 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColorFLUX: A Structure-Color Decoupling Framework for Old Photo Colorization
Mar 30, 2026Old photos preserve invaluable historical memories, making their restoration and colorization highly desirable. While existing restoration models can address some degradation issues like denoising and scratch removal, they often struggle with accurate colorization. This limitation arises from the unique degradation inherent in old photos, such as faded brightness and altered color hues, which are different from modern photo distributions, creating a substantial domain gap during colorization. In this paper, we propose a novel old photo colorization framework based on the generative diffusion model FLUX. Our approach introduces a structure-color decoupling strategy that separates structure preservation from color restoration, enabling accurate colorization of old photos while maintaining structural consistency. We further enhance the model with a progressive Direct Preference Optimization (Pro-DPO) strategy, which allows the model to learn subtle color preferences through coarse-to-fine transitions in color augmentation. Additionally, we address the limitations of text-based prompts by introducing visual semantic prompts, which extract fine-grained semantic information directly from old photos, helping to eliminate the color bias inherent in old photos. Experimental results on both synthetic and real datasets demonstrate that our approach outperforms existing state-of-the-art colorization methods, including closed-source commercial models, producing high-quality and vivid colorization.
PlanViz: Evaluating Planning-Oriented Image Generation and Editing for Computer-Use Tasks
Feb 06, 2026Unified multimodal models (UMMs) have shown impressive capabilities in generating natural images and supporting multimodal reasoning. However, their potential in supporting computer-use planning tasks, which are closely related to our lives, remain underexplored. Image generation and editing in computer-use tasks require capabilities like spatial reasoning and procedural understanding, and it is still unknown whether UMMs have these capabilities to finish these tasks or not. Therefore, we propose PlanViz, a new benchmark designed to evaluate image generation and editing for computer-use tasks. To achieve the goal of our evaluation, we focus on sub-tasks which frequently involve in daily life and require planning steps. Specifically, three new sub-tasks are designed: route planning, work diagramming, and web&UI displaying. We address challenges in data quality ensuring by curating human-annotated questions and reference images, and a quality control process. For challenges of comprehensive and exact evaluation, a task-adaptive score, PlanScore, is proposed. The score helps understanding the correctness, visual quality and efficiency of generated images. Through experiments, we highlight key limitations and opportunities for future research on this topic.
UmniBench: Unified Understand and Generation Model Oriented Omni-dimensional Benchmark
Dec 19, 2025Unifying multimodal understanding and generation has shown impressive capabilities in cutting-edge proprietary systems. However, evaluations of unified multimodal models (UMMs) remain decoupled, assessing their understanding and generation abilities separately with corresponding datasets. To address this, we propose UmniBench, a benchmark tailored for UMMs with omni-dimensional evaluation. First, UmniBench can assess the understanding, generation, and editing ability within a single evaluation process. Based on human-examined prompts and QA pairs, UmniBench leverages UMM itself to evaluate its generation and editing ability with its understanding ability. This simple but effective paradigm allows comprehensive evaluation of UMMs. Second, UmniBench covers 13 major domains and more than 200 concepts, ensuring a thorough inspection of UMMs. Moreover, UmniBench can also decouple and separately evaluate understanding, generation, and editing abilities, providing a fine-grained assessment. Based on UmniBench, we benchmark 24 popular models, including both UMMs and single-ability large models. We hope this benchmark provides a more comprehensive and objective view of unified models and logistical support for improving the performance of the community model.
Visual Programmability: A Guide for Code-as-Thought in Chart Understanding
Sep 11, 2025Chart understanding presents a critical test to the reasoning capabilities of Vision-Language Models (VLMs). Prior approaches face critical limitations: some rely on external tools, making them brittle and constrained by a predefined toolkit, while others fine-tune specialist models that often adopt a single reasoning strategy, such as text-based chain-of-thought (CoT). The intermediate steps of text-based reasoning are difficult to verify, which complicates the use of reinforcement-learning signals that reward factual accuracy. To address this, we propose a Code-as-Thought (CaT) approach to represent the visual information of a chart in a verifiable, symbolic format. Our key insight is that this strategy must be adaptive: a fixed, code-only implementation consistently fails on complex charts where symbolic representation is unsuitable. This finding leads us to introduce Visual Programmability: a learnable property that determines if a chart-question pair is better solved with code or direct visual analysis. We implement this concept in an adaptive framework where a VLM learns to choose between the CaT pathway and a direct visual reasoning pathway. The selection policy of the model is trained with reinforcement learning using a novel dual-reward system. This system combines a data-accuracy reward to ground the model in facts and prevent numerical hallucination, with a decision reward that teaches the model when to use each strategy, preventing it from defaulting to a single reasoning mode. Experiments demonstrate strong and robust performance across diverse chart-understanding benchmarks. Our work shows that VLMs can be taught not only to reason but also how to reason, dynamically selecting the optimal reasoning pathway for each task.
Dual Prompting Image Restoration with Diffusion Transformers
Apr 24, 2025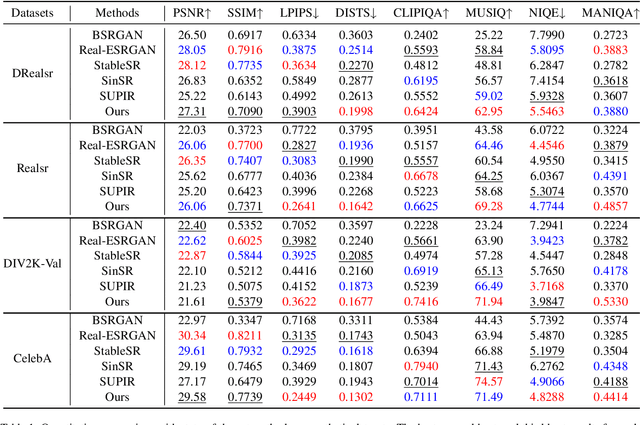
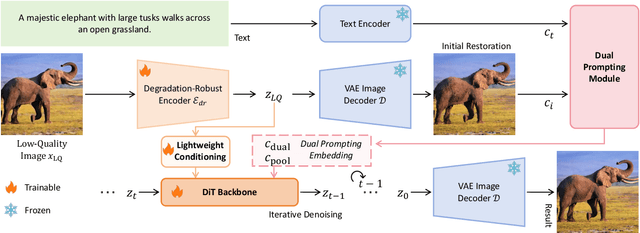
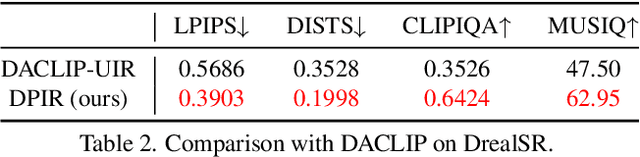
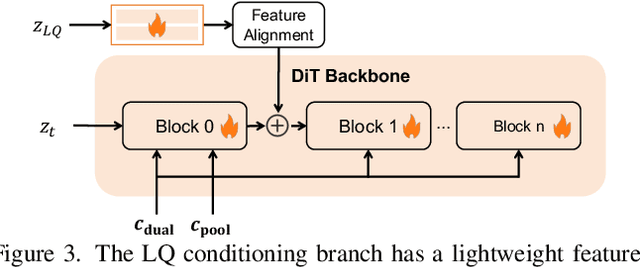
Recent state-of-the-art image restoration methods mostly adopt latent diffusion models with U-Net backbones, yet still facing challenges in achieving high-quality restoration due to their limited capabilities. Diffusion transformers (DiTs), like SD3, are emerging as a promising alternative because of their better quality with scalability. In this paper, we introduce DPIR (Dual Prompting Image Restoration), a novel image restoration method that effectivly extracts conditional information of low-quality images from multiple perspectives. Specifically, DPIR consits of two branches: a low-quality image conditioning branch and a dual prompting control branch. The first branch utilizes a lightweight module to incorporate image priors into the DiT with high efficiency. More importantly, we believe that in image restoration, textual description alone cannot fully capture its rich visual characteristics. Therefore, a dual prompting module is designed to provide DiT with additional visual cues, capturing both global context and local appearance. The extracted global-local visual prompts as extra conditional control, alongside textual prompts to form dual prompts, greatly enhance the quality of the restoration. Extensive experimental results demonstrate that DPIR delivers superior image restoration performance.
TD-BFR: Truncated Diffusion Model for Efficient Blind Face Restoration
Mar 26, 2025

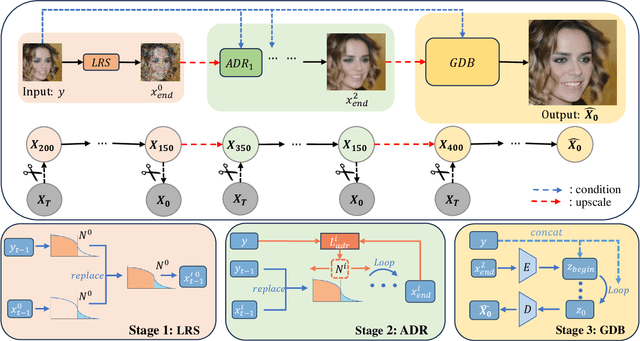

Diffusion-based methodologies have shown significant potential in blind face restoration (BFR), leveraging their robust generative capabilities. However, they are often criticized for two significant problems: 1) slow training and inference speed, and 2) inadequate recovery of fine-grained facial details. To address these problems, we propose a novel Truncated Diffusion model for efficient Blind Face Restoration (TD-BFR), a three-stage paradigm tailored for the progressive resolution of degraded images. Specifically, TD-BFR utilizes an innovative truncated sampling method, starting from low-quality (LQ) images at low resolution to enhance sampling speed, and then introduces an adaptive degradation removal module to handle unknown degradations and connect the generation processes across different resolutions. Additionally, we further adapt the priors of pre-trained diffusion models to recover rich facial details. Our method efficiently restores high-quality images in a coarse-to-fine manner and experimental results demonstrate that TD-BFR is, on average, \textbf{4.75$\times$} faster than current state-of-the-art diffusion-based BFR methods while maintaining competitive quality.
MUC: Mixture of Uncalibrated Cameras for Robust 3D Human Body Reconstruction
Mar 08, 2024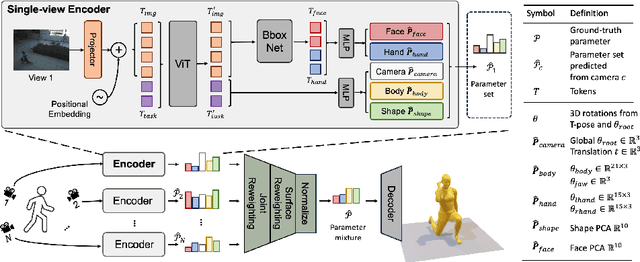
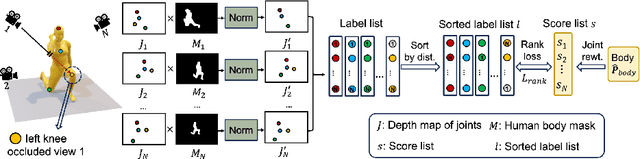

Multiple cameras can provide multi-view video coverage of a person. It is necessary to fuse multi-view data, e.g., for subsequent behavioral analysis, while such fusion often relies on calibration of cameras in traditional solutions. However, it is non-trivial to calibrate multiple cameras. In this work, we propose a method to reconstruct 3D human body from multiple uncalibrated camera views. First, we adopt a pre-trained human body encoder to process each individual camera view, such that human body models and parameters can be reconstructed for each view. Next, instead of simply averaging models across views, we train a network to determine the weights of individual views for their fusion, based on the parameters estimated for joints and hands of human body as well as camera positions. Further, we turn to the mesh surface of human body for dynamic fusion, such that facial expression can be seamlessly integrated into the model of human body. Our method has demonstrated superior performance in reconstructing human body upon two public datasets. More importantly, our method can flexibly support ad-hoc deployment of an arbitrary number of cameras, which has significant potential in related applications. We will release source code upon acceptance of the paper.
DR2: Diffusion-based Robust Degradation Remover for Blind Face Restoration
Mar 20, 2023Blind face restoration usually synthesizes degraded low-quality data with a pre-defined degradation model for training, while more complex cases could happen in the real world. This gap between the assumed and actual degradation hurts the restoration performance where artifacts are often observed in the output. However, it is expensive and infeasible to include every type of degradation to cover real-world cases in the training data. To tackle this robustness issue, we propose Diffusion-based Robust Degradation Remover (DR2) to first transform the degraded image to a coarse but degradation-invariant prediction, then employ an enhancement module to restore the coarse prediction to a high-quality image. By leveraging a well-performing denoising diffusion probabilistic model, our DR2 diffuses input images to a noisy status where various types of degradation give way to Gaussian noise, and then captures semantic information through iterative denoising steps. As a result, DR2 is robust against common degradation (e.g. blur, resize, noise and compression) and compatible with different designs of enhancement modules. Experiments in various settings show that our framework outperforms state-of-the-art methods on heavily degraded synthetic and real-world datasets.
Object as Hotspots: An Anchor-Free 3D Object Detection Approach via Firing of Hotspots
Dec 30, 2019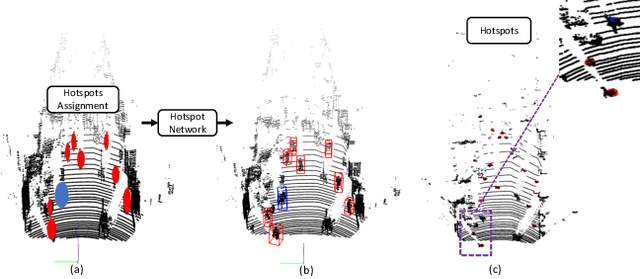



Accurate 3D object detection in LiDAR based point clouds suffers from the challenges of data sparsity and irregularities. Existing methods strive to organize the points regularly, e.g. voxelize, pass them through a designed 2D/3D neural network, and then define object-level anchors that predict offsets of 3D bounding boxes using collective evidence from all the points on the objects of interest. Converse to the state-of-the-art anchor-based methods, based on the very same nature of data sparsity and irregularities, we observe that even points on an isolated object part are informative about position and orientation of the object. We thus argue in this paper for an approach opposite to existing methods using object-level anchors. Technically, we propose to represent an object as a collection of point cliques; one can intuitively think of these point cliques as hotspots, giving rise to the representation of Object as Hotspots (OHS). Based on OHS, we propose a Hotspot Network (HotSpotNet) that performs 3D object detection via firing of hotspots without setting the predefined bounding boxes. A distinctive feature of HotSpotNet is that it makes predictions directly from individual hotspots, and final results are obtained by aggregating these hotspot predictions. Experiments on the KITTI benchmark show the efficacy of our proposed OHS representation. Our one-stage, anchor-free HotSpotNet beats all other one-stage detectors by at least 2% on cars , cyclists and pedestrian for all difficulty levels. Notably, our proposed method performs better on small and difficult objects and we rank the first among all the submitted methods on pedestrian of KITTI test set.
Frustum ConvNet: Sliding Frustums to Aggregate Local Point-Wise Features for Amodal 3D Object Detection
Mar 05, 2019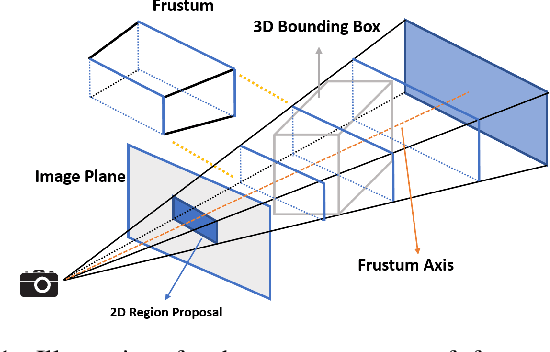
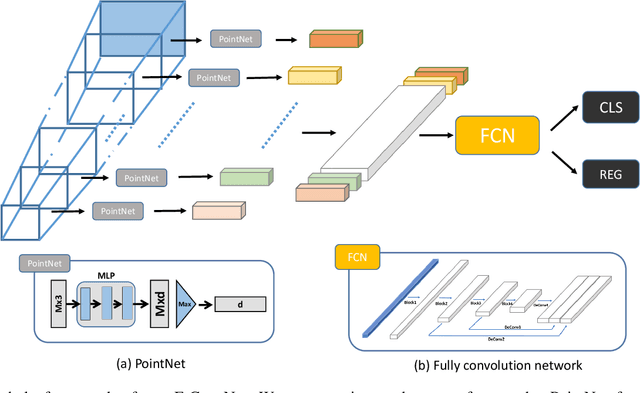
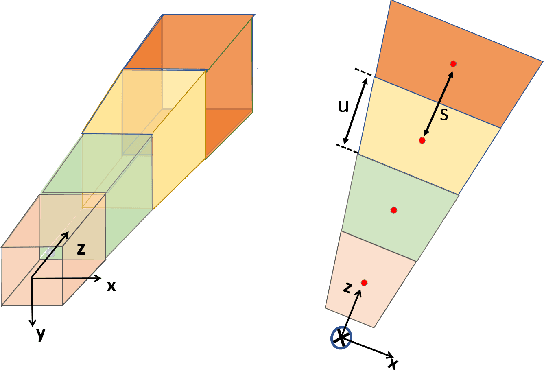
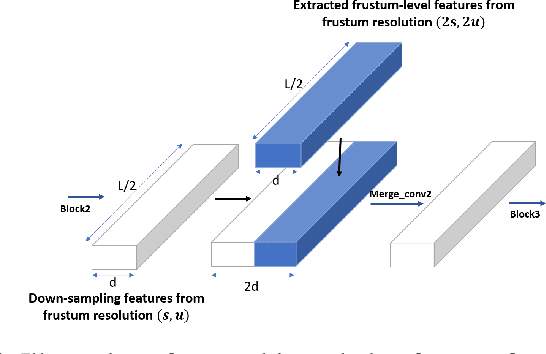
In this work, we propose a novel method termed Frustum ConvNet (F-ConvNet) for amodal 3D object detection from point clouds. Given 2D region proposals in a RGB image, our method first generates a sequence of frustums for each region proposal, and uses the obtained frustums to group local points. F-ConvNet aggregates point-wise features as frustumlevel feature vectors, and arrays these feature vectors as a feature map for use of its subsequent component of fully convolutional network (FCN), which spatially fuses frustumlevel features and supports an end-to-end and continuous estimation of oriented boxes in the 3D space. We also propose component variants of L-ConvNet, including a FCN variant that extracts multi-resolution frustum features, and a refined use of L-ConvNet over a reduced 3D space. Careful ablation studies verify the efficacy of these component variants. LConvNet assumes no prior knowledge of the working 3D environment, and is thus dataset-agnostic. We present experiments on both the indoor SUN-RGBD and outdoor KITTI datasets. LConvNet outperforms all existing methods on SUN-RGBD, and at the time of submission it outperforms all published works on the KITTI benchmark. We will make the code of L-ConvNet publicly available.