 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding DeepResearch via Reports
Oct 09, 2025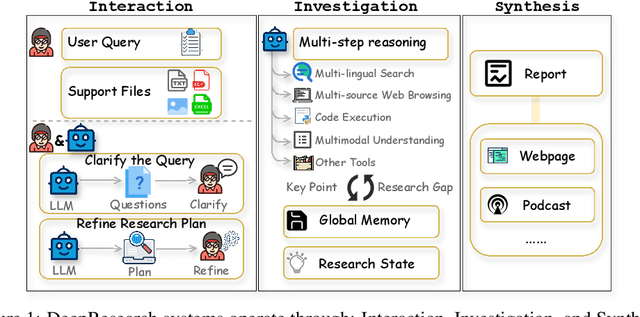

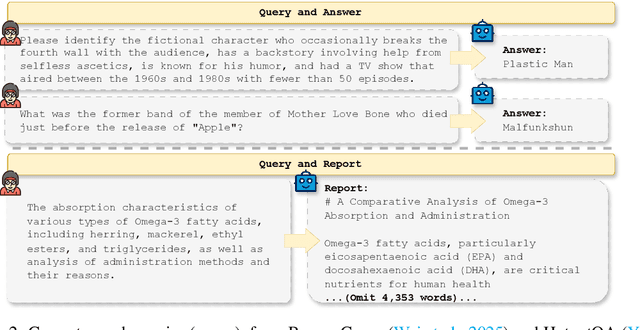

DeepResearch agents represent a transformative AI paradigm, conducting expert-level research through sophisticated reasoning and multi-tool integration. However, evaluating these systems remains critically challenging due to open-ended research scenarios and existing benchmarks that focus on isolated capabilities rather than holistic performance. Unlike traditional LLM tasks, DeepResearch systems must synthesize diverse sources, generate insights, and present coherent findings, which are capabilities that resist simple verification. To address this gap, we introduce DeepResearch-ReportEval, a comprehensive framework designed to assess DeepResearch systems through their most representative outputs: research reports. Our approach systematically measures three dimensions: quality, redundancy, and factuality, using an innovative LLM-as-a-Judge methodology achieving strong expert concordance. We contribute a standardized benchmark of 100 curated queries spanning 12 real-world categories, enabling systematic capability comparison. Our evaluation of four leading commercial systems reveals distinct design philosophies and performance trade-offs, establishing foundational insights as DeepResearch evolves from information assistants toward intelligent research partners. Source code and data are available at: https://github.com/HKUDS/DeepResearch-Eval.
DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments
Apr 07, 2025



Large Language Models (LLMs) equipped with web search capabilities have demonstrated impressive potential for deep research tasks. However, current approaches predominantly rely on either manually engineered prompts (prompt engineering-based) with brittle performance or reinforcement learning within controlled Retrieval-Augmented Generation (RAG) environments (RAG-based) that fail to capture the complexities of real-world interaction. In this paper, we introduce DeepResearcher, the first comprehensive framework for end-to-end training of LLM-based deep research agents through scaling reinforcement learning (RL) in real-world environments with authentic web search interactions. Unlike RAG-based approaches that assume all necessary information exists within a fixed corpus, our method trains agents to navigate the noisy, unstructured, and dynamic nature of the open web. We implement a specialized multi-agent architecture where browsing agents extract relevant information from various webpage structures and overcoming significant technical challenges. Extensive experiments on open-domain research tasks demonstrate that DeepResearcher achieves substantial improvements of up to 28.9 points over prompt engineering-based baselines and up to 7.2 points over RAG-based RL agents. Our qualitative analysis reveals emergent cognitive behaviors from end-to-end RL training, including the ability to formulate plans, cross-validate information from multiple sources, engage in self-reflection to redirect research, and maintain honesty when unable to find definitive answers. Our results highlight that end-to-end training in real-world web environments is not merely an implementation detail but a fundamental requirement for developing robust research capabilities aligned with real-world applications. We release DeepResearcher at https://github.com/GAIR-NLP/DeepResearcher.
O1 Replication Journey -- Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?
Nov 25, 2024This paper presents a critical examination of current approaches to replicating OpenAI's O1 model capabilities, with particular focus on the widespread but often undisclosed use of knowledge distillation techniques. While our previous work explored the fundamental technical path to O1 replication, this study reveals how simple distillation from O1's API, combined with supervised fine-tuning, can achieve superior performance on complex mathematical reasoning tasks. Through extensive experiments, we show that a base model fine-tuned on simply tens of thousands of samples O1-distilled long-thought chains outperforms O1-preview on the American Invitational Mathematics Examination (AIME) with minimal technical complexity. Moreover, our investigation extends beyond mathematical reasoning to explore the generalization capabilities of O1-distilled models across diverse tasks: hallucination, safety and open-domain QA. Notably, despite training only on mathematical problem-solving data, our models demonstrated strong generalization to open-ended QA tasks and became significantly less susceptible to sycophancy after fine-tuning. We deliberately make this finding public to promote transparency in AI research and to challenge the current trend of obscured technical claims in the field. Our work includes: (1) A detailed technical exposition of the distillation process and its effectiveness, (2) A comprehensive benchmark framework for evaluating and categorizing O1 replication attempts based on their technical transparency and reproducibility, (3) A critical discussion of the limitations and potential risks of over-relying on distillation approaches, our analysis culminates in a crucial bitter lesson: while the pursuit of more capable AI systems is important, the development of researchers grounded in first-principles thinking is paramount.
OpenResearcher: Unleashing AI for Accelerated Scientific Research
Aug 13, 2024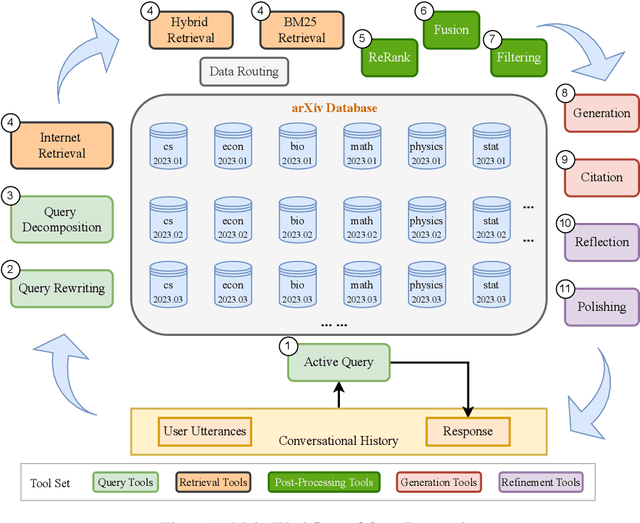
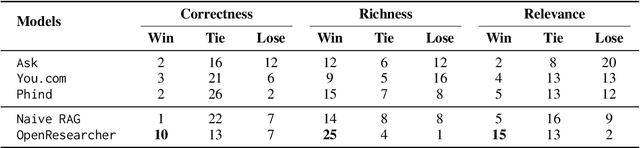
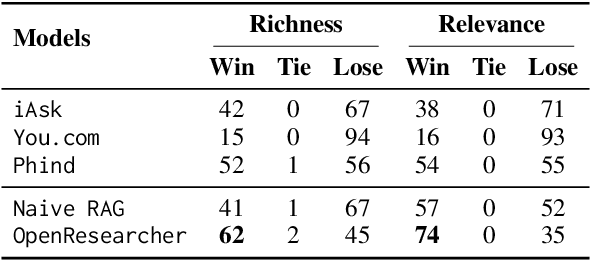
The rapid growth of scientific literature imposes significant challenges for researchers endeavoring to stay updated with the latest advancements in their fields and delve into new areas. We introduce OpenResearcher, an innovative platform that leverages Artificial Intelligence (AI) techniques to accelerate the research process by answering diverse questions from researchers. OpenResearcher is built based on Retrieval-Augmented Generation (RAG) to integrate Large Language Models (LLMs) with up-to-date, domain-specific knowledge. Moreover, we develop various tools for OpenResearcher to understand researchers' queries, search from the scientific literature, filter retrieved information, provide accurate and comprehensive answers, and self-refine these answers. OpenResearcher can flexibly use these tools to balance efficiency and effectiveness. As a result, OpenResearcher enables researchers to save time and increase their potential to discover new insights and drive scientific breakthroughs. Demo, video, and code are available at: https://github.com/GAIR-NLP/OpenResearcher.
SAFETY-J: Evaluating Safety with Critique
Jul 25, 2024The deployment of Large Language Models (LLMs) in content generation raises significant safety concerns, particularly regarding the transparency and interpretability of content evaluations. Current methods, primarily focused on binary safety classifications, lack mechanisms for detailed critique, limiting their utility for model improvement and user trust. To address these limitations, we introduce SAFETY-J, a bilingual generative safety evaluator for English and Chinese with critique-based judgment. SAFETY-J utilizes a robust training dataset that includes diverse dialogues and augmented query-response pairs to assess safety across various scenarios comprehensively. We establish an automated meta-evaluation benchmark that objectively assesses the quality of critiques with minimal human intervention, facilitating scalable and continuous improvement. Additionally, SAFETY-J employs an iterative preference learning technique to dynamically refine safety assessments based on meta-evaluations and critiques. Our evaluations demonstrate that SAFETY-J provides more nuanced and accurate safety evaluations, thereby enhancing both critique quality and predictive reliability in complex content scenarios. To facilitate further research and application, we open-source SAFETY-J's training protocols, datasets, and code at \url{https://github.com/GAIR-NLP/Safety-J}.
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
Jun 18, 2024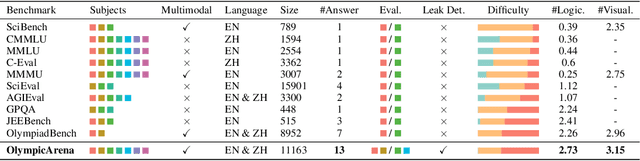
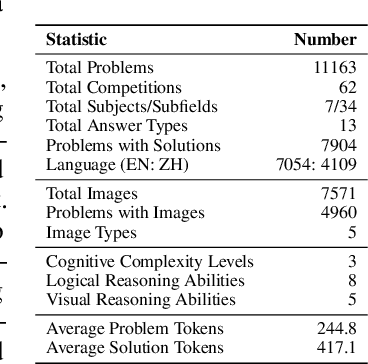
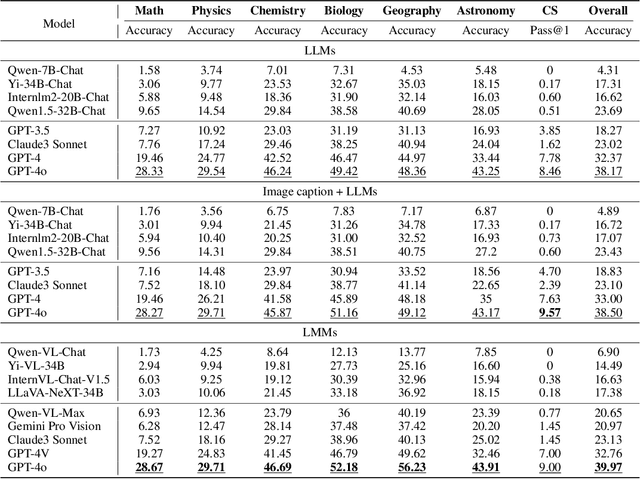
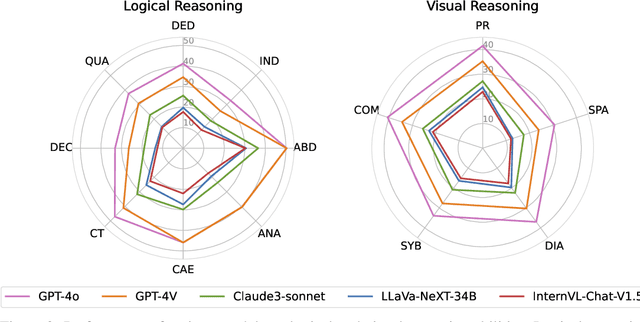
The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration. Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond. We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.
Can We Treat Noisy Labels as Accurate?
May 21, 2024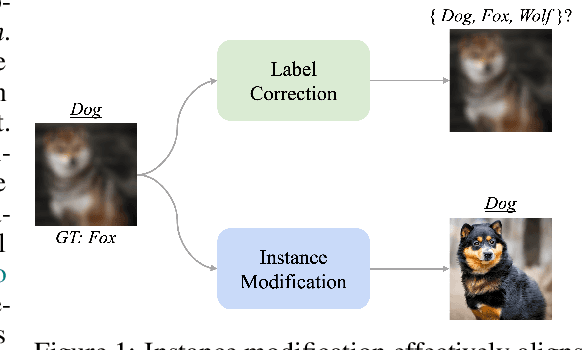
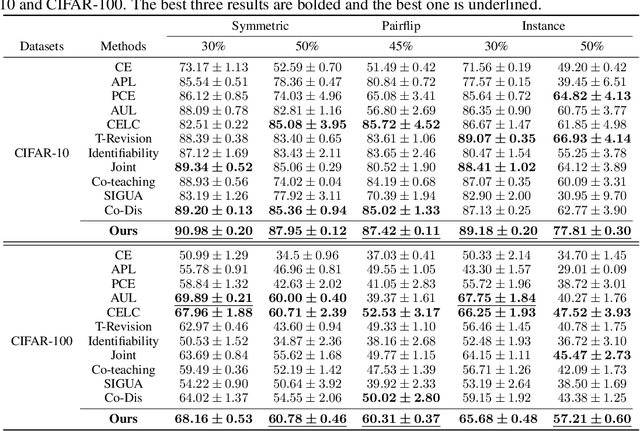
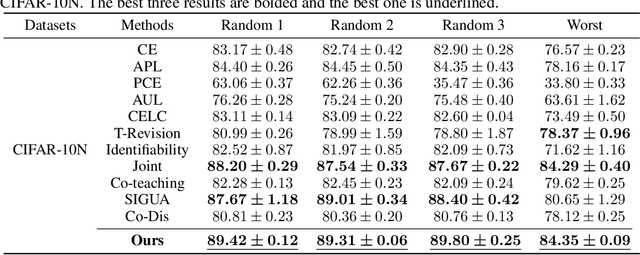
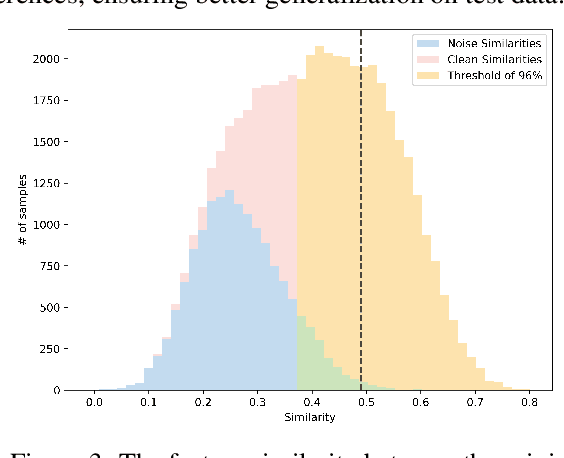
Noisy labels significantly hinder the accuracy and generalization of machine learning models, particularly due to ambiguous instance features. Traditional techniques that attempt to correct noisy labels directly, such as those using transition matrices, often fail to address the inherent complexities of the problem sufficiently. In this paper, we introduce EchoAlign, a transformative paradigm shift in learning from noisy labels. Instead of focusing on label correction, EchoAlign treats noisy labels ($\tilde{Y}$) as accurate and modifies corresponding instance features ($X$) to achieve better alignment with $\tilde{Y}$. EchoAlign's core components are (1) EchoMod: Employing controllable generative models, EchoMod precisely modifies instances while maintaining their intrinsic characteristics and ensuring alignment with the noisy labels. (2) EchoSelect: Instance modification inevitably introduces distribution shifts between training and test sets. EchoSelect maintains a significant portion of clean original instances to mitigate these shifts. It leverages the distinct feature similarity distributions between original and modified instances as a robust tool for accurate sample selection. This integrated approach yields remarkable results. In environments with 30% instance-dependent noise, even at 99% selection accuracy, EchoSelect retains nearly twice the number of samples compared to the previous best method. Notably, on three datasets, EchoAlign surpasses previous state-of-the-art techniques with a substantial improvement.