 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
LiveTalk: Real-Time Multimodal Interactive Video Diffusion via Improved On-Policy Distillation
Dec 29, 2025Real-time video generation via diffusion is essential for building general-purpose multimodal interactive AI systems. However, the simultaneous denoising of all video frames with bidirectional attention via an iterative process in diffusion models prevents real-time interaction. While existing distillation methods can make the model autoregressive and reduce sampling steps to mitigate this, they focus primarily on text-to-video generation, leaving the human-AI interaction unnatural and less efficient. This paper targets real-time interactive video diffusion conditioned on a multimodal context, including text, image, and audio, to bridge the gap. Given the observation that the leading on-policy distillation approach Self Forcing encounters challenges (visual artifacts like flickering, black frames, and quality degradation) with multimodal conditioning, we investigate an improved distillation recipe with emphasis on the quality of condition inputs as well as the initialization and schedule for the on-policy optimization. On benchmarks for multimodal-conditioned (audio, image, and text) avatar video generation including HDTF, AVSpeech, and CelebV-HQ, our distilled model matches the visual quality of the full-step, bidirectional baselines of similar or larger size with 20x less inference cost and latency. Further, we integrate our model with audio language models and long-form video inference technique Anchor-Heavy Identity Sinks to build LiveTalk, a real-time multimodal interactive avatar system. System-level evaluation on our curated multi-turn interaction benchmark shows LiveTalk outperforms state-of-the-art models (Sora2, Veo3) in multi-turn video coherence and content quality, while reducing response latency from 1 to 2 minutes to real-time generation, enabling seamless human-AI multimodal interaction.
Visual Programmability: A Guide for Code-as-Thought in Chart Understanding
Sep 11, 2025Chart understanding presents a critical test to the reasoning capabilities of Vision-Language Models (VLMs). Prior approaches face critical limitations: some rely on external tools, making them brittle and constrained by a predefined toolkit, while others fine-tune specialist models that often adopt a single reasoning strategy, such as text-based chain-of-thought (CoT). The intermediate steps of text-based reasoning are difficult to verify, which complicates the use of reinforcement-learning signals that reward factual accuracy. To address this, we propose a Code-as-Thought (CaT) approach to represent the visual information of a chart in a verifiable, symbolic format. Our key insight is that this strategy must be adaptive: a fixed, code-only implementation consistently fails on complex charts where symbolic representation is unsuitable. This finding leads us to introduce Visual Programmability: a learnable property that determines if a chart-question pair is better solved with code or direct visual analysis. We implement this concept in an adaptive framework where a VLM learns to choose between the CaT pathway and a direct visual reasoning pathway. The selection policy of the model is trained with reinforcement learning using a novel dual-reward system. This system combines a data-accuracy reward to ground the model in facts and prevent numerical hallucination, with a decision reward that teaches the model when to use each strategy, preventing it from defaulting to a single reasoning mode. Experiments demonstrate strong and robust performance across diverse chart-understanding benchmarks. Our work shows that VLMs can be taught not only to reason but also how to reason, dynamically selecting the optimal reasoning pathway for each task.
Thinking with Generated Images
May 28, 2025We present Thinking with Generated Images, a novel paradigm that fundamentally transforms how large multimodal models (LMMs) engage with visual reasoning by enabling them to natively think across text and vision modalities through spontaneous generation of intermediate visual thinking steps. Current visual reasoning with LMMs is constrained to either processing fixed user-provided images or reasoning solely through text-based chain-of-thought (CoT). Thinking with Generated Images unlocks a new dimension of cognitive capability where models can actively construct intermediate visual thoughts, critique their own visual hypotheses, and refine them as integral components of their reasoning process. We demonstrate the effectiveness of our approach through two complementary mechanisms: (1) vision generation with intermediate visual subgoals, where models decompose complex visual tasks into manageable components that are generated and integrated progressively, and (2) vision generation with self-critique, where models generate an initial visual hypothesis, analyze its shortcomings through textual reasoning, and produce refined outputs based on their own critiques. Our experiments on vision generation benchmarks show substantial improvements over baseline approaches, with our models achieving up to 50% (from 38% to 57%) relative improvement in handling complex multi-object scenarios. From biochemists exploring novel protein structures, and architects iterating on spatial designs, to forensic analysts reconstructing crime scenes, and basketball players envisioning strategic plays, our approach enables AI models to engage in the kind of visual imagination and iterative refinement that characterizes human creative, analytical, and strategic thinking. We release our open-source suite at https://github.com/GAIR-NLP/thinking-with-generated-images.
LIMO: Less is More for Reasoning
Feb 05, 2025We present a fundamental discovery that challenges our understanding of how complex reasoning emerges in large language models. While conventional wisdom suggests that sophisticated reasoning tasks demand extensive training data (>100,000 examples), we demonstrate that complex mathematical reasoning abilities can be effectively elicited with surprisingly few examples. Through comprehensive experiments, our proposed model LIMO demonstrates unprecedented performance in mathematical reasoning. With merely 817 curated training samples, LIMO achieves 57.1% accuracy on AIME and 94.8% on MATH, improving from previous SFT-based models' 6.5% and 59.2% respectively, while only using 1% of the training data required by previous approaches. LIMO demonstrates exceptional out-of-distribution generalization, achieving 40.5% absolute improvement across 10 diverse benchmarks, outperforming models trained on 100x more data, challenging the notion that SFT leads to memorization rather than generalization. Based on these results, we propose the Less-Is-More Reasoning Hypothesis (LIMO Hypothesis): In foundation models where domain knowledge has been comprehensively encoded during pre-training, sophisticated reasoning capabilities can emerge through minimal but precisely orchestrated demonstrations of cognitive processes. This hypothesis posits that the elicitation threshold for complex reasoning is determined by two key factors: (1) the completeness of the model's encoded knowledge foundation during pre-training, and (2) the effectiveness of post-training examples as "cognitive templates" that show the model how to utilize its knowledge base to solve complex reasoning tasks. To facilitate reproducibility and future research in data-efficient reasoning, we release LIMO as a comprehensive open-source suite at https://github.com/GAIR-NLP/LIMO.
O1 Replication Journey -- Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?
Nov 25, 2024This paper presents a critical examination of current approaches to replicating OpenAI's O1 model capabilities, with particular focus on the widespread but often undisclosed use of knowledge distillation techniques. While our previous work explored the fundamental technical path to O1 replication, this study reveals how simple distillation from O1's API, combined with supervised fine-tuning, can achieve superior performance on complex mathematical reasoning tasks. Through extensive experiments, we show that a base model fine-tuned on simply tens of thousands of samples O1-distilled long-thought chains outperforms O1-preview on the American Invitational Mathematics Examination (AIME) with minimal technical complexity. Moreover, our investigation extends beyond mathematical reasoning to explore the generalization capabilities of O1-distilled models across diverse tasks: hallucination, safety and open-domain QA. Notably, despite training only on mathematical problem-solving data, our models demonstrated strong generalization to open-ended QA tasks and became significantly less susceptible to sycophancy after fine-tuning. We deliberately make this finding public to promote transparency in AI research and to challenge the current trend of obscured technical claims in the field. Our work includes: (1) A detailed technical exposition of the distillation process and its effectiveness, (2) A comprehensive benchmark framework for evaluating and categorizing O1 replication attempts based on their technical transparency and reproducibility, (3) A critical discussion of the limitations and potential risks of over-relying on distillation approaches, our analysis culminates in a crucial bitter lesson: while the pursuit of more capable AI systems is important, the development of researchers grounded in first-principles thinking is paramount.
Halu-J: Critique-Based Hallucination Judge
Jul 17, 2024Large language models (LLMs) frequently generate non-factual content, known as hallucinations. Existing retrieval-augmented-based hallucination detection approaches typically address this by framing it as a classification task, evaluating hallucinations based on their consistency with retrieved evidence. However, this approach usually lacks detailed explanations for these evaluations and does not assess the reliability of these explanations. Furthermore, deficiencies in retrieval systems can lead to irrelevant or partially relevant evidence retrieval, impairing the detection process. Moreover, while real-world hallucination detection requires analyzing multiple pieces of evidence, current systems usually treat all evidence uniformly without considering its relevance to the content. To address these challenges, we introduce Halu-J, a critique-based hallucination judge with 7 billion parameters. Halu-J enhances hallucination detection by selecting pertinent evidence and providing detailed critiques. Our experiments indicate that Halu-J outperforms GPT-4o in multiple-evidence hallucination detection and matches its capability in critique generation and evidence selection. We also introduce ME-FEVER, a new dataset designed for multiple-evidence hallucination detection. Our code and dataset can be found in https://github.com/GAIR-NLP/factool .
ANOLE: An Open, Autoregressive, Native Large Multimodal Models for Interleaved Image-Text Generation
Jul 08, 2024Previous open-source large multimodal models (LMMs) have faced several limitations: (1) they often lack native integration, requiring adapters to align visual representations with pre-trained large language models (LLMs); (2) many are restricted to single-modal generation; (3) while some support multimodal generation, they rely on separate diffusion models for visual modeling and generation. To mitigate these limitations, we present Anole, an open, autoregressive, native large multimodal model for interleaved image-text generation. We build Anole from Meta AI's Chameleon, adopting an innovative fine-tuning strategy that is both data-efficient and parameter-efficient. Anole demonstrates high-quality, coherent multimodal generation capabilities. We have open-sourced our model, training framework, and instruction tuning data.
BeHonest: Benchmarking Honesty of Large Language Models
Jun 19, 2024Previous works on Large Language Models (LLMs) have mainly focused on evaluating their helpfulness or harmlessness. However, honesty, another crucial alignment criterion, has received relatively less attention. Dishonest behaviors in LLMs, such as spreading misinformation and defrauding users, eroding user trust, and causing real-world harm, present severe risks that intensify as these models approach superintelligence levels. Enhancing honesty in LLMs addresses critical deficiencies and helps uncover latent capabilities that are not readily expressed. This underscores the urgent need for reliable methods and benchmarks to effectively ensure and evaluate the honesty of LLMs. In this paper, we introduce BeHonest, a pioneering benchmark specifically designed to assess honesty in LLMs comprehensively. BeHonest evaluates three essential aspects of honesty: awareness of knowledge boundaries, avoidance of deceit, and consistency in responses. Building on this foundation, we designed 10 scenarios to evaluate and analyze 9 popular LLMs on the market, including both closed-source and open-source models from different model families with varied model sizes. Our findings indicate that there is still significant room for improvement in the honesty of LLMs. We also encourage the AI community to prioritize honesty alignment in LLMs. Our benchmark and code can be found at: \url{https://github.com/GAIR-NLP/BeHonest}.
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
Jun 18, 2024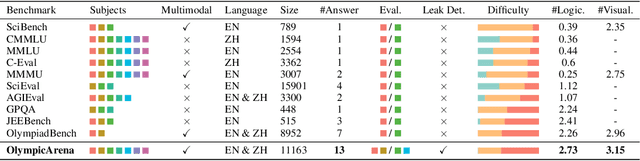
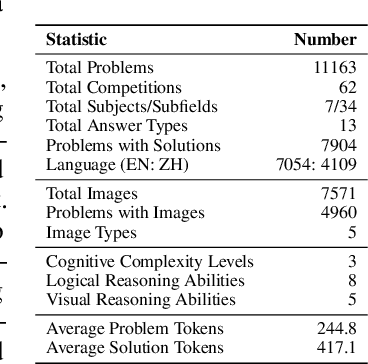
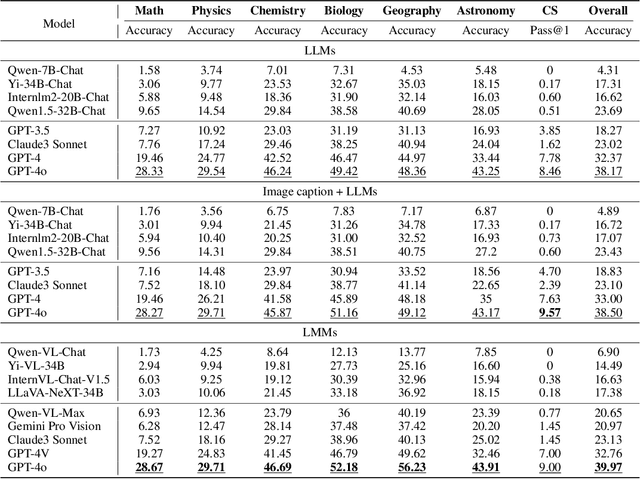
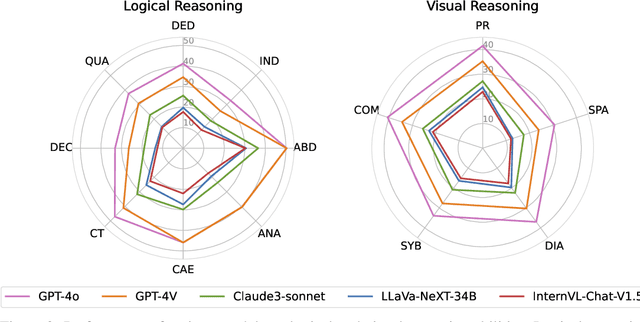
The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration. Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond. We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.