 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI Act II: Test Time Scaling Drives Cognition Engineering
Apr 21, 2025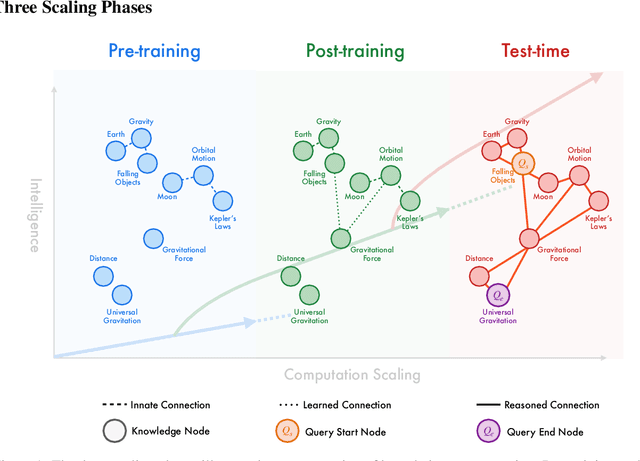
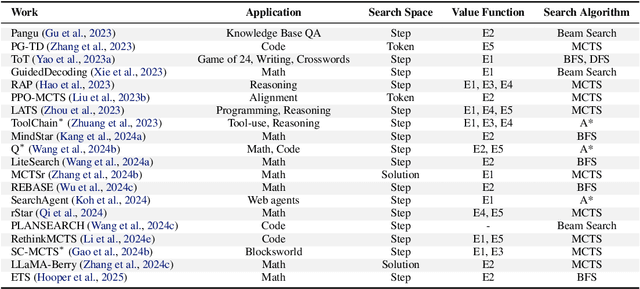
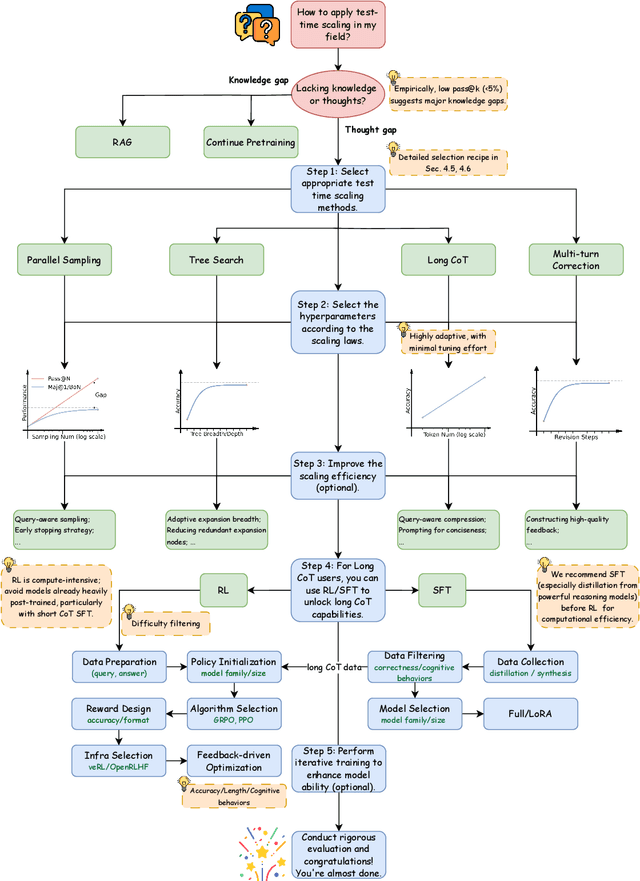
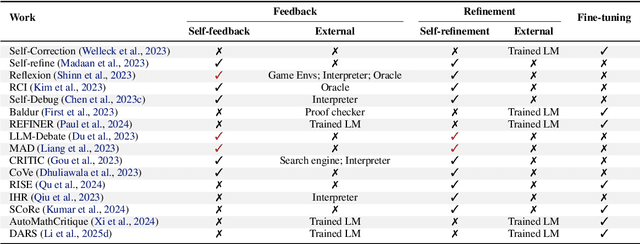
The first generation of Large Language Models - what might be called "Act I" of generative AI (2020-2023) - achieved remarkable success through massive parameter and data scaling, yet exhibited fundamental limitations such as knowledge latency, shallow reasoning, and constrained cognitive processes. During this era, prompt engineering emerged as our primary interface with AI, enabling dialogue-level communication through natural language. We now witness the emergence of "Act II" (2024-present), where models are transitioning from knowledge-retrieval systems (in latent space) to thought-construction engines through test-time scaling techniques. This new paradigm establishes a mind-level connection with AI through language-based thoughts. In this paper, we clarify the conceptual foundations of cognition engineering and explain why this moment is critical for its development. We systematically break down these advanced approaches through comprehensive tutorials and optimized implementations, democratizing access to cognition engineering and enabling every practitioner to participate in AI's second act. We provide a regularly updated collection of papers on test-time scaling in the GitHub Repository: https://github.com/GAIR-NLP/cognition-engineering
ToRL: Scaling Tool-Integrated RL
Mar 30, 2025We introduce ToRL (Tool-Integrated Reinforcement Learning), a framework for training large language models (LLMs) to autonomously use computational tools via reinforcement learning. Unlike supervised fine-tuning, ToRL allows models to explore and discover optimal strategies for tool use. Experiments with Qwen2.5-Math models show significant improvements: ToRL-7B reaches 43.3\% accuracy on AIME~24, surpassing reinforcement learning without tool integration by 14\% and the best existing Tool-Integrated Reasoning (TIR) model by 17\%. Further analysis reveals emergent behaviors such as strategic tool invocation, self-regulation of ineffective code, and dynamic adaptation between computational and analytical reasoning, all arising purely through reward-driven learning.
LIMR: Less is More for RL Scaling
Feb 17, 2025In this paper, we ask: what truly determines the effectiveness of RL training data for enhancing language models' reasoning capabilities? While recent advances like o1, Deepseek R1, and Kimi1.5 demonstrate RL's potential, the lack of transparency about training data requirements has hindered systematic progress. Starting directly from base models without distillation, we challenge the assumption that scaling up RL training data inherently improves performance. we demonstrate that a strategically selected subset of just 1,389 samples can outperform the full 8,523-sample dataset. We introduce Learning Impact Measurement (LIM), an automated method to evaluate and prioritize training samples based on their alignment with model learning trajectories, enabling efficient resource utilization and scalable implementation. Our method achieves comparable or even superior performance using only 1,389 samples versus the full 8,523 samples dataset. Notably, while recent data-efficient approaches (e.g., LIMO and s1) show promise with 32B-scale models, we find it significantly underperforms at 7B-scale through supervised fine-tuning (SFT). In contrast, our RL-based LIMR achieves 16.7% higher accuracy on AIME24 and outperforms LIMO and s1 by 13.0% and 22.2% on MATH500. These results fundamentally reshape our understanding of RL scaling in LLMs, demonstrating that precise sample selection, rather than data scale, may be the key to unlocking enhanced reasoning capabilities. For reproducible research and future innovation, we are open-sourcing LIMR, including implementation of LIM, training and evaluation code, curated datasets, and trained models at https://github.com/GAIR-NLP/LIMR.
O1 Replication Journey -- Part 3: Inference-time Scaling for Medical Reasoning
Jan 11, 2025Building upon our previous investigations of O1 replication (Part 1: Journey Learning [Qin et al., 2024] and Part 2: Distillation [Huang et al., 2024]), this work explores the potential of inference-time scaling in large language models (LLMs) for medical reasoning tasks, ranging from diagnostic decision-making to treatment planning. Through extensive experiments on medical benchmarks of varying complexity (MedQA, Medbullets, and JAMA Clinical Challenges), our investigation reveals several key insights: (1) Increasing inference time does lead to improved performance. With a modest training set of 500 samples, our model yields substantial performance improvements of 6%-11%. (2) Task complexity directly correlates with the required length of reasoning chains, confirming the necessity of extended thought processes for challenging problems. (3) The differential diagnoses generated by our model adhere to the principles of the hypothetico-deductive method, producing a list of potential conditions that may explain a patient's symptoms and systematically narrowing these possibilities by evaluating the evidence. These findings demonstrate the promising synergy between inference-time scaling and journey learning in advancing LLMs' real-world clinical reasoning capabilities.
PC Agent: While You Sleep, AI Works -- A Cognitive Journey into Digital World
Dec 23, 2024



Imagine a world where AI can handle your work while you sleep - organizing your research materials, drafting a report, or creating a presentation you need for tomorrow. However, while current digital agents can perform simple tasks, they are far from capable of handling the complex real-world work that humans routinely perform. We present PC Agent, an AI system that demonstrates a crucial step toward this vision through human cognition transfer. Our key insight is that the path from executing simple "tasks" to handling complex "work" lies in efficiently capturing and learning from human cognitive processes during computer use. To validate this hypothesis, we introduce three key innovations: (1) PC Tracker, a lightweight infrastructure that efficiently collects high-quality human-computer interaction trajectories with complete cognitive context; (2) a two-stage cognition completion pipeline that transforms raw interaction data into rich cognitive trajectories by completing action semantics and thought processes; and (3) a multi-agent system combining a planning agent for decision-making with a grounding agent for robust visual grounding. Our preliminary experiments in PowerPoint presentation creation reveal that complex digital work capabilities can be achieved with a small amount of high-quality cognitive data - PC Agent, trained on just 133 cognitive trajectories, can handle sophisticated work scenarios involving up to 50 steps across multiple applications. This demonstrates the data efficiency of our approach, highlighting that the key to training capable digital agents lies in collecting human cognitive data. By open-sourcing our complete framework, including the data collection infrastructure and cognition completion methods, we aim to lower the barriers for the research community to develop truly capable digital agents.
O1 Replication Journey -- Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?
Nov 25, 2024This paper presents a critical examination of current approaches to replicating OpenAI's O1 model capabilities, with particular focus on the widespread but often undisclosed use of knowledge distillation techniques. While our previous work explored the fundamental technical path to O1 replication, this study reveals how simple distillation from O1's API, combined with supervised fine-tuning, can achieve superior performance on complex mathematical reasoning tasks. Through extensive experiments, we show that a base model fine-tuned on simply tens of thousands of samples O1-distilled long-thought chains outperforms O1-preview on the American Invitational Mathematics Examination (AIME) with minimal technical complexity. Moreover, our investigation extends beyond mathematical reasoning to explore the generalization capabilities of O1-distilled models across diverse tasks: hallucination, safety and open-domain QA. Notably, despite training only on mathematical problem-solving data, our models demonstrated strong generalization to open-ended QA tasks and became significantly less susceptible to sycophancy after fine-tuning. We deliberately make this finding public to promote transparency in AI research and to challenge the current trend of obscured technical claims in the field. Our work includes: (1) A detailed technical exposition of the distillation process and its effectiveness, (2) A comprehensive benchmark framework for evaluating and categorizing O1 replication attempts based on their technical transparency and reproducibility, (3) A critical discussion of the limitations and potential risks of over-relying on distillation approaches, our analysis culminates in a crucial bitter lesson: while the pursuit of more capable AI systems is important, the development of researchers grounded in first-principles thinking is paramount.
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
Jun 18, 2024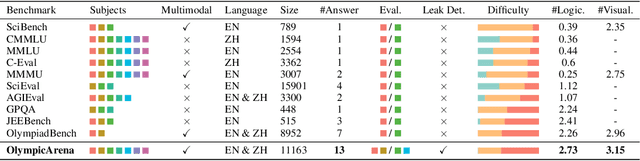
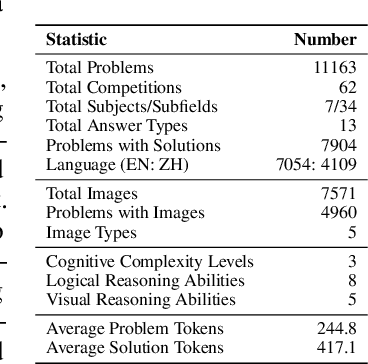
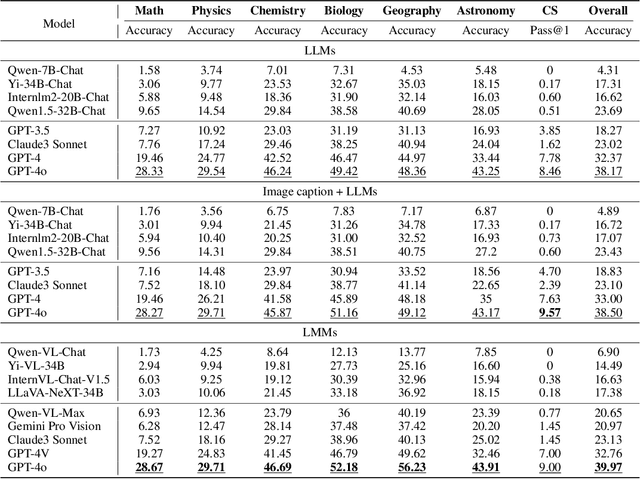
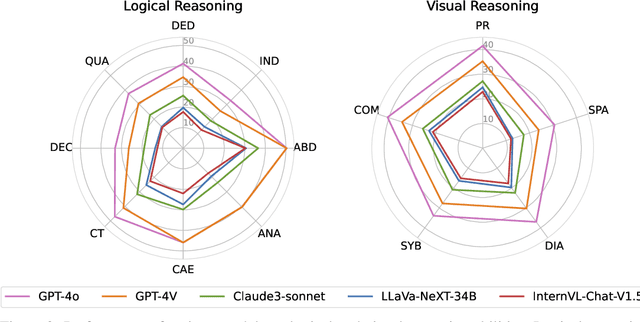
The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration. Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond. We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.
Reformatted Alignment
Feb 19, 2024The quality of finetuning data is crucial for aligning large language models (LLMs) with human values. Current methods to improve data quality are either labor-intensive or prone to factual errors caused by LLM hallucinations. This paper explores elevating the quality of existing instruction data to better align with human values, introducing a simple and effective approach named ReAlign, which reformats the responses of instruction data into a format that better aligns with pre-established criteria and the collated evidence. This approach minimizes human annotation, hallucination, and the difficulty in scaling, remaining orthogonal to existing alignment techniques. Experimentally, ReAlign significantly boosts the general alignment ability, math reasoning, factuality, and readability of the LLMs. Encouragingly, without introducing any additional data or advanced training techniques, and merely by reformatting the response, LLaMA-2-13B's mathematical reasoning ability on GSM8K can be improved from 46.77% to 56.63% in accuracy. Additionally, a mere 5% of ReAlign data yields a 67% boost in general alignment ability measured by the Alpaca dataset. This work highlights the need for further research into the science and mechanistic interpretability of LLMs. We have made the associated code and data publicly accessible to support future studies at https://github.com/GAIR-NLP/ReAlign.