 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Clinical Knowledge Integration for Mammography Report Generation
May 29, 2026Breast cancer is a major global health concern, and mammography screening plays a central role in early detection. The large volume of screening examinations creates a substantial workload for radiologists, making accurate and consistent report generation a critical clinical challenge. Existing automated mammography report generation methods primarily focus on direct visual-to-text mapping, while overlooking the structured clinical reasoning process followed by radiologists in real-world practice. To address this limitation, we propose MammoRG, a mammography report generation framework that explicitly simulates the clinical reporting workflow by following the BI-RADS guideline and incorporating prior clinical knowledge to produce diagnostic reports. Specifically, MammoRG adopts a two-stage training framework. In the first stage, the model learns to integrate clinically relevant prior knowledge from a patient's four-view mammograms through classification-based supervision. In the second stage, a terminology-aware supervised fine-tuning strategy is introduced to model mammography-specific clinical terms as atomic semantic units, enabling the generation of high-quality reports with improved clinical consistency. To facilitate clinical efficacy evaluation of generated reports, we further develop MammoRGTool, a dedicated mammography report parsing tool that extracts structured clinical information from free-text reports. Extensive experiments demonstrate that MammoRG consistently outperforms existing methods across multiple clinical efficacy metrics, particularly in diagnosis-related BI-RADS F1, where it surpasses the second-best model by 2.73%, 2.04%, 1.90%, and 3.27% on the internal, external 1, external 2, and VinDr-Mammo datasets, respectively.
Mobile-Aptus: Confidence-Driven Proactive and Robust Interaction in MLLM-based Mobile-Using Agents
May 27, 2026Recent advancements in multimodal large language models (MLLMs) have shown exceptional potential in enabling mobile-using agents to autonomously execute human instructions. However, fully automated agents often try to execute tasks even when they are unable to resolve them, leading to the problem of over-execution. Previous studies solve it by training a interactive mobile-using agents to let agents request human interaction when agents can not complete user instructions. However, we find that these interactive agents tend to exhibit over-soliciting behavior, relying excessively on human intervention. To mitigate both over-execution and over-soliciting, we propose a universal confidence integration framework that enables confidence-driven proactive and robust interaction in MLLM-based mobile-using agents. The framework consists of two stages: interaction capability empowerment and confidence bias correction. In the interaction capability empowerment stage, agents learn through supervised fine-tuning to output both actions and confidence scores. In the confidence bias correction stage, agents learn to output more accurate confidence scores by combining semantic similarity retrieval with direct preference optimization. Experimental results show Mobile-Aptus achieves state-of-the-art performance on the four popular mobile-using agent benchmarks: OS-Kairos, AITZ, Meta-GUI, and AndroidControl. Mobile-Aptus consistently outperforms all baselines in offline benchmarks, with an average improvement over 17\% in task success rate. In real-world dynamic experiments, Mobile-Aptus surpasses the baseline by 26% in task success rate with only 0.64 intervention steps per instruction. The codes are available at https://github.com/Wuzheng02/Mobile-Aptus.
UI-Venus-1.5 Technical Report
Feb 09, 2026GUI agents have emerged as a powerful paradigm for automating interactions in digital environments, yet achieving both broad generality and consistently strong task performance remains challenging.In this report, we present UI-Venus-1.5, a unified, end-to-end GUI Agent designed for robust real-world applications.The proposed model family comprises two dense variants (2B and 8B) and one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios.Compared to our previous version, UI-Venus-1.5 introduces three key technical advances: (1) a comprehensive Mid-Training stage leveraging 10 billion tokens across 30+ datasets to establish foundational GUI semantics; (2) Online Reinforcement Learning with full-trajectory rollouts, aligning training objectives with long-horizon, dynamic navigation in large-scale environments; and (3) a single unified GUI Agent constructed via Model Merging, which synthesizes domain-specific models (grounding, web, and mobile) into one cohesive checkpoint. Extensive evaluations demonstrate that UI-Venus-1.5 establishes new state-of-the-art performance on benchmarks such as ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%), and AndroidWorld (77.6%), significantly outperforming previous strong baselines. In addition, UI-Venus-1.5 demonstrates robust navigation capabilities across a variety of Chinese mobile apps, effectively executing user instructions in real-world scenarios. Code: https://github.com/inclusionAI/UI-Venus; Model: https://huggingface.co/collections/inclusionAI/ui-venus
VenusBench-GD: A Comprehensive Multi-Platform GUI Benchmark for Diverse Grounding Tasks
Dec 18, 2025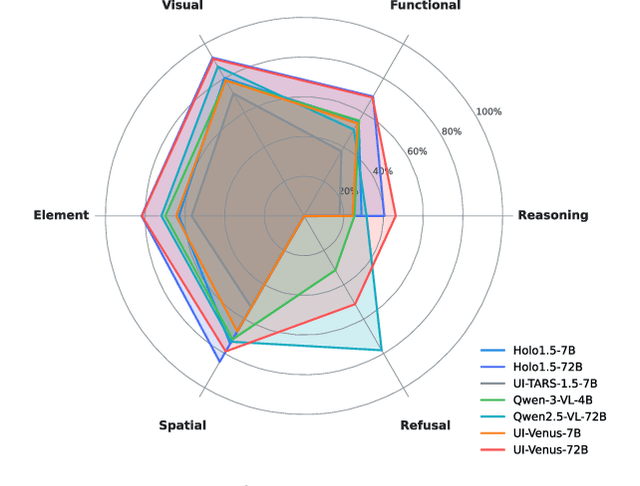
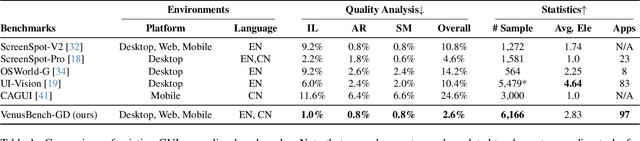
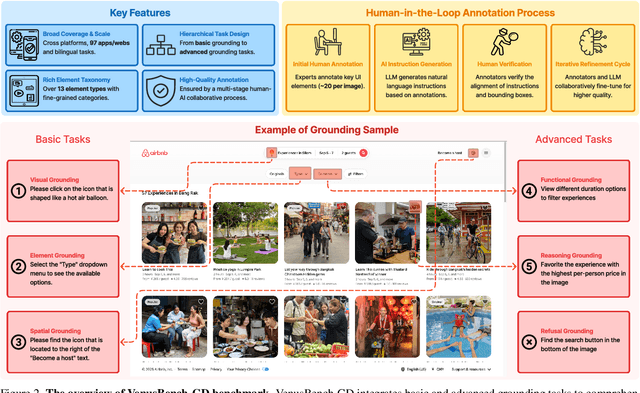
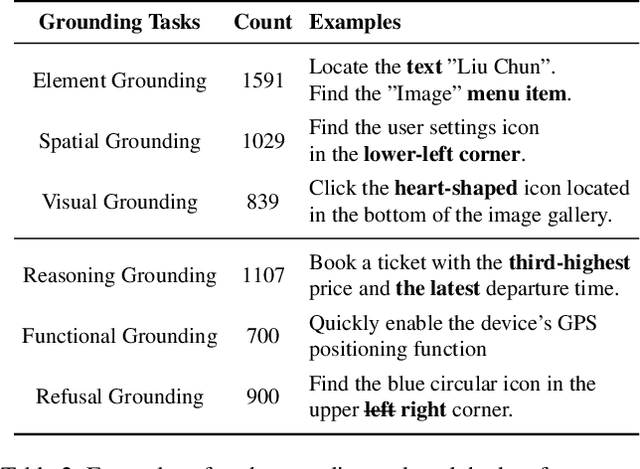
GUI grounding is a critical component in building capable GUI agents. However, existing grounding benchmarks suffer from significant limitations: they either provide insufficient data volume and narrow domain coverage, or focus excessively on a single platform and require highly specialized domain knowledge. In this work, we present VenusBench-GD, a comprehensive, bilingual benchmark for GUI grounding that spans multiple platforms, enabling hierarchical evaluation for real-word applications. VenusBench-GD contributes as follows: (i) we introduce a large-scale, cross-platform benchmark with extensive coverage of applications, diverse UI elements, and rich annotated data, (ii) we establish a high-quality data construction pipeline for grounding tasks, achieving higher annotation accuracy than existing benchmarks, and (iii) we extend the scope of element grounding by proposing a hierarchical task taxonomy that divides grounding into basic and advanced categories, encompassing six distinct subtasks designed to evaluate models from complementary perspectives. Our experimental findings reveal critical insights: general-purpose multimodal models now match or even surpass specialized GUI models on basic grounding tasks. In contrast, advanced tasks, still favor GUI-specialized models, though they exhibit significant overfitting and poor robustness. These results underscore the necessity of comprehensive, multi-tiered evaluation frameworks.
Beamforming for Transmissive RIS Transmitter Enabled Simultaneous Wireless Information and Power Transfer Systems
Nov 15, 2025This paper investigates a novel transmissive reconfigurable intelligent surface (TRIS) transceiver-empowered simultaneous wireless information and power transfer (SWIPT) system with multiple information decoding (ID) and energy harvesting (EH) users. Under the considered system model, we formulate an optimization problem that maximizes the sum-rate of all ID users via the design of the TRIS transceiver's active beamforming. The design is constrained by per-antenna power limits at the TRIS transceiver and by the minimum harvested energy demand of all EH users. Due to the non-convexity of the objective function and the energy harvesting constraint, the sum-rate problem is difficult to tackle. To solve this challenging optimization problem, by leveraging the weighted minimum mean squared error (WMMSE) framework and the majorization-minimization (MM) method, we propose a second-order cone programming (SOCP)-based algorithm. Per-element power constraints introduce a large number of constraints, making the problem considerably more difficult. By applying the alternating direction method of multipliers (ADMM) method, we successfully develop an analytical, computationally efficient, and highly parallelizable algorithm to address this challenge. Numerical results are provided to validate the convergence and effectiveness of the proposed algorithms. Furthermore, the low-complexity algorithm significantly reduces computational complexity without performance degradation.
Resource Allocation for Transmissive RIS Transceiver Enabled SWIPT Systems
Nov 15, 2025



A novel transmissive reconfigurable intelligent surface (TRIS) transceiver-empowered simultaneous wireless information and power transfer (SWIPT) framework is proposed. The sum-rate of the information decoding (ID) users is maximized by optimizing the TRIS transceiver's beamforming, subject to the energy harvesting (EH) users' quality-of-harvest and the per-antenna power constraints. To solve this non-convex problem, we develop an efficient optimization algorithm. First, the original problem is reformulated as a semi-definite programming (SDP) problem. The resulting SDP problem is then addressed using successive convex approximation (SCA) combined with a penalty-based method. Numerical results demonstrate the effectiveness of the algorithm.
Atomic-to-Compositional Generalization for Mobile Agents with A New Benchmark and Scheduling System
Jun 10, 2025Autonomous agents powered by multimodal large language models have been developed to facilitate task execution on mobile devices. However, prior work has predominantly focused on atomic tasks -- such as shot-chain execution tasks and single-screen grounding tasks -- while overlooking the generalization to compositional tasks, which are indispensable for real-world applications. This work introduces UI-NEXUS, a comprehensive benchmark designed to evaluate mobile agents on three categories of compositional operations: Simple Concatenation, Context Transition, and Deep Dive. UI-NEXUS supports interactive evaluation in 20 fully controllable local utility app environments, as well as 30 online Chinese and English service apps. It comprises 100 interactive task templates with an average optimal step count of 14.05. Experimental results across a range of mobile agents with agentic workflow or agent-as-a-model show that UI-NEXUS presents significant challenges. Specifically, existing agents generally struggle to balance performance and efficiency, exhibiting representative failure modes such as under-execution, over-execution, and attention drift, causing visible atomic-to-compositional generalization gap. Inspired by these findings, we propose AGENT-NEXUS, a lightweight and efficient scheduling system to tackle compositional mobile tasks. AGENT-NEXUS extrapolates the abilities of existing mobile agents by dynamically decomposing long-horizon tasks to a series of self-contained atomic subtasks. AGENT-NEXUS achieves 24% to 40% task success rate improvement for existing mobile agents on compositional operation tasks within the UI-NEXUS benchmark without significantly sacrificing inference overhead. The demo video, dataset, and code are available on the project page at https://ui-nexus.github.io.
EVA: Red-Teaming GUI Agents via Evolving Indirect Prompt Injection
May 20, 2025



As multimodal agents are increasingly trained to operate graphical user interfaces (GUIs) to complete user tasks, they face a growing threat from indirect prompt injection, attacks in which misleading instructions are embedded into the agent's visual environment, such as popups or chat messages, and misinterpreted as part of the intended task. A typical example is environmental injection, in which GUI elements are manipulated to influence agent behavior without directly modifying the user prompt. To address these emerging attacks, we propose EVA, a red teaming framework for indirect prompt injection which transforms the attack into a closed loop optimization by continuously monitoring an agent's attention distribution over the GUI and updating adversarial cues, keywords, phrasing, and layout, in response. Compared with prior one shot methods that generate fixed prompts without regard for how the model allocates visual attention, EVA dynamically adapts to emerging attention hotspots, yielding substantially higher attack success rates and far greater transferability across diverse GUI scenarios. We evaluate EVA on six widely used generalist and specialist GUI agents in realistic settings such as popup manipulation, chat based phishing, payments, and email composition. Experimental results show that EVA substantially improves success rates over static baselines. Under goal agnostic constraints, where the attacker does not know the agent's task intent, EVA still discovers effective patterns. Notably, we find that injection styles transfer well across models, revealing shared behavioral biases in GUI agents. These results suggest that evolving indirect prompt injection is a powerful tool not only for red teaming agents, but also for uncovering common vulnerabilities in their multimodal decision making.
Long-term simulation of physical and mechanical behaviors using curriculum-transfer-learning based physics-informed neural networks
Feb 11, 2025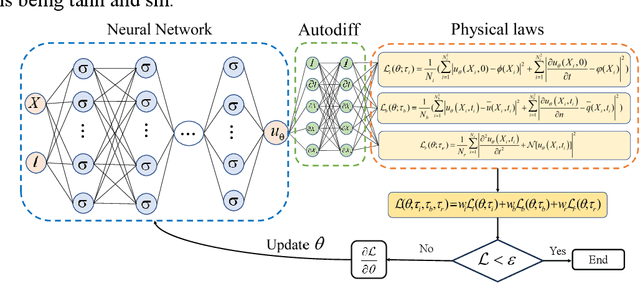
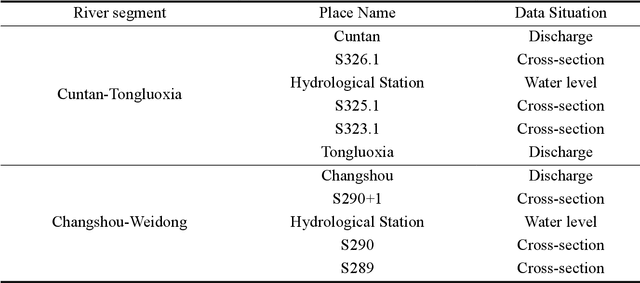
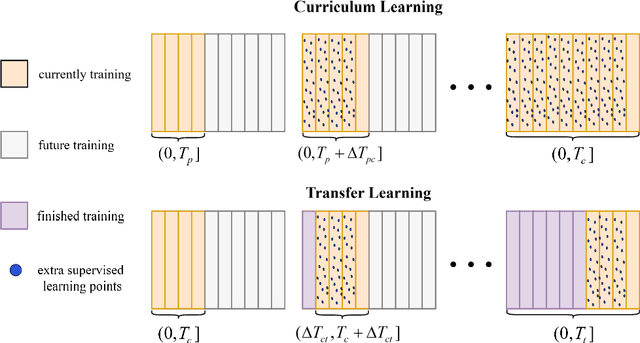

This paper proposes a Curriculum-Transfer-Learning based physics-informed neural network (CTL-PINN) for long-term simulation of physical and mechanical behaviors. The main innovation of CTL-PINN lies in decomposing long-term problems into a sequence of short-term subproblems. Initially, the standard PINN is employed to solve the first sub-problem. As the simulation progresses, subsequent time-domain problems are addressed using a curriculum learning approach that integrates information from previous steps. Furthermore, transfer learning techniques are incorporated, allowing the model to effectively utilize prior training data and solve sequential time domain transfer problems. CTL-PINN combines the strengths of curriculum learning and transfer learning, overcoming the limitations of standard PINNs, such as local optimization issues, and addressing the inaccuracies over extended time domains encountered in CL-PINN and the low computational efficiency of TL-PINN. The efficacy and robustness of CTL-PINN are demonstrated through applications to nonlinear wave propagation, Kirchhoff plate dynamic response, and the hydrodynamic model of the Three Gorges Reservoir Area, showcasing its superior capability in addressing long-term computational challenges.
Movable Antenna Enhanced Networked Full-Duplex Integrated Sensing and Communication System
Nov 14, 2024



Integrated sensing and communication (ISAC) is envisioned as a key technology for future sixth-generation (6G) networks. Classical ISAC system considering monostatic and/or bistatic settings will inevitably degrade both communication and sensing performance due to the limited service coverage and easily blocked transmission paths. Besides, existing ISAC studies usually focus on downlink (DL) or uplink (UL) communication demands and unable to achieve the systematic DL and UL communication tasks. These challenges can be overcome by networked FD ISAC framework. Moreover, ISAC generally considers the trade-off between communication and sensing, unavoidably leading to a loss in communication performance. This shortcoming can be solved by the emerging movable antenna (MA) technology. In this paper, we utilize the MA to promote communication capability with guaranteed sensing performance via jointly designing beamforming, power allocation, receiving filters and MA configuration towards maximizing sum rate. The optimization problem is highly difficult due to the unique channel model deriving from the MA. To resolve this challenge, via leveraging the cutting-the-edge majorization-minimization (MM) method, we develop an efficient solution that optimizes all variables via convex optimization techniques. Extensive simulation results verify the effectiveness of our proposed algorithms and demonstrate the substantial performance promotion by deploying MA in the networked FD ISAC system.