movement of radiologists and model their visual attention when reading to diagnose X-ray images. The learned model can predict visual attention of the radiologists given a new input image, and further guide the attention-aware augmentation that hardly neglects the disease-related abnormalities. As a plug-and-play and framework-agnostic module, FocusContrast consistently improves state-of-the-art contrastive learning methods of SimCLR, MoCo, and BYOL by 4.0~7.0% in classification accuracy on a knee X-ray dataset.
Domain Generalization for Mammographic Image Analysis via Contrastive Learning
Apr 20, 2023Mammographic image analysis is a fundamental problem in the computer-aided diagnosis scheme, which has recently made remarkable progress with the advance of deep learning. However, the construction of a deep learning model requires training data that are large and sufficiently diverse in terms of image style and quality. In particular, the diversity of image style may be majorly attributed to the vendor factor. However, mammogram collection from vendors as many as possible is very expensive and sometimes impractical for laboratory-scale studies. Accordingly, to further augment the generalization capability of deep learning models to various vendors with limited resources, a new contrastive learning scheme is developed. Specifically, the backbone network is firstly trained with a multi-style and multi-view unsupervised self-learning scheme for the embedding of invariant features to various vendor styles. Afterward, the backbone network is then recalibrated to the downstream tasks of mass detection, multi-view mass matching, BI-RADS classification and breast density classification with specific supervised learning. The proposed method is evaluated with mammograms from four vendors and two unseen public datasets. The experimental results suggest that our approach can effectively improve analysis performance on both seen and unseen domains, and outperforms many state-of-the-art (SOTA) generalization methods.
Knee Cartilage Defect Assessment by Graph Representation and Surface Convolution
Jan 12, 2022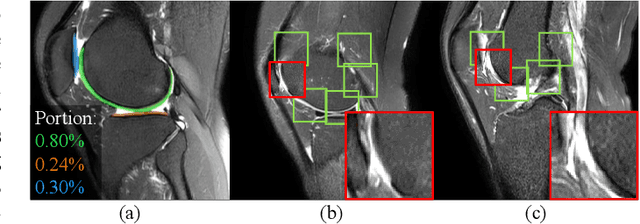
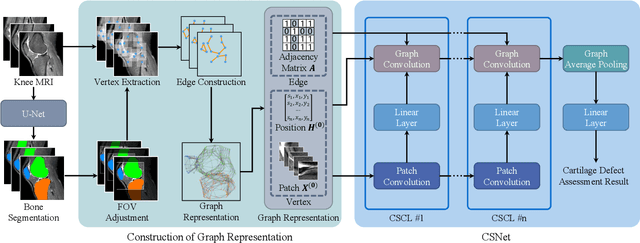
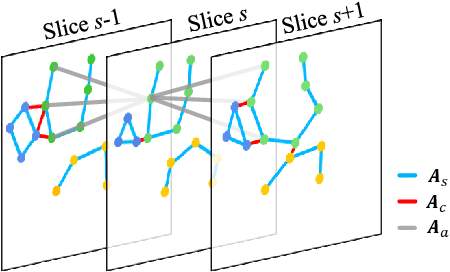
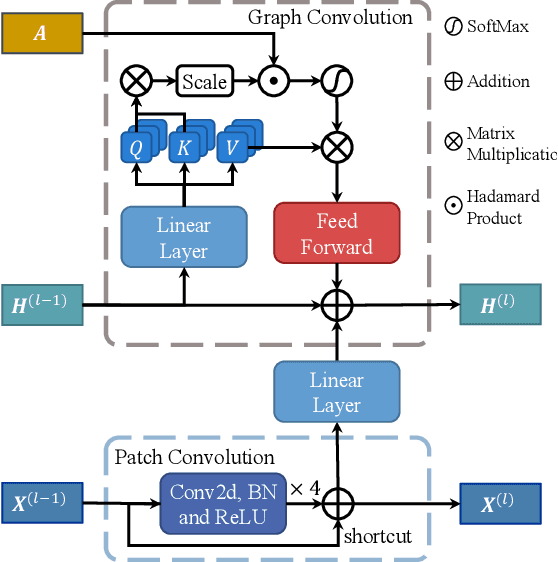
Knee osteoarthritis (OA) is the most common osteoarthritis and a leading cause of disability. Cartilage defects are regarded as major manifestations of knee OA, which are visible by magnetic resonance imaging (MRI). Thus early detection and assessment for knee cartilage defects are important for protecting patients from knee OA. In this way, many attempts have been made on knee cartilage defect assessment by applying convolutional neural networks (CNNs) to knee MRI. However, the physiologic characteristics of the cartilage may hinder such efforts: the cartilage is a thin curved layer, implying that only a small portion of voxels in knee MRI can contribute to the cartilage defect assessment; heterogeneous scanning protocols further challenge the feasibility of the CNNs in clinical practice; the CNN-based knee cartilage evaluation results lack interpretability. To address these challenges, we model the cartilages structure and appearance from knee MRI into a graph representation, which is capable of handling highly diverse clinical data. Then, guided by the cartilage graph representation, we design a non-Euclidean deep learning network with the self-attention mechanism, to extract cartilage features in the local and global, and to derive the final assessment with a visualized result. Our comprehensive experiments show that the proposed method yields superior performance in knee cartilage defect assessment, plus its convenient 3D visualization for interpretability.